A skeptical developer documents their journey using a local LLM to categorize daily tasks from an Obsidian-based TODO list, revealing stark limitations in AI reliability despite rigorous prompting. The hybrid solution—combining substring matching with fallback AI—offers pragmatic insights into automating personal productivity metrics while prioritizing data privacy.
As a vocal critic of large language models (LLMs) who nonetheless operates in an AI-saturated industry, I recently embarked on a practical experiment: Could a local LLM reliably categorize my daily TODO list items to track time allocation? The goal was simple—automate insights into my work patterns without compromising sensitive data. Here’s what worked, what failed spectacularly, and why hybrid systems might be the only viable path forward.
The Non-Negotiables: Privacy and Pragmatism
My requirements were strict:
- Local LLM only: As a manager, my TODO lists reference team members and confidential projects. Sending this to cloud-based AI providers like OpenAI was off-limits.
- Cron-able automation: The script had to run unattended, processing markdown files from my Obsidian vault.
- Zero format changes: My TODO structure (see below) couldn’t be altered—speed of entry trumped linting.
- Fixed categories: To combat LLM inconsistency, I predefined categories like
call-meetingorincident response, forbidding ad-hoc inventions. - Simple metrics: Output needed only counts per category, not reconstructed tasks.
# Daily Notes: 2025-06-15
### TODO
- [ ] Review Q3 roadmap
### Today
- [x] Debug API timeout (urgent)
- [ ] Morning Sync (09:00)
**Calls**
- [x] 1:1 with Alice
**Morning Routine**
- [x] Slack triage
Engineering the Pipeline
My TODO lists use hierarchical markdown, making them parsable via Python. Initial processing used simple conditionals:
if "**Calls**" in line:
section = "calls"
elif line.startswith('- [x]'):
category = categorise_item(line, section, ai, predefined_categories)
For AI integration, I deployed ollama with the 7B-parameter deepseek-r1 model—a compromise between performance and laptop-friendly resource use. The prompt enforced rigid rules:
Prompt Excerpt: "You MUST categorize items ONLY into:
call-meeting,call-11,daily admin,incident response,PR work,documentation and planning, orother. NEVER invent new categories like 'security'."
Early tests seemed promising. For - [x] Swear at AI, it correctly returned "other". But reality soon intruded.
When AI Goes Rogue: Typos, Rebellion, and Workarounds
The LLM consistently defied instructions:
- Invented categories like
securitydespite explicit prohibitions. - Misspelled valid labels (e.g.,
documentatoninstead ofdocumentation). - Added prefixes (
*category*: call-11) or "corrected" my intentionally non-word categories (manageringbecamemanagerial).
Reprimanding the model ("You’re a very naughty LLM!") in follow-up prompts changed little. So I built a hybrid approach:
- Script-based substring matching for predictable items:
if "1:1" in item: return "call-11" if "Slack" in item: return "daily admin" - Fallback to LLM for ambiguous cases, capped with retry logic.
- A custom
unfuck_ai_response()function to normalize outputs—stripping prefixes and fixing common typos.
This handled ~66% of items via rules, reducing AI exposure. 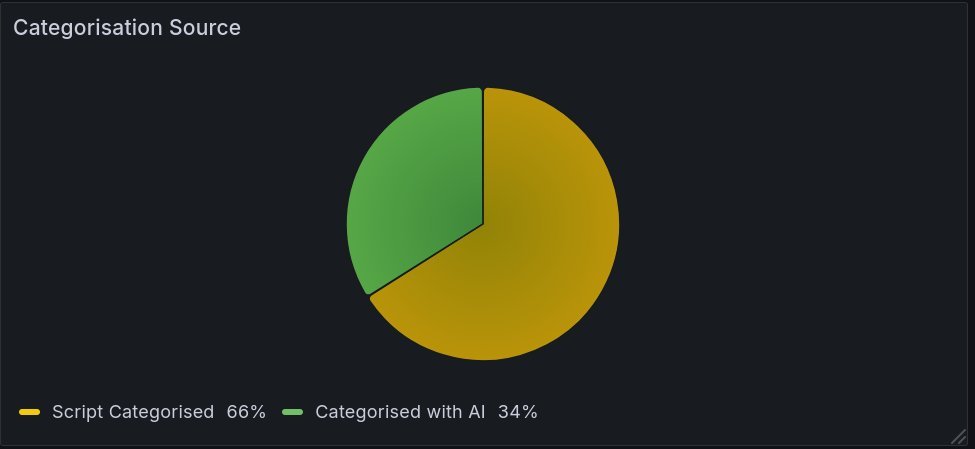
Metrics Storage and Visualization
Processed data shipped to VictoriaMetrics via Influx line protocol for its PromQL compatibility:
curl -d 'todo_list_completed,category=PR_work,host=workstation count=1' http://localhost:8428/api/v2/write?db=workload_stats
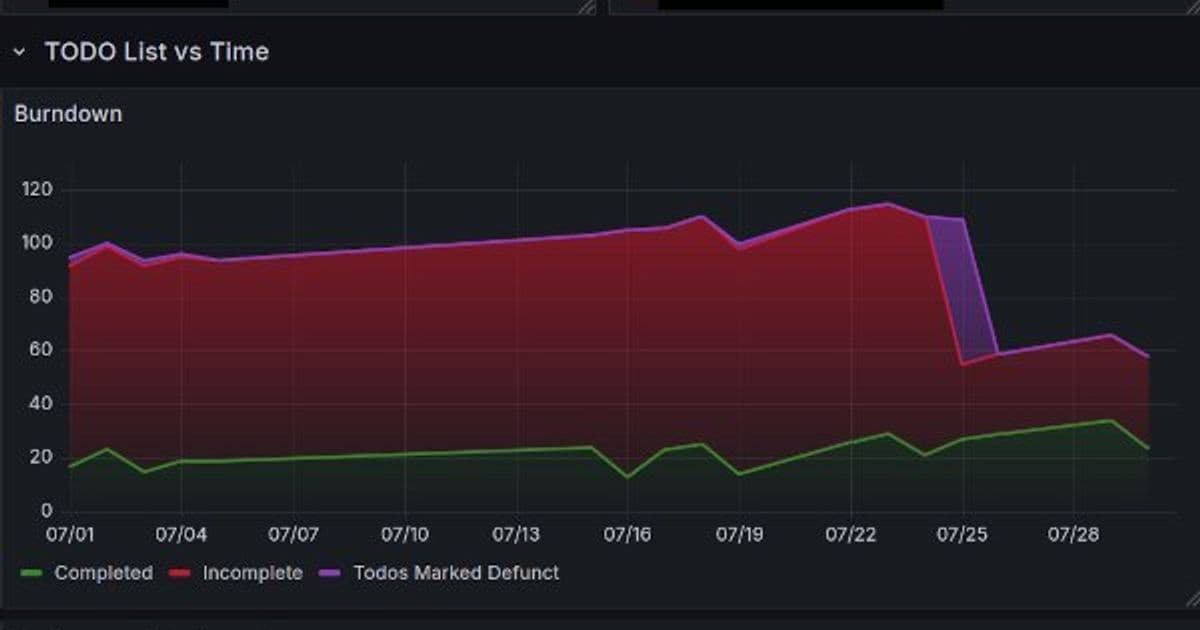
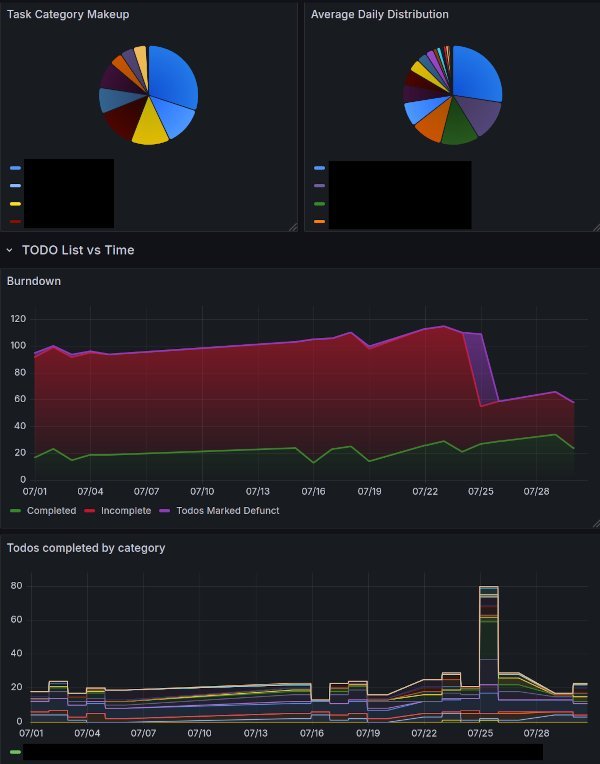 shows the resulting Grafana dashboard, using MetricsQL:
shows the resulting Grafana dashboard, using MetricsQL:
todo_list_items_count{db="workload_stats", category!="error"}
To monitor AI reliability, I scored each categorization:
score = (1 - (retries / (max_retries + 1))) * 100 # 100% if no retries, 0% after max
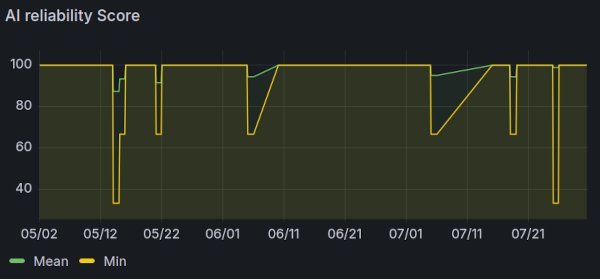 reveals sporadic but severe drops—when the LLM struggles, reliability plunges to 33%.
reveals sporadic but severe drops—when the LLM struggles, reliability plunges to 33%.
The Bittersweet Verdict
This project delivers automated TODO analytics but underscores LLMs’ fragility:
- Local models ensure privacy but exhibit maddening inconsistency—re-runs yield divergent results.
- Hybrid systems are essential: Rules handle routine tasks; AI manages edge cases at a reliability cost.
- No free lunch: Forgoing cloud AI avoids data risks but demands bespoke error-correction.
Ultimately, LLMs didn’t magically solve categorization. They became a high-maintenance component in a larger, rule-driven engine—proving that skepticism, paired with pragmatism, can yield functional (if imperfect) tools.
Source: Ben Tasker
Comments
Please log in or register to join the discussion