
Monzo rebuilt its warehouse around a four‑layer data mesh, introduced CI‑driven guardrails and a model‑generation tool, and now sees roughly 40 % lower warehouse spend and 25 % faster data landing for more than 12 000 dbt models.
Monzo’s Governed Data Mesh Cuts Costs and Speeds Delivery Across 100 Teams

Monzo announced that its new data platform, built as a governed data mesh, now supports over 100 product teams and more than 12 000 dbt models. The redesign introduced explicit interface layers, automated model generation, and continuous‑integration checks. Early metrics show a 40 % reduction in warehouse spend and a 25 % improvement in data landing time.
Service update
- Data platform – A four‑layer architecture that separates raw landing, normalized entities, logical business views, and presentation models. Each layer is versioned and published as a first‑class interface.
- Modelgen – A CLI tool that takes a JSON‑like object definition and emits the corresponding SQL and yaml files for dbt. It guarantees that every model follows the same naming, key, and metadata conventions.
- CI guardrails – Pull‑request pipelines run linting, schema‑validation, freshness tests, and ownership checks before a model can be merged.
- Pricing impact – By eliminating redundant recomputation and enforcing incremental materialisation, the warehouse footprint fell by roughly 40 %.
For more details, see Monzo’s engineering blog post.
Use cases
1. Distributed analytics ownership
Each product team owns the models that describe its domain (e.g., payments, fraud, onboarding). Because interfaces are declared in a shared catalogue, downstream teams can safely consume those datasets without needing to know the underlying implementation. This reduces the “snowball” effect where a change in one model forces a cascade of downstream rewrites.
2. Rapid onboarding of new data products
New squads spin up a landing model, run Modelgen to scaffold the normalized entity, and immediately publish the logical view. The CI checks enforce a unique primary key, freshness expectations, and documentation, so the model becomes consumable the moment it lands. Teams have reported being able to ship a new analytical feature in days rather than weeks.
3. Cost‑effective scaling
The mesh makes it easy to identify overlapping queries. When two teams request the same aggregation, the platform consolidates the work at the normalized layer, avoiding duplicate scans. Incremental materialisation further limits the amount of data processed each run, which directly translates into lower cloud‑warehouse charges.
Trade‑offs
| Aspect | Benefit | Consideration |
|---|---|---|
| Governance | Automated CI checks keep naming, key, and freshness standards consistent across 100 teams. | Requires disciplined CI pipeline maintenance; a broken rule can block many teams simultaneously. |
| Tooling (Modelgen) | Guarantees that every model starts from a vetted template, reducing manual errors. | Teams need to learn the object‑definition syntax; migration of legacy models can be labor‑intensive. |
| Layered architecture | Clear separation of concerns makes it easier to evolve business logic without touching raw ingestion. | Adding a new layer or changing an interface definition may involve a coordinated rollout across many downstream models. |
| Cost savings | 40 % reduction in warehouse spend by eliminating redundant recomputation. | Savings depend on teams actually adopting the shared interfaces; isolated silos can still generate waste. |
Overall, the mesh works best when the organisation embraces a culture of shared contracts and invests in CI infrastructure. Teams that treat interfaces as code and push validation early reap the biggest performance and cost benefits.
Architectural snapshot
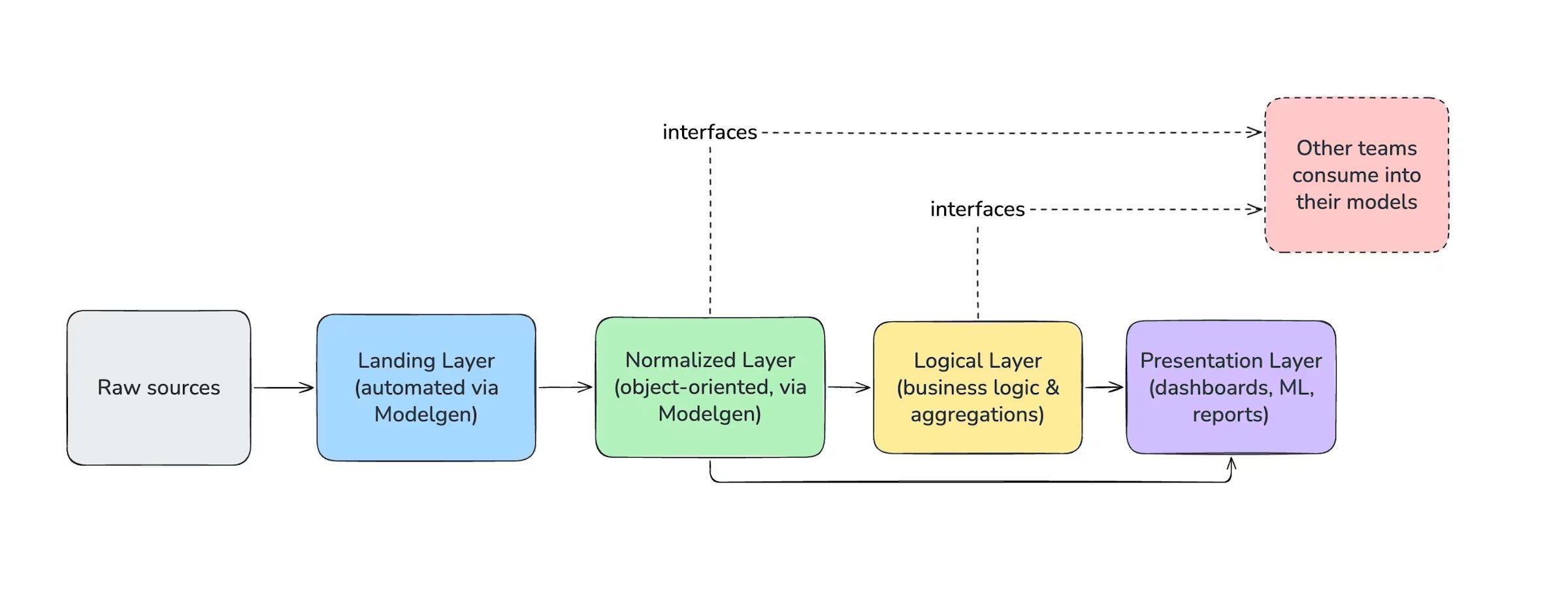
The diagram above (from Monzo’s blog) visualises the four layers:
- Landing – Raw event streams are flattened into tables.
- Normalized – Entity‑centric tables with full change history.
- Logical – Business‑logic joins that produce domain‑specific views.
- Presentation – Denormalised tables tuned for BI tools or downstream services.
Each layer publishes a versioned interface that downstream models reference via dbt ref() calls. The CI pipeline validates that a referenced interface exists, that its schema matches expectations, and that the consuming model declares the correct owning team.
What this means for other organisations
Monzo’s experience shows that a governed data mesh can be introduced without abandoning dbt. The key ingredients are:
- Explicit contracts – Treat dataset definitions as versioned code.
- Automation – Use a generator and CI checks to enforce contracts.
- Incremental materialisation – Keep processing costs low by only recomputing changed partitions.
Companies that already use dbt can adopt Modelgen‑style scaffolding and start publishing interface definitions in a central catalogue. Over time, the mesh can grow to cover more domains, delivering the same cost and speed improvements that Monzo reports.
Renato Losio is a principal cloud architect and AWS Data Hero. Follow him on LinkedIn.
Comments
Please log in or register to join the discussion