Meta's engineering team recently completed a massive migration of their petabyte-scale MySQL data ingestion platform, replacing fragmented infrastructure with a centralized system while maintaining zero downtime through innovative techniques like reverse shadowing and continuous checksum monitoring.
How Meta Rebuilt Data Ingestion for Petabyte-Scale Reliability
Meta's engineering team has successfully completed a monumental migration of their data ingestion platform, which handles several petabytes of MySQL social graph data daily. This transition represents one of the largest-scale data infrastructure migrations in the tech industry, moving from fragmented, pipeline-owned infrastructure to a centralized, self-managed warehouse service while maintaining complete operational continuity.
The Challenge: Migrating at Unprecedented Scale
Meta operates one of the world's largest MySQL deployments, with a data ingestion platform that supports critical analytics, reporting, machine learning, and internal product development workloads. The existing infrastructure consisted of thousands of fragmented, pipeline-owned ingestion systems that had grown organically over time, creating operational inefficiencies and reliability challenges.
"Migrating data ingestion at Meta scale isn't an upgrade. It's open-heart surgery on core business," commented Syed Moeen Kazmi. "The challenge isn't just moving data, it's maintaining consistency and zero downtime."
The team needed to replace this complex, distributed system with a centralized managed service while ensuring that downstream analytics and ML workloads remained unaffected throughout the transition. This required not only technical innovation but also sophisticated change management across hundreds of internal teams.
The Migration Strategy: Zero-Downtime Transition
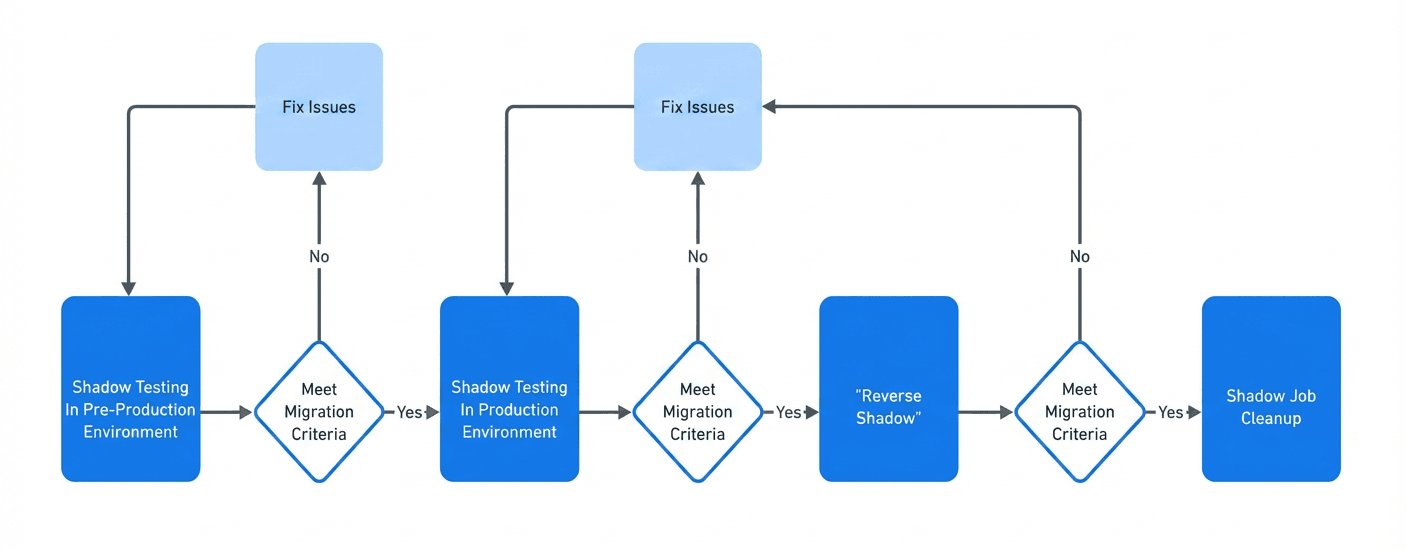
Meta's approach to this massive migration was methodical and risk-averse, employing a three-stage process that allowed for thorough validation at each step:
1. Shadow Phase
During the initial phase, the team deployed new ingestion jobs in parallel with existing production systems. These "shadow jobs" processed the same production data but didn't feed into the actual data warehouse. This allowed the team to:
- Validate the new system's correctness against production workloads
- Identify and fix issues in a non-production environment
- Measure resource requirements for the new system
- Continuously monitor row count and checksum mismatches between production and shadow jobs
"We continuously monitored row count and checksum mismatches between the production jobs and the shadow jobs," explained Zihao Tao, software engineer at Meta. "When mismatches occurred, we quickly investigated the root cause and deployed fixes to the pre-production environment, then verified that the mismatch was resolved."
2. Reverse Shadow Phase
Once confidence was established in the shadow system, Meta executed the most critical phase of the migration: the reverse shadow. This innovative technique involved:
- Swapping production ownership from legacy to new systems
- Maintaining rollback capabilities throughout the transition
- Preserving the ability to quickly revert to legacy systems if issues arose
This phase was particularly challenging because it required maintaining both systems simultaneously while ensuring data consistency across both. The team implemented sophisticated monitoring to detect any discrepancies immediately.
3. Cleanup Phase
The final phase involved retiring the legacy infrastructure after confirming:
- Complete consistency between old and new systems
- Performance parity or improvement
- No impact on downstream consumers
Technical Implementation: CDC Architecture and Validation
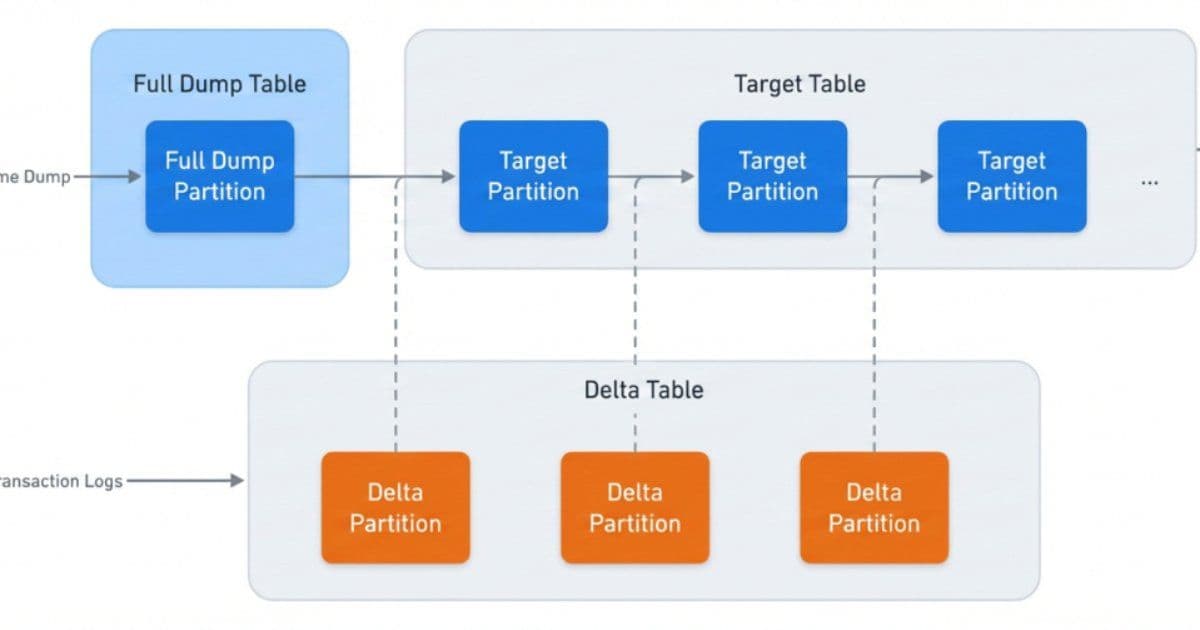
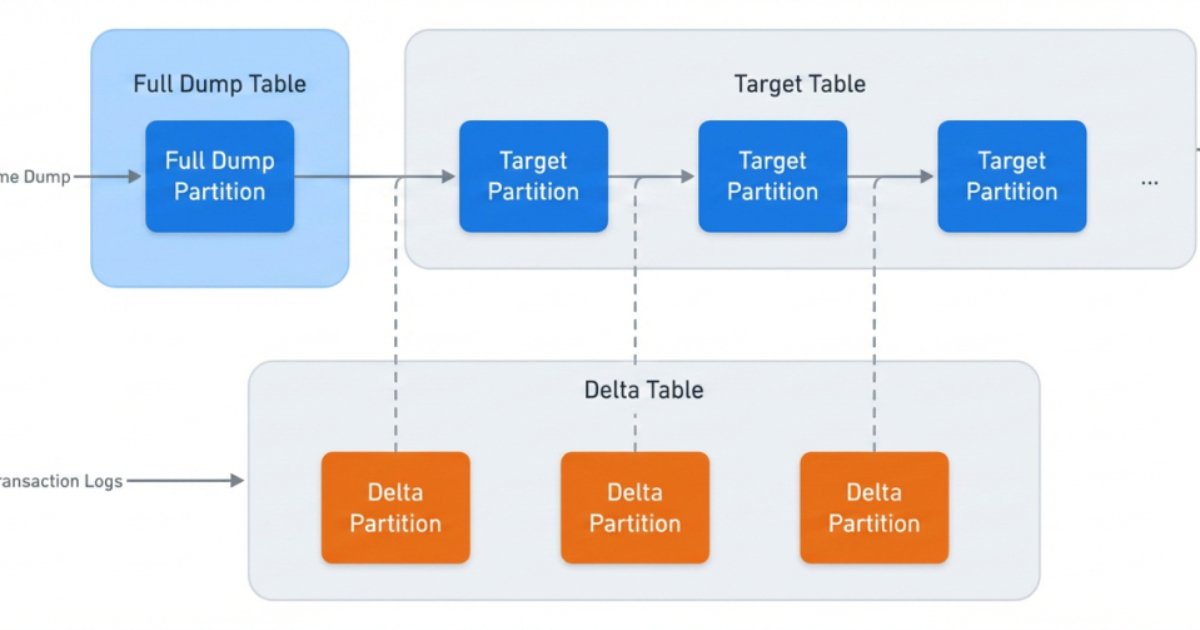
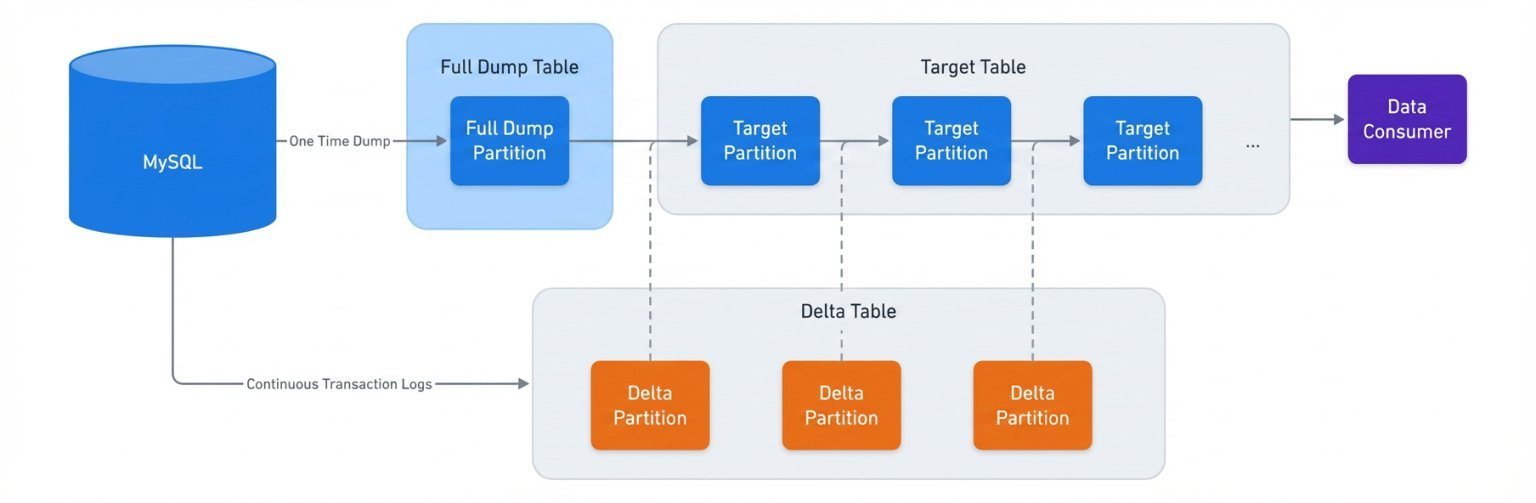
Both Meta's legacy and new data ingestion systems rely on Change Data Capture (CDC) to incrementally ingest data into target tables. Each data ingestion job maintains three key components:
- An internal table for full dumps of source databases ("full dump")
- An internal table for capturing changes to source databases ("delta")
- The target table consumed by data customers
All job metadata—including table names, schemas, and configurations—is managed by a central management service, providing a unified view of the entire ingestion ecosystem.
One of the key technical challenges was managing the expensive full snapshots required by the CDC architecture for initial loads and post-fix recovery. To optimize this process, Meta implemented several strategies:
- Minimizing the creation of unnecessary shadow jobs until data quality issues were resolved
- Reusing snapshot partitions from the legacy system during initial migration stages
- Implementing automated validation to detect issues early in the process
Operational Excellence: Managing Thousands of Jobs
The migration involved transitioning thousands of individual ingestion pipelines, each with its own requirements, dependencies, and service level agreements. To manage this complexity, the team developed:
- A centralized tracking system for migration lifecycle management
- Robust rollout and rollback controls for handling issues during migration
- Automated validation scripts that compared row counts and checksums between systems
- Performance monitoring to detect latency or resource usage regressions
For critical tables used by dependent teams, additional validation requirements were implemented, including:
- Business logic validation beyond simple checksum verification
- Cross-referencing with downstream systems to ensure complete data integrity
- Extended shadow periods for the most critical workloads
Lessons and Best Practices
The Meta team shared several key learnings from this massive migration:
Incremental Migration is Essential: At scale, big-bang migrations are impossible. The staged approach allowed for manageable risk and continuous validation.
Shadowing is Non-Negotiable: The ability to run new systems in parallel with production without impact was critical to identifying and resolving issues before they affected customers.
Automation is Mandatory: With thousands of jobs to migrate, manual validation would have been impossible. Automated validation scripts were essential for maintaining consistency.
Resource Planning Must Include Shadow Systems: The compute and storage requirements for shadow jobs must be carefully planned and provisioned to avoid resource constraints during production cutover.
Rollback Capability Provides Confidence: Knowing that any issue could be resolved by reverting to the legacy system gave the team the confidence to proceed with the migration.
Impact and Future Directions
The successful completion of this migration has significantly improved Meta's data infrastructure:
- Centralized management has reduced operational overhead
- Standardized architecture has improved reliability and performance
- The new platform provides better scalability for future growth
- Operational efficiency has been enhanced through unified tooling
Looking ahead, Meta plans to continue evolving their data ingestion architecture to support emerging workloads like real-time analytics and machine learning at even greater scales. The lessons learned from this migration will inform future infrastructure transformations at the company.
For organizations considering similar large-scale data migrations, Meta's approach demonstrates that with careful planning, thorough validation, and innovative techniques like reverse shadowing, even the most complex infrastructure transitions can be completed with zero downtime and minimal risk.
For more technical details about Meta's data ingestion architecture, you can refer to their engineering blog where they share additional insights about their approach to building and managing large-scale systems.
Comments
Please log in or register to join the discussion