New benchmarks reveal surprising performance gaps between programming languages when used with AI code generation tools, challenging conventional wisdom about training data volume and language design principles.
The world of software development is undergoing a quiet revolution, not just in how we write code, but in which programming languages prove most effective when paired with artificial intelligence. Recent benchmark results are revealing unexpected truths about language design that could reshape the future of software engineering.
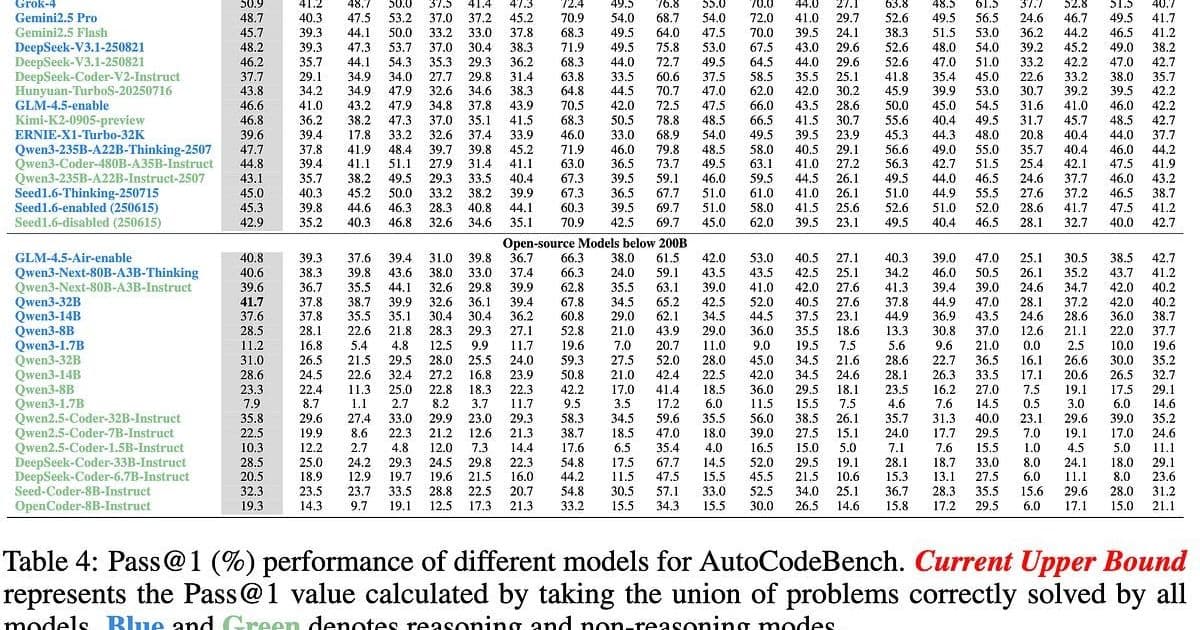
When we consider AI-assisted coding, most developers assume languages with vast training corpora would naturally perform best. However, AutoCodeBench—a comprehensive testing framework evaluating performance across 20 different programming languages—tells a different story. The results show Python and JavaScript, despite their enormous training datasets, consistently rank among the lowest performers. Meanwhile, languages like Elixir, Kotlin, Racket, and C# achieve top marks, often with significantly less training data available.
This paradox reveals something fundamental about how AI models interact with code structure. The amount of training data matters less than we thought. Instead, what appears critical is how well a language's design aligns with the strengths of current AI systems: pattern matching, explicit structure, and local context visibility.
"The amount of training data doesn't matter as much as we thought. Functional paradigms transfer well. Structure beats volume. JavaScript has the training data but fights the architecture. Elixir has less data but flows with it," observes Greg Olsen in his recent analysis.
The implications extend beyond mere benchmark scores. They speak to a fundamental shift in how we think about programming languages and their relationship to human cognition and machine capabilities.
Tesla's approach to self-driving offers an instructive parallel. While competitors bolted expensive LIDAR sensors to their vehicles, Tesla bet on computer vision alone. This seemingly naive approach made sense when considering who built our roads: humans. Roads aren't randomly chaotic—they follow visual grammar developed over a century of human transportation. Color-coded lights, painted lines, standardized signs—all create a system optimized for human visual perception.
Similarly, programming languages may be evaluated by how well they align with the "load-bearing interfaces" of software development. For decades, we've optimized languages for human writing—objects with identity and state that mirror how we experience reality. But perhaps we've been optimizing for the wrong bottleneck.
"The bottleneck was never creation. It was always verification," Olsen suggests. "Grace Hopper originally envisioned the translation layer moving directly from English to machine code. 75 years later, we're finally able to work with her original vision. 'Programs must be written for people to verify, and only incidentally for machines to execute.'"
This perspective repositions programming languages not as tools for expressing human thought processes, but as bridges between human intent and machine execution. The most effective languages may be those that minimize the cognitive distance between specification and verification.
Consider the cognitive differences between humans and AI models. Humans remember in episodes and narratives—we evolved to track animals moving behind rocks, to maintain mental models of objects out of sight, and to construct mental movies of cause and effect. This natural inclination explains why we gravitate toward if-then statements and programming constructs that read like plots.
LLMs, by contrast, have no such "movies" playing in their "heads." They excel at pattern matching across large corpora, handle declared structure well, and reason effectively within constrained contexts. They struggle with narrative consistency and maintaining large amounts of state—precisely the challenges humans face when debugging complex stateful applications.
This cognitive mismatch helps explain why JavaScript and Python struggle with AI code generation. Three hours into debugging a React component, developers often find themselves five layers deep in a stack trace that offers little clarity. The error might be in useEffect—but which one? The one that fires on mount, update, or whenever state changes except when it doesn't because the dependency array is misleading? Debugging becomes archaeology on one's own recent work.
In contrast, Elixir's functional approach creates an environment where complexity cannot hide. Functions are pure—given the same input, they always return the same output. Data is immutable. Pattern matching makes data shapes explicit. Multiple function heads create very clear local context. While such an approach may feel "weird" to humans accustomed to object-oriented thinking, it creates code that's remarkably easy to verify.
The advantages extend beyond individual functions to the entire ecosystem. Elixir maintains one build system, one format option, and one library for Enums and Collections. Naming conventions are predictable. Simplicity is a clear, enforced value. This consistency means LLMs trained on Elixir encounter repeated patterns rather than a thousand variations of the same concept.
"Elixir maximizes the amount of program meaning visible in local context. And LLMs are context machines," Olsen notes.
This brings us back to Kernighan's Law: "Debugging is twice as hard as writing the code in the first place." When we write complicated state machines, we struggle to debug them because we reach the edges of our cognitive capacity. LLMs offer a way out—not by writing incomprehensible code, but by thriving in languages designed for clarity and explicitness.
The future of software engineering may involve a clear division of labor: LLMs will write, debug, and manage edge cases while humans focus on specification, verification, and intervention when things go wrong. This approach requires clear contracts, explicit effects, testable properties, auditable logic, and composable pieces—all functional programming virtues that also make formal verification possible.
"LLMs have arrived and showed us which languages are actually well-designed. The AutoCodeBench tests are a message: the 'hard' languages were never hard. They were just waiting for a mind that didn't need movies," Olsen concludes.
As AI continues to evolve, programming languages that prioritize explicitness, immutability, and local context visibility will likely gain prominence—not because they're easier for humans to write, but because they're easier for both humans and machines to verify. In this new paradigm, the most valuable programming languages may be those that embrace simplicity over familiarity, structure over narrative, and verification over expression.
Comments
Please log in or register to join the discussion