Your INSERT statement returns success in milliseconds, but the data isn't in its permanent home yet. Here's the memory-and-logging trick every relational database uses to stay fast without losing your writes, and the consistency trade-offs that come with it.
You write an INSERT statement, hit execute, and the database returns success almost instantly. It's tempting to picture that row immediately slotted into its permanent place on disk, indexes updated, files synced. That mental model is wrong, and understanding why explains a surprising amount about database performance, crash recovery, and the consistency guarantees you actually get.
If a database paused on every insert to locate the right data file, find the exact page, update every index, and flush all of it to disk, throughput would collapse. Random disk writes are expensive. A single insert touching a table and three indexes could mean four separate seeks to scattered locations on the drive. Multiply that by thousands of transactions per second and the disk becomes the bottleneck that defines your entire system's ceiling.
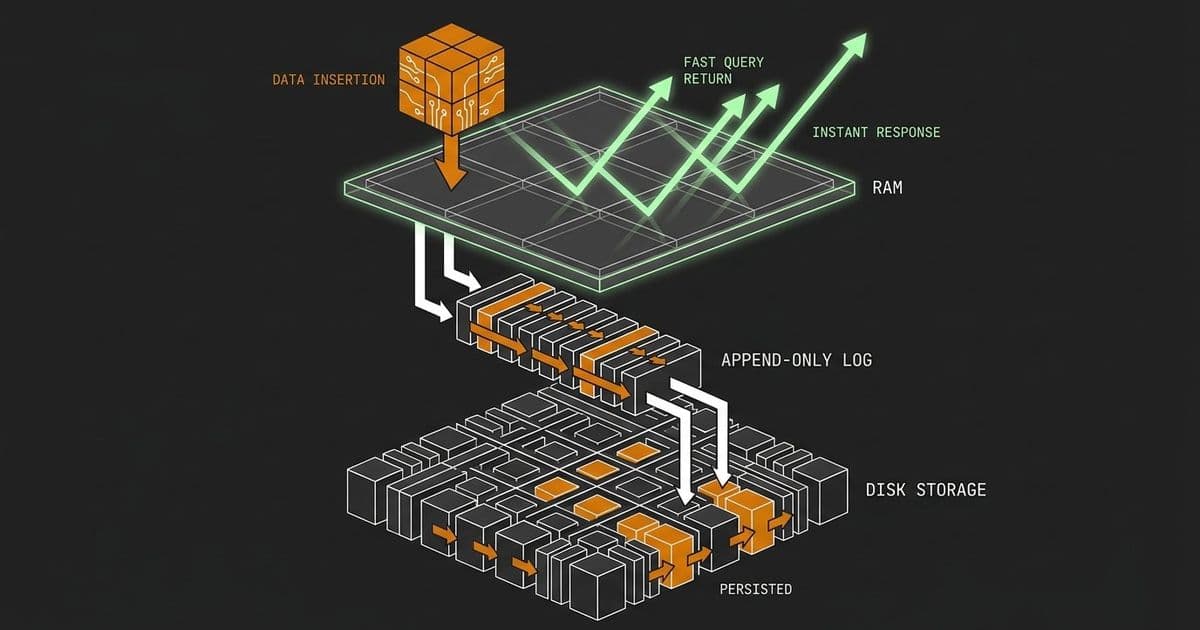
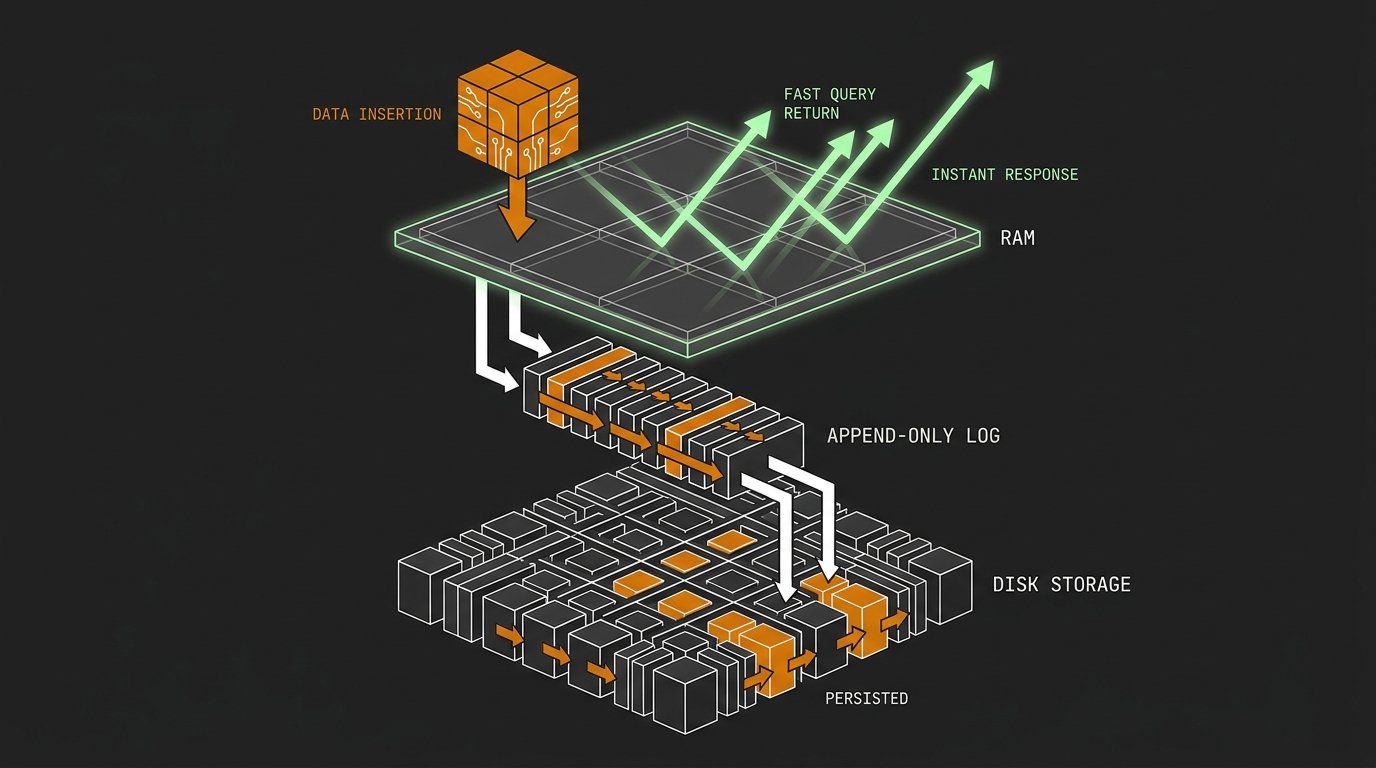
Databases solve this with two components working together: an in-memory cache called the buffer pool, and an append-only file on disk called the Write-Ahead Log. The combination lets the database acknowledge your write almost immediately while still guaranteeing it survives a crash.
The problem: durability and speed pull in opposite directions
There are two non-negotiable requirements on the write path, and they conflict.
First, the write has to be fast. Users wait on it. An API request blocks on it. If acknowledgment takes 20 milliseconds because the engine is seeking across the disk, that latency propagates up through every layer of your application.
Second, the write has to be durable. Once the database tells your application the insert succeeded, that data must survive a power loss or process crash. Anything held only in RAM disappears the moment the server loses power. So the naive fast path, keeping everything in memory and acknowledging immediately, violates durability outright.
The trick is recognizing that durability does not require writing data to its final, organized home on disk. It only requires writing it somewhere durable, in whatever form is cheapest to write.
The solution: cache in RAM, log sequentially
When you run an insert, the database does two things before it acknowledges:
- It writes the new record into the buffer pool, a region of RAM the engine reserves for caching table and index pages.
- It appends a record of the change to the Write-Ahead Log, a sequential file on disk.
Only after the WAL write is safely on disk does the database return success. The actual data table, the permanent organized structure, gets updated later by a background process, often seconds or minutes after acknowledgment.
Here is the full lifecycle of an inserted row:
| Step | Component | Action | Location |
|---|---|---|---|
| 1 | Query | Application sends the insert request | Network |
| 2 | Buffer Pool | Engine caches the new record in memory | RAM |
| 3 | Write-Ahead Log | Engine appends the change to the sequential log | Disk |
| 4 | Acknowledgment | Engine signals success to the application | Network |
| 5 | Background Flush | Engine moves data from buffer pool to the data table | Disk |
The ordering in steps 2 and 3 is where the name Write-Ahead Log comes from: the log is written ahead of the data file modification. The change is recorded in the log before it is ever applied to the table's permanent pages.
Why the buffer pool is fast
The buffer pool is just RAM allocated to the database engine for caching table and index data. RAM access runs orders of magnitude faster than disk, even fast NVMe SSDs. When your record lands in the buffer pool, it is immediately available for reads, updates, or further manipulation with zero disk I/O on the critical path.
This is also why most reads never touch the data file. When you query a row, the engine checks the buffer pool first. If the page is cached, and on a warm system it usually is, the read is served entirely from memory. In practice the overwhelming majority of read queries against a busy database are answered from the buffer pool, not from disk.
This has a direct consequence for the read-after-write case. Insert a new user profile, then immediately redirect to a dashboard that runs a SELECT for that user. The permanent data table on disk may have no idea the user exists yet. The engine returns the row from the buffer pool, which holds the authoritative most-recent copy. The cache is not a stale shadow of the truth; until the background flush runs, it is the truth.

Why the WAL is fast
Writing to the main data table means random writes: seeking to specific pages scattered across the file, updating each one in place. Writing to the WAL means appending to the end of one file, a sequential write. Sequential disk writes are dramatically cheaper than random ones, even on SSDs where the gap is narrower than on spinning disks but still real because of how the storage layer batches and commits.
So the WAL gives durability at close to the cost of a single append, instead of the cost of fully reorganizing on-disk structures. The database considers your data safe the instant the log write is flushed. The expensive work of placing the row into its final home, updating indexes, and reclaiming space happens asynchronously, batched, and out of the user's critical path.
Crash recovery: where the WAL earns its keep
The payoff shows up when the server dies. Suppose acknowledged writes are sitting in the buffer pool, applied to the log but not yet flushed to the data table, and the process crashes or the machine loses power. RAM is gone. The data table on disk is missing those rows.
On restart, the engine reads the WAL as part of its recovery sequence. It replays the logged transactions, reconstructing the state that existed at the moment of the crash and reapplying any changes the data table never received. Nothing acknowledged is lost. This replay-from-log mechanism is what lets a database promise ACID durability without paying the random-write cost on every transaction.
This pattern is nearly universal. PostgreSQL calls it the WAL. MySQL's InnoDB engine uses a redo log that serves the same role. SQL Server has its transaction log. The terminology differs, the principle does not: record the intent to change durably and sequentially, apply the change to permanent structures lazily.
The trade-offs
This design is not free, and the costs are worth naming because they shape how you operate a database.
Flush tuning is a durability-versus-throughput dial. You can configure how aggressively the engine flushes the WAL and how often background checkpoints move data to the table. Flush on every commit and you get the strongest durability with the highest per-transaction cost. Relax the flush interval and you gain throughput but widen the window where an acknowledged write could be lost in a crash, depending on the exact setting. PostgreSQL's synchronous_commit and InnoDB's innodb_flush_log_at_trx_commit both expose this trade-off directly.
The WAL is a write amplification source. Every change is written at least twice: once to the log, once eventually to the data file. This is the price of the design and it is usually worth paying, but it matters for write-heavy workloads and for storage planning.
Recovery time scales with unflushed log volume. A long checkpoint interval means more WAL to replay on restart, which means longer recovery. Tuning checkpoints trades steady-state I/O smoothness against crash recovery duration.
You generally cannot bypass the buffer pool. Forcing synchronous direct writes to the data table on every transaction is possible to approximate through configuration, but it reintroduces exactly the random-I/O cost the architecture exists to avoid. The result is correctness you already had with a large performance regression.
The broader pattern here extends well beyond single-node databases. Append-a-durable-log-first, apply-to-state-later is the same idea behind replication logs, event sourcing, and the commit logs that systems like Kafka are built around. Once you see the WAL clearly, you start recognizing the shape everywhere distributed systems need to be both fast and crash-safe. The log is the source of truth; the materialized structures are a convenient, rebuildable projection of it.
That reframing is the useful takeaway. The success message your INSERT returns is not a claim that the data sits in its final table. It is a promise that the change has been durably recorded and will end up there. For almost every application, that promise is exactly what you want, and the few percent of cases where the distinction matters are precisely the ones where understanding this machinery saves you.
Comments
Please log in or register to join the discussion