
When Stack Overflow faced the retirement of NGINX-Ingress, they conducted a thorough evaluation of Gateway API implementations and Ingress controllers. Their testing methodology, performance benchmarks, and final decision-making process provide valuable insights for organizations facing similar Kubernetes infrastructure transitions.
The Challenge: Replacing a Retired Ingress Controller
In November 2022, Stack Overflow received unexpected news: the Ingress-NGINX project was being retired. This announcement caught the team off guard, as NGINX-Ingress had been handling their traffic routing since their migration to Kubernetes. Like many organizations, they had been operating under the assumption that their current solution would remain viable for the foreseeable future.
The retirement created an urgent need to find a replacement. While there had been some discussions about the newer Gateway API that supersedes Ingress, no significant effort had been invested in exploring this transition. The existing setup was working fine, and the team had other priorities. Now, with their hand forced by the retirement, they needed to develop a plan and integrate it into their near-term roadmap.
Evaluation Criteria: Narrowing the Options
With numerous gateway and ingress solutions available, the team first established criteria to narrow the field. They had two primary paths to consider: migrating to a Gateway API implementation or switching to another Ingress controller.
Their evaluation framework included:
- Conformance status: Solutions needed to be fully conformant to their respective APIs
- Multi-cloud compatibility: Since Stack Overflow operates across GCP and Azure, cloud-specific solutions were eliminated
- Feature parity: Assessment of support for their current use cases
- Performance characteristics: Under various load conditions
- Scalability limits: Particularly for route creation and convergence
This process narrowed their options to three Gateway API implementations:
- NGINX Gateway Fabric
- Traefik
- Istio
And two Ingress controllers as potential fallbacks:
- F5 NGINX Ingress
- Traefik (which can operate in both Ingress and Gateway modes)
Interestingly, HAProxy—a solution Stack Overflow had used reliably in their data center before moving to GKE—was initially listed as a stale implementation but has since achieved full conformance status.
Understanding Current Usage Patterns
Before testing replacements, the team needed a clear understanding of their current routing requirements. They exported all Ingress objects from their production clusters to YAML files and used Claude (an AI assistant) to analyze and categorize these into distinct use case buckets.
The analysis revealed that most of Stack Overflow's routing was straightforward, with a few complex outliers. This simplified their testing to approximately half a dozen use cases, complemented by two scalability benchmarks:
- Requests per second (RPS) handling capability
- Route creation and convergence performance
The Testing Environment
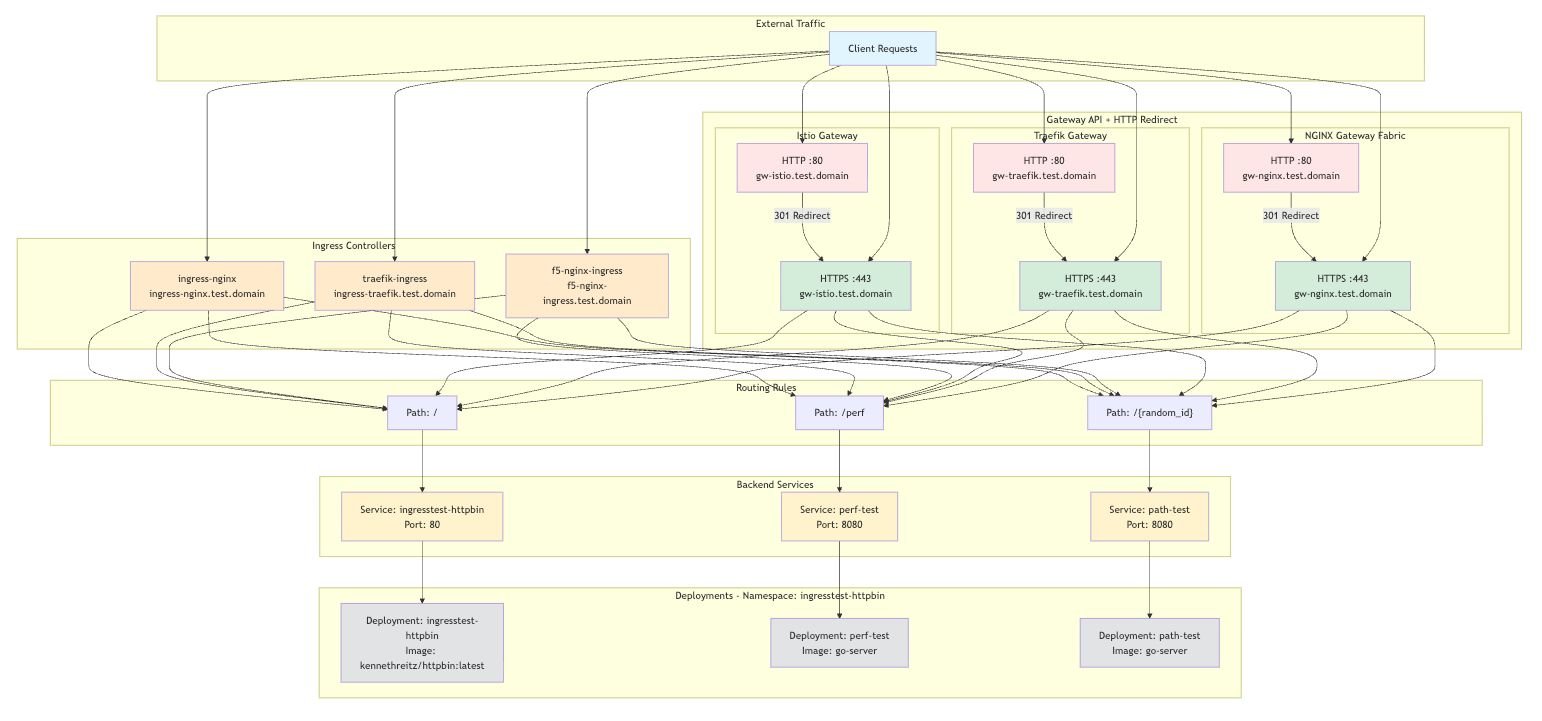
To conduct objective comparisons, the team built a controlled testing environment with two primary backends:
HTTPBin: A tool for HTTP-related testing that allows introspection of both requests and responses. This was particularly useful for testing dynamic header modifications, where they could send a request with host header X and verify the server received host header Y.
Performance server: A simple Go web server designed to handle high request volumes quickly. This server included a configurable latency parameter to simulate slower responses, testing performance under conditions where connections and active requests accumulate.
The testing architecture followed a pattern of external traffic routing through various gateways, ingress controllers, and backend services. This setup allowed them to validate routing rules under different conditions and measure performance metrics accurately.
Performance Benchmark Results
The team conducted RPS benchmarks with a target of 10,000 RPS—designed to provide headroom above their normal steady-state traffic. Tests were run with 0ms, 150ms, and 350ms of simulated server latency across all three implementations.
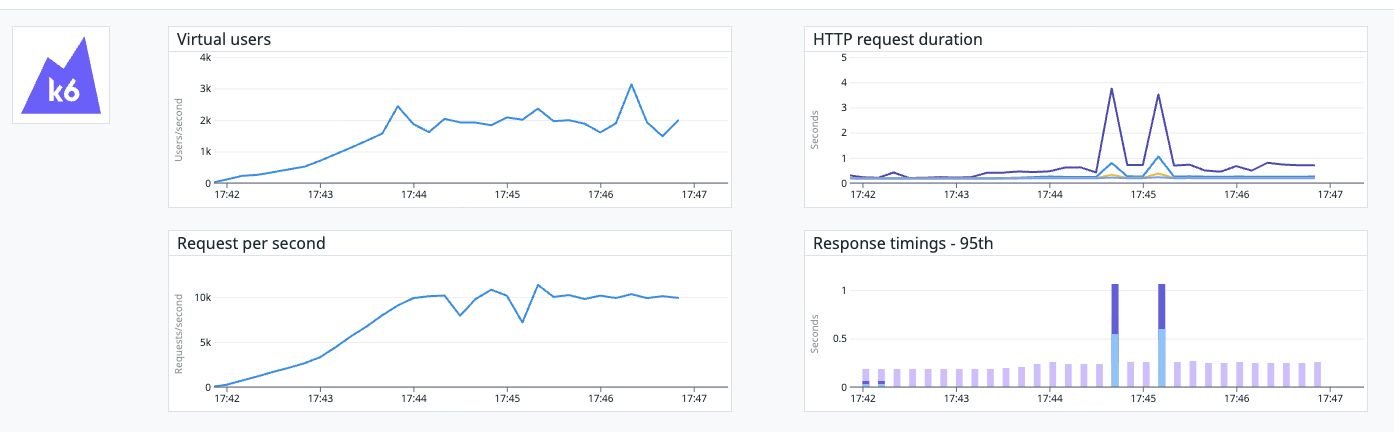
Results with 150ms latency showed relatively similar performance across all solutions:
- Traefik: Average response time 188.27ms
- NGINX: Average response time 205.34ms
- Istio: Average response time 186.73ms
All three implementations handled the baseline tests without significant issues, suggesting any would meet Stack Overflow's current scalability requirements under normal conditions.
Route Creation and Convergence Testing
The team also tested how each implementation handled large numbers of HTTPRoutes. Initially, they set a target of 5,000 routes, which all three implementations successfully converged on, though with notable differences in performance.
The test involved creating 5,000 HTTPRoutes, each with a single path rule, and concurrently sending requests to those paths until all returned correct responses. This verified proper routing while measuring convergence time.
Results showed significant differences:
- NGINX: All 5,000 routes converged in 42.047s
- Istio: All 5,000 routes converged in 41.981s
- Traefik: Required over 5 minutes (timed out) to fully converge, though it did eventually load all routes
These results led the team to reconsider their practical limits. While 5,000 routes might theoretically be possible, real-world performance suggested a more conservative approach was necessary.
Behavior During Route Updates
A critical discovery emerged during testing with 1,000 routes (a more realistic target based on their actual usage). When running the K6 benchmark generating 10k RPS while simultaneously updating routes:
- Istio and Traefik: Remained unaffected
- NGINX: Experienced significant latency spikes during even single HTTPRoute updates

The graph clearly shows two large latency spikes during NGINX route updates, with response times dramatically increasing. This behavior would be unacceptable for a production environment requiring consistent performance.
The Decision: Why Istio Won
After comprehensive testing across use cases, performance metrics, and edge conditions, Stack Overflow selected Istio as their new gateway solution. The decision was based on several factors:
- Stability and performance: Istio demonstrated consistent performance across all test scenarios, including during route updates
- Feature depth: While some Gateway API features looked promising on paper, Istio offered the most comprehensive implementation
- Future-proofing: Istio provides advanced features beyond their current needs, offering room for growth
The team acknowledged that any of the evaluated solutions could likely work in their environment, but Istio demonstrated the most solid and predictable performance characteristics.
Key Trade-offs and Considerations
The migration process revealed several important trade-offs that organizations should consider when evaluating gateway solutions:
Gateway API vs. Ingress: While Gateway API offers better role separation and more features, implementations vary in maturity and completeness
Implementation-specific extensions: Some features required implementation-specific extensions rather than standard API resources
Complex integrations: Migrating complex integrations (like authentication modules) can be challenging when behavior differs between implementations
Route convergence performance: Not all implementations scale equally when handling large numbers of routes
Lessons for Organizations Facing Similar Migrations
Stack Overflow's experience offers several valuable lessons:
Start early: Their initial lack of preparation for the NGINX-Ingress retirement created unnecessary urgency
Test realistic scenarios: Testing with actual production workloads and patterns is crucial
Consider update performance: How a gateway behaves during configuration changes is as important as steady-state performance
Balance features and complexity: More features don't always mean better for specific use cases
Plan for migration complexity: Complex integrations may require application modifications when switching solutions
Stack Overflow is now proceeding with their Istio migration, with plans to share additional insights if they encounter noteworthy challenges during the transition. Their thorough testing approach provides a valuable framework for organizations facing similar infrastructure decisions.
For organizations evaluating gateway solutions, the Gateway API offers a standardized approach to traffic management, while implementations like Istio, NGINX Gateway Fabric, and Traefik provide different approaches to meeting these requirements.
Comments
Please log in or register to join the discussion