
UC San Diego’s phone-cluster project turns discarded Pixel hardware into a low-carbon compute testbed, with Google support, no disclosed funding amount, and a first market wedge in university workloads that do not need full server-class machines.
A university cloud built from retired phones sounds like a recycling stunt until the workload map comes into focus. Many teaching, grading, notebook, and lightweight research jobs do not need a fresh server. They need enough CPU, memory, Linux compatibility, and orchestration to run predictably at peak demand. That is the opening behind UC San Diego’s phone-cluster computing project, described in a new Google Research post.

The organization at the center is not a venture-backed startup, but the shape of the project will feel familiar to anyone watching climate infrastructure and alternative cloud models. Researchers at the University of California San Diego, with support from Google, plan to deploy a datacenter built from 2,000 retired Pixel smartphones. The goal is to provide hundreds of researchers and students with low-cost, lower-carbon cloud computing by reusing motherboards from consumer phones rather than buying newly manufactured servers.
No funding amount was disclosed. Google is the named strategic supporter, and the project credits a group of Googlers alongside UC San Diego collaborators, including faculty in computer science. That matters because the project is positioned less as a commercial cloud launch and more as a proof point: can discarded consumer hardware be turned into a useful, managed compute layer at campus scale?
The problem starts with the carbon accounting of computing. Operational carbon comes from the electricity used while hardware runs. Cloud providers, universities, and enterprise buyers can reduce some of that through efficiency gains, better utilization, and cleaner power. Embodied carbon is harder. It comes from mining, component fabrication, assembly, shipping, and the rest of the manufacturing chain. Once a device exists, a large part of its climate cost has already been paid.
That makes smartphones an interesting target. People replace phones on roughly four-year cycles, often because the battery, screen, camera, or consumer appeal has aged, not because the processor, memory, storage, and accelerators are useless. A retired phone may be undesirable as a personal device while still being a capable Linux computer. UC San Diego’s bet is that the useful compute should not be trapped inside a drawer, e-waste stream, or low-value resale path.
The technical idea is direct: remove the parts a datacenter does not need and keep the motherboard. A phone motherboard contains the main compute resources, including CPU cores, memory, storage, and accelerators. Google says internal carbon footprinting assessments put the motherboard at roughly 50% of the device’s embodied carbon, which makes it the right part to preserve if the project wants more than symbolic reuse.
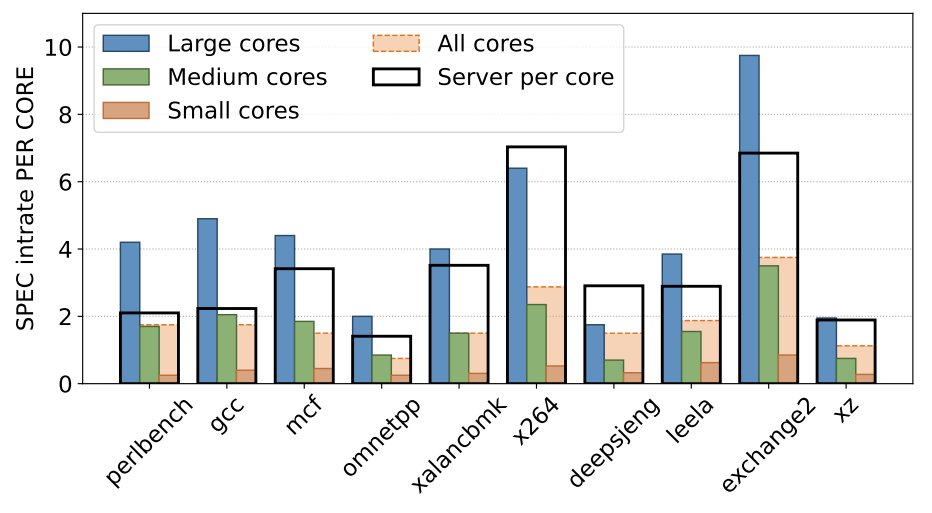
The performance comparison is also more serious than the phrase “old phones” implies. Google’s article compares a 2023 Pixel Fold with an ASUS RS720A-E11 server using the SPEC CPU benchmark suite. On many single-threaded benchmarks, the Pixel Fold’s performance cores beat the per-core performance of the reference server. That does not mean a phone replaces a server by itself. A server has many more cores, far more memory, higher I/O capacity, better thermal design, and enterprise serviceability. The point is narrower and more useful: for small jobs, the phone core is not the weak toy many buyers might assume.
The gap is scale and packaging. A smartphone usually has a handful of heterogeneous cores and about 8GB to 12GB of memory. A modern server can pack dozens of powerful cores and large memory capacity into one managed system. UC San Diego’s design treats phones as clustered building blocks. Google says SPEC results indicate that 25 to 50 phones can equate to a modern server for relevant classes of work. The project plans to organize devices into self-managing clusters in that same 25 to 50 phone range.
The software stack is where the experiment becomes more than hardware reuse. Android already sits on a Linux base, but a phone’s normal software environment is optimized for a consumer device. It includes mobile-specific behavior, background controls, and memory protections that make sense when a person is using apps, but create friction when the hardware is running server workloads. The UC San Diego approach replaces the Android userspace with a general-purpose Linux distribution, then runs containerized workloads managed through Kubernetes.

That choice is practical. Kubernetes gives the project a known control plane for scheduling, health checks, container deployment, and workload management across many small machines. It also makes the cluster legible to developers and researchers who already know cloud-native tooling. The skeptical read is that Kubernetes can add overhead and operational complexity, especially across low-cost hardware never designed for rack deployment. The opportunity-focused read is that using a standard orchestration layer lowers the barrier to making this strange hardware pool useful.
The first target workloads are not AI training runs or high-memory simulations. They are university compute tasks that already run on small cloud instances. Google points to EdTech, grading systems, Jupyter notebooks, and coursework for systems and parallel computation. A grading backend that currently runs on an AWS T3 instance with modest CPU and memory needs is a better fit than a giant GPU job. That positioning is sensible. The project is not trying to beat hyperscale cloud on every dimension. It is looking for workloads where server-grade procurement is more than the job requires.
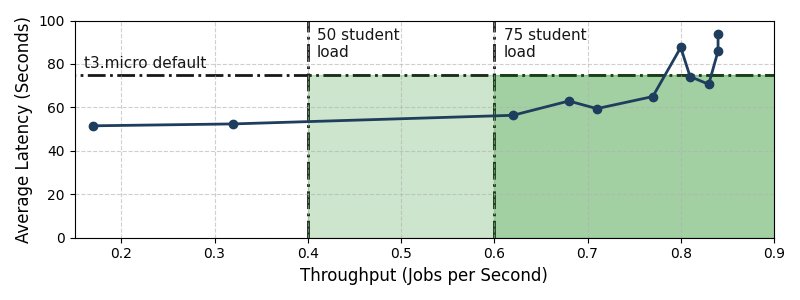
Early traction is strongest in the grading use case. UC San Diego researchers tested a 20-phone cluster running a CPU-intensive matrix multiplication assignment. According to Google, the assignment took about 50 seconds on a single device, and the 20-phone cluster could support peak submission rates for a class of more than 75 students while producing grading latencies below the default AWS backend. That is a concrete signal because grading workloads arrive in bursts, often near deadlines, and students notice latency quickly.
The planned 2,000-phone deployment raises the stakes. Google says it should deliver roughly 50 server-equivalents of compute and could support about 100 such classes at once. It is expected to launch in Fall 2026. If it works, the value proposition is not just lower cost. It is a new supply chain argument for academic and institutional computing: some meaningful share of campus cloud demand may be served by hardware that has already absorbed its manufacturing footprint.
This is where the project brushes against the startup market, even if it is not itself a startup announcement. Alternative cloud providers usually compete on price, specialization, geography, sovereignty, GPUs, or developer experience. Phone-cluster computing points to another axis: embodied-carbon avoidance. That could matter to universities, public agencies, and companies with internal carbon targets, especially for workloads that are latency-tolerant, horizontally scalable, and modest in memory demand.
The market positioning is still narrow. Consumer hardware under sustained datacenter load is a reliability question, not a footnote. Phones were not designed for years of continuous server operation in racks. Power delivery, thermal behavior, flash wear, networking, failure replacement, inventory tracking, firmware maintenance, and security updates all become core infrastructure problems. The batteries are removed because they are unnecessary and potentially unsafe in this environment, but removing parts also turns each phone into a custom node with its own lifecycle.
The operational model also has limits. A cluster of 50 phones may match a server for some aggregate compute tasks, but it does not become one server. Distributed systems have coordination costs. Jobs need to be divided sensibly. Data movement can erase gains if the workload is not shaped for many small nodes. Memory-bound applications, storage-heavy services, and workloads requiring high-bandwidth interconnects are unlikely to be early winners. The project’s strongest fit is embarrassingly parallel or container-friendly work where tasks can be scheduled across independent devices with limited chatter.
That constraint is not a failure. It is the product definition. The most credible climate-tech infrastructure projects tend to start with workloads that fit the physics and economics of the system, rather than claiming every workload will move. UC San Diego’s first wedge, classroom and research support, has three advantages: predictable users, known software patterns, and real pressure to reduce cloud spend. It also gives researchers a live testbed for measuring failure rates, maintenance costs, scheduling behavior, and carbon savings with more honesty than a lab demo can provide.
Google’s role is also worth reading carefully. The company is not presenting this as a new Google Cloud SKU. It is supporting university research and tying the project to its broader Consumer Hardware Carbon Reduction Guide. That keeps the commercial promise modest, but it also gives the work credibility through access to Pixel hardware knowledge, carbon analysis, and systems expertise.
The most interesting outcome may not be a world where retired phones replace servers at large scale. A more plausible outcome is a new category of second-life compute for specific institutional workloads. If UC San Diego can show that 2,000 phones can be operated safely, cheaply, and usefully across real classes and research jobs, it gives other universities and hardware makers a pattern to copy. If reliability or operations costs swamp the savings, that will be useful data too.
For now, the project sits in a productive middle ground: ambitious enough to matter, constrained enough to test. It asks whether the cloud has to begin with newly manufactured machines for every small job. The answer will depend less on the charm of reused phones and more on the unglamorous metrics that decide infrastructure adoption: uptime, maintenance hours, workload fit, cost per job, and carbon avoided per useful compute cycle.
Comments
Please log in or register to join the discussion