
Kubernetes v1.36 'Haru' delivers significant security hardening, enhanced AI/ML workload support, and improved API scalability, with 70 enhancements across stability tiers.
The Kubernetes project has released version 1.36, codenamed 'Haru,' marking the first major Kubernetes release of 2026. This substantial update delivers 70 enhancements: 18 graduating to Stable, 25 entering Beta, and 25 new Alpha features. The release demonstrates a clear strategic direction toward tighter security defaults, more sophisticated support for AI and machine learning workloads, and improved scalability for large deployments.
Security Hardening Takes Center Stage
The most significant improvements in v1.36 center around security hardening, with several key features graduating to General Availability (GA). User Namespaces, a feature developed across multiple release cycles, now provides robust isolation by mapping a container's root user to a non-privileged user on the host system. This critical security measure prevents container escape attacks from gaining administrative access to the underlying node, addressing a long-standing security concern in multi-tenant environments.
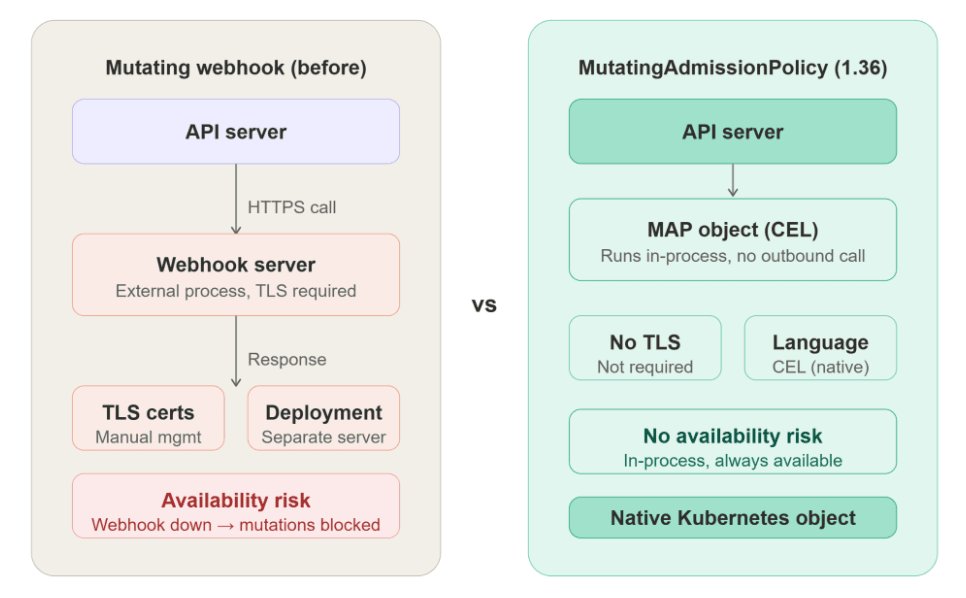
Also graduating to GA are Mutating Admission Policies, which allow teams to define mutation logic using the Common Expression Language (CEL) as native Kubernetes objects. This innovation eliminates the need to maintain separate webhook servers for admission control, providing "a native, high-performance alternative to traditional webhooks" while reducing latency and operational complexity. The Kloia team has documented this transition in detail, showing how teams can migrate their existing webhook implementations.
Fine-Grained Kubelet API Authorization completes its journey to GA in this release, addressing a long-standing permission issue in monitoring integrations. First introduced as an alpha in v1.32, this feature enables more precise, least-privilege access control over the kubelet's HTTPS API, replacing the overly broad nodes/proxy permission that monitoring and observability tools have traditionally required. This change significantly reduces the attack surface for node-level access.
SELinux Volume Labeling also reaches stable status in v1.36, replacing recursive file relabeling with a mount -o context=XYZ option that applies the correct SELinux label to an entire volume at mount time. This optimization reduces pod startup delays on SELinux-enforcing systems, which have historically suffered from performance penalties during security context initialization.
AI and ML Workload Support Matures
The AI and machine learning story in v1.36 represents a maturation of Kubernetes' approach to accelerated computing workloads. As noted by the ScaleOps team, this release is "less about brand-new mechanics and more about the defaults catching up to two years of accumulated AI workload scar tissue." Several Dynamic Resource Allocation (DRA) enhancements reach Beta status and ship enabled by default, fundamentally changing how Kubernetes handles GPU and other accelerator resources.
Specifically, DRA Partitionable Devices, DRA Consumable Capacity, and DRA Device Taints and Tolerations all flip on without requiring explicit feature gate configuration. Together, these features replace the integer-GPU device plugin model, where a single accelerator card was allocated wholesale regardless of actual utilization, with primitives that can express how modern accelerators are partitioned, shared, and recovered when they fail.
The VMware Cloud Foundation blog highlights that this approach solves a critical pain point: previously, "requesting complex resources often required opaque, vendor-specific blobs that were difficult for the scheduler to optimise." The structured approach in v1.36 reduces the complexity of multi-node AI deployments while improving resource utilization.
The headline new alpha feature for AI workloads is Workload-Aware Preemption, which addresses a persistent problem in distributed training jobs. Prior to this change, the Kubernetes scheduler would preempt individual pods when making room for higher-priority workloads, potentially leaving a distributed training job with seven of eight ranks running but unable to make progress. The new behavior treats a PodGroup as a single preemption unit and only proceeds with eviction after verifying that the high-priority group can actually fit, eliminating the "partial preemption failure mode" that has frustrated teams running large GPU jobs.
The Gang Scheduling API, first introduced as an alpha in v1.35, moves to Beta in v1.36. Similarly, Mutable Pod Resources for Suspended Jobs advances to Beta and is enabled by default. This feature allows a queue controller to suspend a running job, adjust its CPU, memory, GPU, or extended resource requests to match available cluster capacity, and then unsuspend it without destroying and recreating pods. As the Kloia team notes, this removes the need for custom controllers or killing and restarting jobs entirely, making it practical for workload queue systems to act on real-time cluster conditions.
API Scalability Improvements
For large-scale deployments, v1.36 introduces sharded list and watch streams as a new alpha feature. This addresses a critical scalability bottleneck where large clusters with many controllers encounter performance issues as all watchers receive updates through a single connection per resource type. The sharded approach distributes this load across multiple streams, which the Palark team identifies as addressing "a key pain point for very large deployments where watch streams can become bottlenecks."
Memory QoS via cgroup v2 moves to Beta in this release, offering tiered memory protection that better aligns kernel controls with pod requests and limits. This improvement reduces contention between workloads sharing a node by providing more granular memory management capabilities.
In-Place Vertical Scaling for Pod-Level Resources also moves to Beta and is enabled by default, allowing the pod scope CPU and memory envelope to be resized without a container restart. A new ResizeDeferred event type is introduced so that when a resize cannot be applied immediately due to insufficient node capacity, the pod continues running at its existing size while the kubelet retries the resize once capacity becomes available. This feature significantly improves the developer experience for workloads that require dynamic resource adjustments.
Breaking Changes and Deprecations
Teams planning upgrades should be aware of several removals in this release. The gitRepo volume plugin is permanently removed after being deprecated since v1.11; it allowed attackers to run code as root on a node, and the PerfectScale team advises migrating to init containers or external git-sync tooling before upgrading.
IPVS mode in kube-proxy, deprecated in v1.35, is also removed. Additionally, flex-volume support in kubeadm and the Portworx in-tree driver are removed in this release, as noted in the Kloia team's upgrade guidance.
A significant operational change that predates this release but is highlighted in the v1.36 release blog is the retirement of Ingress NGINX. Kubernetes SIG Network and the Security Response Committee retired the project on March 24, 2026. Since that date, there have been no further releases, bugfixes, or security vulnerability patches. InfoQ covered the evolution of Kubernetes networking in its Kubernetes 1.35 release coverage, which noted that Ingress NGINX would "receive only best-effort maintenance until March 2026."

Strategic Direction and Enterprise Considerations
The VMware Cloud Foundation blog contextualizes the release as part of a larger shift: "Kubernetes is moving from a flexible framework toward more opinionated defaults for security and resource standards." This strategic direction balances Kubernetes' historical flexibility with the need for more secure, predictable behavior out of the box.
The same post observes that "keeping up with Kubernetes is no longer just about upgrading clusters," but involves "managing lifecycle complexity, deciding when to adopt new versions, understanding how changes impact existing workloads, and avoiding disruption as the platform evolves." This perspective highlights the growing maturity of the Kubernetes ecosystem and the increasing sophistication required for enterprise adoption.
For organizations running AI workloads, the improvements in v1.36 represent a significant step forward in both security and operational efficiency. By moving toward a more structured approach to resource allocation, Kubernetes is making it easier for the scheduler to understand the specific requirements of a GPU or AI accelerator, drastically reducing the complexity of multi-node AI deployments while improving isolation and security.
The full release notes for Kubernetes 1.36 are available on the official Kubernetes website, and teams should review the detailed upgrade guide before planning their migration to this new version.
Comments
Please log in or register to join the discussion