Google researchers have developed a novel training approach that teaches LLMs to approximate Bayesian reasoning by learning from an optimal Bayesian system's predictions, significantly improving their ability to update beliefs during multi-step interactions.
Google researchers have developed a novel training method that teaches large language models to approximate Bayesian reasoning by learning from the predictions of an optimal Bayesian system. The approach focuses on improving how models update beliefs as they receive new information during multi-step interactions.
The Challenge of Belief Updates in LLMs
In many real-world applications, such as recommendation systems, models need to infer user preferences gradually based on new information. Bayesian inference provides a mathematical framework for updating probabilities as new evidence becomes available. However, most language models struggle with this fundamental aspect of reasoning.
The researchers investigated whether language models behave in ways consistent with Bayesian belief updates and explored training methods to improve that behavior. As software developer Yann Kronberg noted in community reactions, "People talk about reasoning benchmarks but this is basically about belief updates. We know that most LLMs don't revise their internal assumptions well after new information arrives, so @GoogleResearch teaching them to approximate Bayesian inference could matter a lot for long-running agents."
Experimental Setup: Flight Recommendation Task
The team created a simulated flight recommendation task to evaluate this. In the experiment, a model interacted with a simulated user for five rounds. In each round, the assistant and user were shown three flight options defined by departure time, duration, number of stops, and price. Each simulated user had hidden preferences for these attributes.
After each recommendation, the user indicated whether the assistant selected the correct option and revealed the preferred flight. The assistant was expected to use this feedback to improve future recommendations.
Comparing Models with Bayesian Assistant
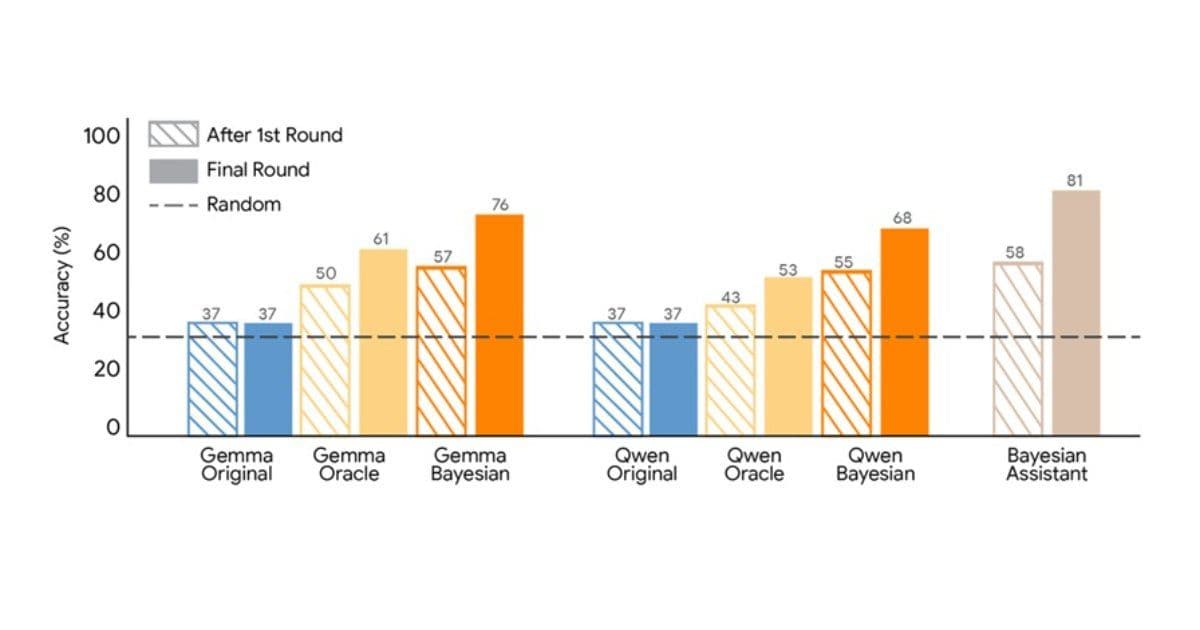
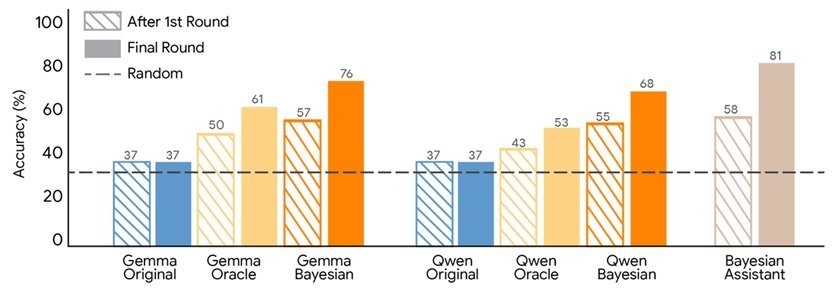
The researchers compared several language models with a Bayesian assistant that maintains a probability distribution over possible user preferences and updates it using Bayes' rule after each interaction. In the experiment, the Bayesian assistant reached about 81% accuracy in selecting the correct option.
Language models performed worse and often showed limited improvement after the first interaction, suggesting that they did not effectively update their internal estimates of user preferences. This limitation highlights a fundamental gap between current LLM capabilities and the probabilistic reasoning required for many sequential decision-making tasks.
Bayesian Teaching: Learning from Optimal Predictions
The study then tested a training approach called Bayesian teaching. Instead of learning only from correct answers, models were trained to imitate the predictions of the Bayesian assistant during simulated interactions. In early rounds, the Bayesian assistant sometimes made incorrect recommendations due to uncertainty about the user's preferences, but its decisions reflected probabilistic reasoning based on the available evidence.
The image below shows the recommendation accuracy of Gemma and Qwen after fine-tuning on user interactions with the Bayesian assistant or with an oracle.
Results and Implications
The training data for supervised fine-tuning consisted of simulated conversations between users and the Bayesian assistant. For comparison, the researchers tested a method in which the model learned from an assistant that always selected the correct option because it had perfect knowledge of the user's preferences.
Both fine-tuning approaches improved model performance, but Bayesian teaching produced better results. Models trained with this method made predictions that more closely matched those of the Bayesian assistant and demonstrated stronger improvement across multiple interaction rounds. The trained models also showed higher agreement with the Bayesian system when evaluating user choices.
Researcher Aidan Li raised an interesting question about the methodology: "Why did the authors use SFT instead of RL to train the model to approximate probabilistic inference? There is a wealth of work relating RL and probabilistic inference, even for LLMs. Maybe I'm missing something but RL seems like the obvious choice."
Model Distillation Approach
The researchers describe the method as a form of model distillation in which a neural network learns to approximate the behavior of a symbolic system implementing Bayesian inference. This approach bridges the gap between symbolic reasoning systems and neural network architectures.
The results suggest that language models can acquire probabilistic reasoning skills through post-training that demonstrates optimal decision strategies during sequential interactions. This has significant implications for applications requiring multi-turn reasoning, such as personal assistants, recommendation systems, and autonomous agents.
Technical Significance
This research addresses a fundamental limitation in current LLM architectures: their inability to maintain and update probabilistic beliefs over time. By teaching models to approximate Bayesian reasoning, the researchers have created a pathway for more sophisticated sequential decision-making in AI systems.
The approach could be particularly valuable for long-running agents that need to maintain context and update their understanding based on ongoing interactions. As AI systems become more integrated into complex workflows, the ability to reason probabilistically and update beliefs becomes increasingly critical.
Future Directions
The success of Bayesian teaching opens several avenues for future research. The method could be extended to other domains beyond recommendation systems, such as medical diagnosis, financial planning, or educational tutoring. Additionally, exploring alternative training approaches like reinforcement learning, as suggested by Aidan Li, could yield even better results.
The research also raises questions about the scalability of this approach to larger, more complex reasoning tasks and whether similar techniques could be applied to other forms of symbolic reasoning beyond Bayesian inference.
Community Impact
Community reactions to the Google Research post were largely positive, with commenters highlighting improved probabilistic reasoning and multi-turn adaptation in LLMs. The work represents a significant step toward making language models more capable of the kind of reasoning that humans use naturally when updating their beliefs based on new evidence.
As AI systems continue to evolve, approaches like Bayesian teaching may become essential for creating models that can reason effectively over extended interactions and complex, uncertain environments.
Comments
Please log in or register to join the discussion