Orthrus introduces a dual-architecture framework that combines autoregressive and diffusion models to achieve up to 7.8× speedup in token generation while claiming to preserve the exact predictive distribution of base LLMs.
Researchers have introduced Orthrus, a novel approach to LLM inference that aims to break the sequential bottleneck of autoregressive decoding while maintaining exact generation fidelity. The framework, detailed in a paper dated 2026 (likely a pre-publication), claims to unify the best of both autoregressive and diffusion model approaches through a dual-view architecture.
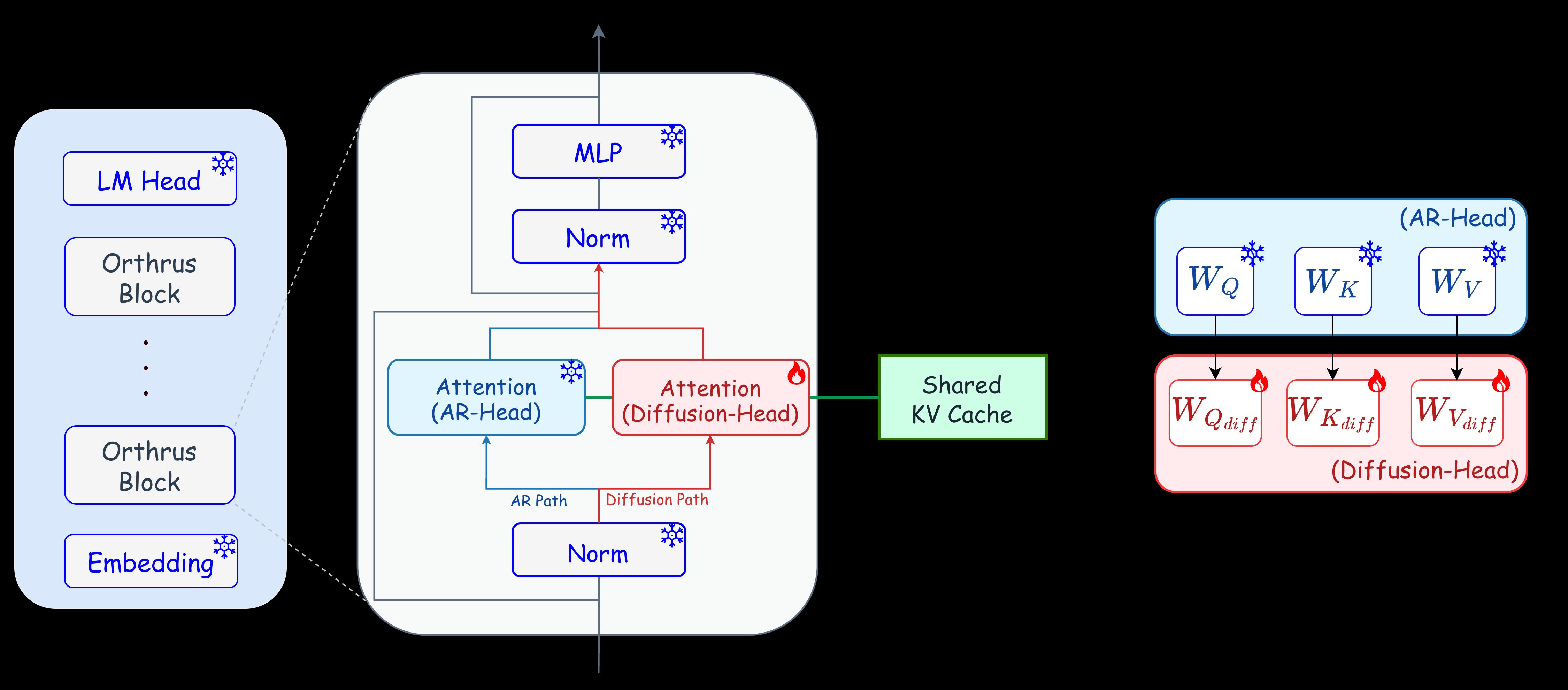
The core innovation lies in Orthrus's dual-view approach, where both autoregressive and diffusion views attend to the exact same high-fidelity Key-Value (KV) cache. This design allows the model to generate tokens in parallel while maintaining the exact predictive distribution of the original autoregressive model. According to the authors, this approach eliminates the conditional drift and accuracy degradation commonly seen in other diffusion language models.
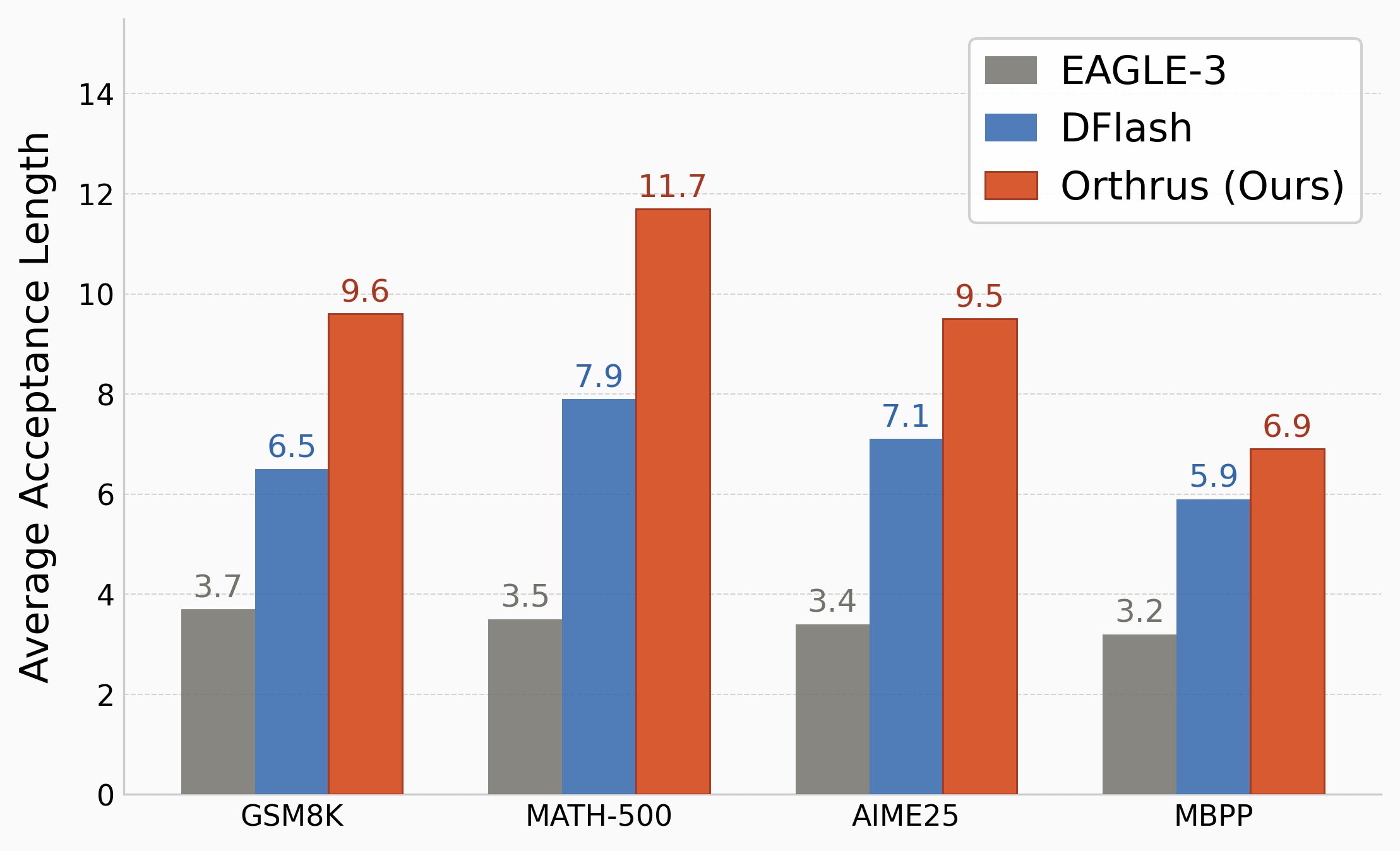
Orthrus shows promising benchmark results across different model sizes:
- Orthrus-Qwen3-1.7B: 4.25× speedup over baseline
- Orthrus-Qwen3-4B: 5.20× speedup over baseline
- Orthrus-Qwen3-8B: 5.36× speedup over baseline
The approach appears particularly effective at longer context lengths, where traditional autoregressive methods become increasingly slow. The authors claim that Orthrus can achieve up to 7.8× speedup on generation tasks while maintaining strictly lossless generation.
A key advantage of Orthrus is its parameter efficiency. The parallel generation capabilities are achieved by fine-tuning only 16% of the total model parameters while keeping the base LLM strictly frozen. Additionally, the dual-view design results in only O(1) memory cache overhead, as both views share the same KV cache natively.
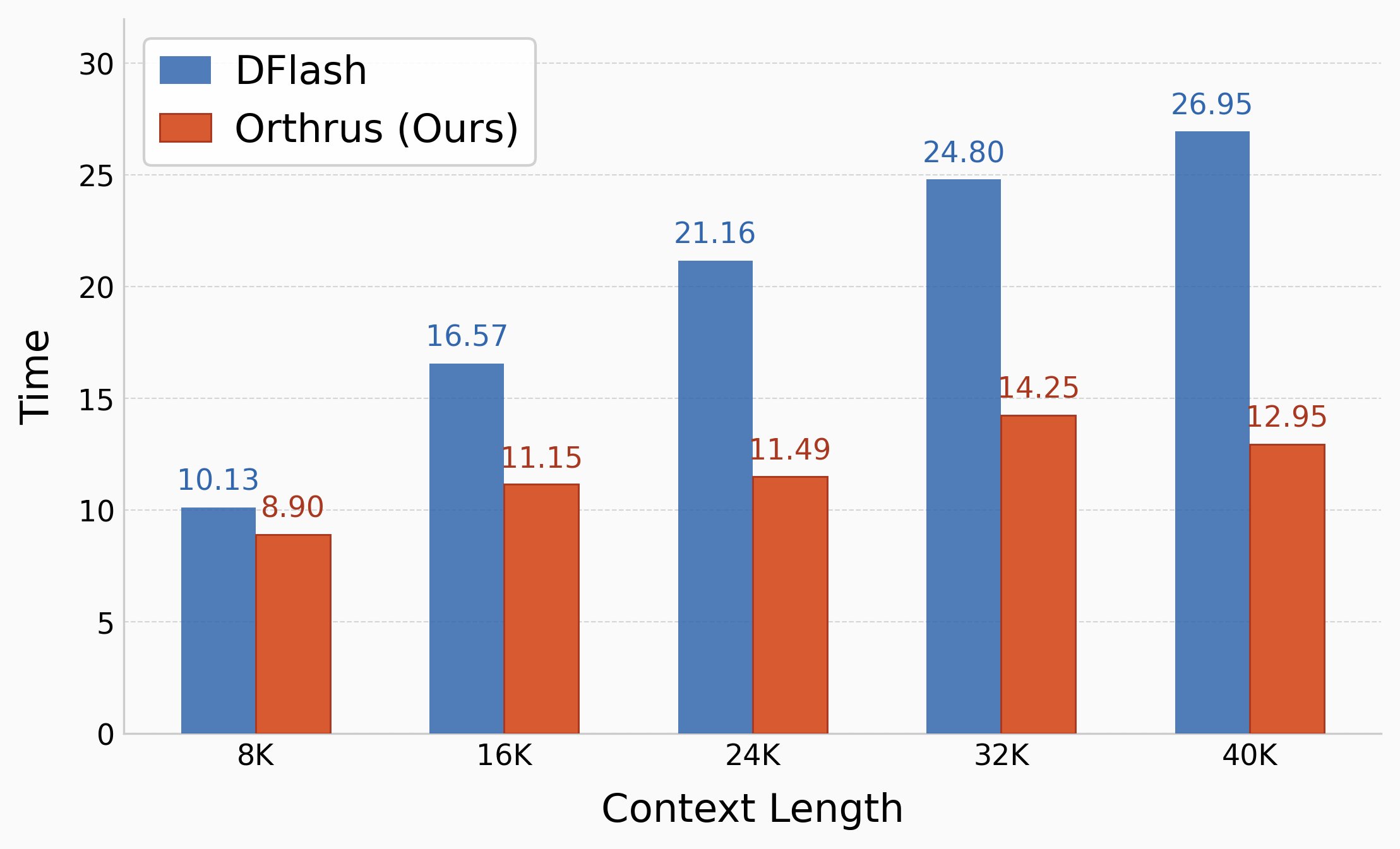
When compared to speculative decoding methods like EAGLE-3 and DFlash, Orthrus demonstrates superior token acceptance rates and faster inference times. This advantage becomes more pronounced as context length scales, largely due to Orthrus's native sharing of the exact same KV cache across dual views, avoiding the redundant memory overhead of draft models.
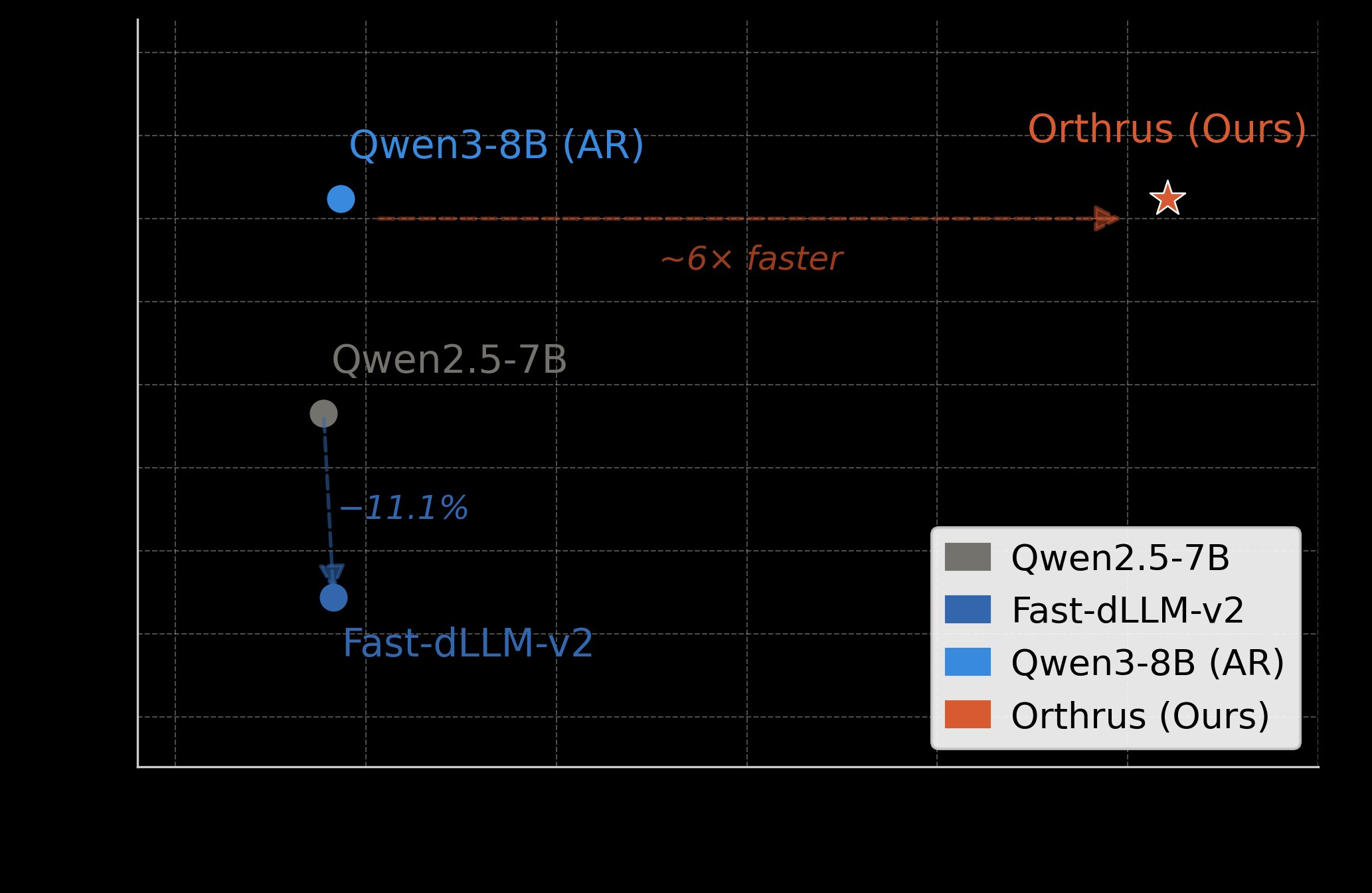
The approach also shows significant improvements over other diffusion language models. While recent dLLMs offer parallel decoding, they often suffer from conditional drift and accuracy degradation on complex reasoning tasks. Orthrus reportedly resolves this by decoupling parallel generation from sequential constraints, establishing a new state-of-the-art for parallel generation fidelity.
On the MATH-500 benchmark, Orthrus delivers approximately 6x speedup over the Qwen3-8B baseline with strictly lossless performance, whereas adaptations like Fast-dLLM-v2 suffer significant accuracy drops.
The implementation is available on GitHub with model checkpoints on HuggingFace. The codebase supports easy integration with existing frameworks, and the authors note that native integration with vLLM and SGLang is planned for future releases.
Despite these promising results, several questions remain about the practical deployment of Orthrus. The paper's 2026 date suggests this might be a pre-publication version, and independent verification of the claims would be valuable. Additionally, the computational overhead of maintaining dual views and the impact on memory usage during very long sequences warrant further investigation.
For those interested in exploring Orthrus, the official repository provides installation instructions and a quickstart example. The models can be loaded using the standard HuggingFace transformers library with specific parameters to enable the diffusion mode.
Comments
Please log in or register to join the discussion