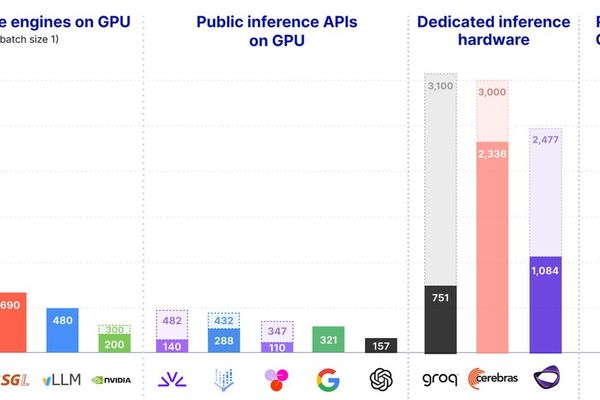
LLMs
Real‑time LLM Inference on Standard GPUs Hits 3,000 tokens/s per Request
5/29/2026

Chips
DeepSeek V4 Completes Full Adaptation to Huawei Ascend, Marking a Milestone for China AI Stack
5/25/2026
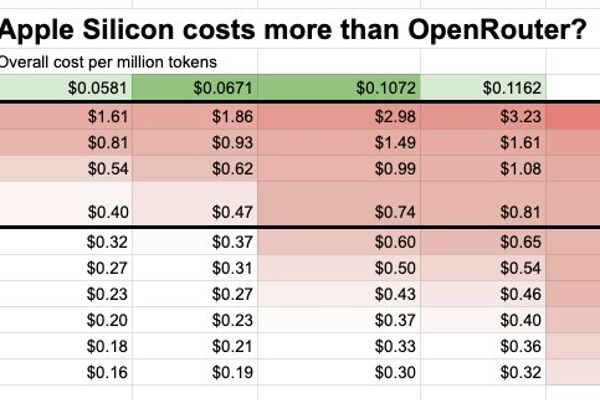
LLMs
Apple Silicon vs. OpenRouter: A Cost‑and‑Speed Reality Check
5/17/2026
LLMs
Orthrus: Dual-View Diffusion Decoding Claims to Accelerate LLM Inference While Maintaining Exact Generation Fidelity
5/16/2026

Hardware
Zero-Copy GPU Inference from WebAssembly on Apple Silicon
4/19/2026

LLMs
ZSE: A Memory-Efficient LLM Inference Engine with Smart Resource Orchestration
2/26/2026
Hardware
nTransformer Enables Llama 70B Inference on Single Consumer GPU with Novel Streaming Architecture
2/22/2026

Chips
Beyond the Data Center: Taalas and the Path to Ubiquitous AI
2/20/2026

LLMs
Continuous Batching: Optimizing LLM Inference Throughput from First Principles
2/16/2026

Hardware
Memory Walls and Interconnect Bottlenecks: New Research Charts Path for Efficient LLM Inference Hardware
1/25/2026

LLMs
The End of One-Size-Fits-All LLM APIs: Why Workload-Specific Inference Is Taking Over
1/22/2026