
Taalas challenges the energy-intensive trajectory of AI infrastructure with specialized silicon that merges computation and memory, achieving order-of-magnitude improvements in speed, cost, and power efficiency.

The exponential growth of artificial intelligence faces twin constraints that threaten its trajectory: computational latency incompatible with human cognition, and infrastructure costs scaling toward environmental unsustainability. Where contemporary solutions build ever-larger data centers consuming hundreds of megawatts, Ljubisa Bajic and the team at Taalas propose an architectural revolution rooted in computing history. Their approach resurrects a fundamental lesson from the evolution from ENIAC to smartphones: transformative technologies achieve ubiquity not through brute-force scaling, but through radical simplification and specialization.
This historical parallel forms Taalas' foundational thesis. The vacuum-tube behemoths of the 1940s gave way to transistors not merely because they were smaller, but because they enabled fundamentally different architectural principles—principles that shifted computing from room-sized installations to pocketable devices. Similarly, Taalis contends that today's GPU clusters represent an ENIAC moment for AI, awaiting a similar paradigm shift. Their solution hinges on three interconnected principles that collectively bypass the limitations of general-purpose AI hardware.
Total Specialization: The Model as Architecture
General-purpose processors sacrifice efficiency for flexibility—a reasonable trade-off when workloads vary, but increasingly untenable for the predictable, repetitive patterns of transformer-based inference. Taalas eliminates this compromise by treating each AI model as a unique hardware blueprint. Their platform ingests a neural network architecture and outputs optimized silicon within two months, creating what they term "Hardcore Models": physical embodiments of mathematical structures. This approach mirrors application-specific integrated circuits (ASICs) but operates at unprecedented speed and specificity. Where conventional hardware runs software-defined models, Taalas' silicon is the model.
Collapsing the Memory Wall
 Figure 1: Taalas HC1 hard-wired with Llama 3.1 8B model
Figure 1: Taalas HC1 hard-wired with Llama 3.1 8B model
The most consequential innovation lies in dissolving computing's oldest bottleneck: the separation between processing and memory. Modern AI accelerators rely on high-bandwidth memory (HBM) stacks—expensive, power-hungry solutions that still operate orders of magnitude slower than on-chip SRAM. Taalas' architecture integrates computation directly within DRAM arrays using a proprietary 3D fabrication process. By eliminating data movement between discrete components, they circumvent the physical constraints requiring exotic cooling solutions and multi-chip modules. The resulting monolithic chips perform computations at memory access speeds, achieving what Bajic describes as "DRAM-level density with processor-level throughput."
Radical Simplification
The synergy of specialization and integrated architecture enables extraordinary reductions in system complexity. Without needing high-speed interconnects, liquid cooling, or advanced packaging, Taalas' systems resemble traditional server boards rather than supercomputing nodes. This engineering elegance directly translates to cost efficiency: their first-generation hardware achieves a 20x reduction in build cost and 10x power savings versus equivalent GPU-based systems.
Performance Realized: The Silicon Llama
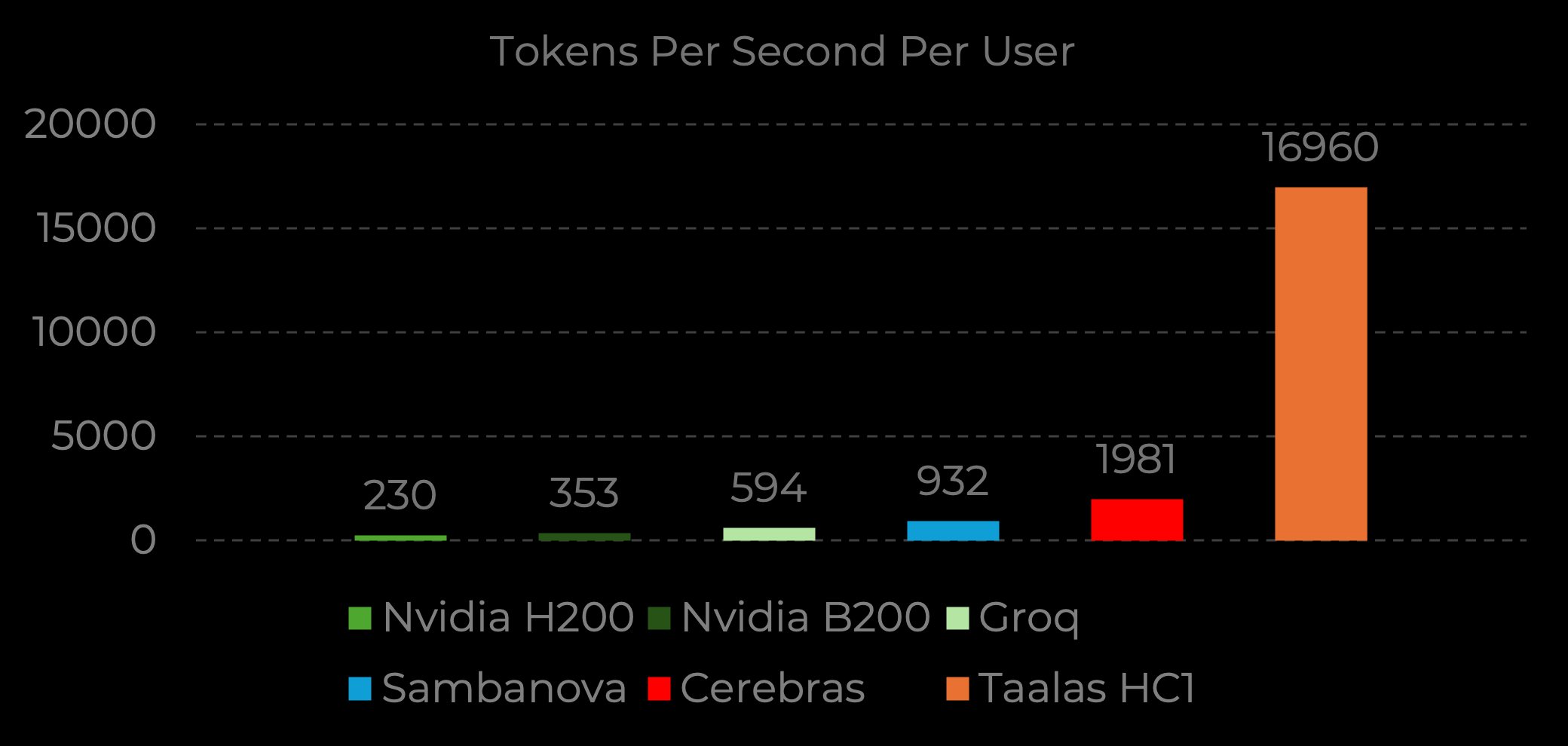 Performance data for Llama 3.1 8B, Input sequence length 1k/1k | Source: Nvidia Baseline (H200), B200 measured by Taalas | Groq, Sambanova, Cerebras performance from Artificial Analysis | Taalas Performance run by Taalas labs
Performance data for Llama 3.1 8B, Input sequence length 1k/1k | Source: Nvidia Baseline (H200), B200 measured by Taalas | Groq, Sambanova, Cerebras performance from Artificial Analysis | Taalas Performance run by Taalas labs
Taalas' inaugural product—a hard-wired implementation of Meta's Llama 3.1 8B model—demonstrates these principles in practice. Running on their HC1 platform, it generates 17,000 tokens per second per user, nearly 10x faster than Nvidia's H200 GPUs. While this initial implementation uses aggressive 3-bit quantization (resulting in measurable quality trade-offs), its throughput enables fundamentally new interaction paradigms. Developer applications accessing the Taalas inference API experience sub-millisecond response times, effectively removing latency as a design constraint.
Strategic Pragmatism
Taalas' roadmap reflects deliberate technical pragmatism. Their second-generation HC2 platform adopts standardized 4-bit floating-point formats to address quantization limitations while maintaining efficiency. A mid-sized reasoning LLM is scheduled for release in Q2 2025, followed by a frontier model implementation targeting winter deployment. Crucially, the company operates with unusual capital efficiency: their first product reached market with just 24 engineers and $30 million in development expenditure—a fraction of typical AI hardware ventures.
Implications: The Shape of Ubiquity
The significance extends beyond benchmarks. By reducing inference costs to near-zero and latencies to imperceptibility, Taalas enables agentic applications previously constrained by economics or interaction dynamics. Consider coding assistants that respond at human thought-speed, or real-time translation systems operating locally on edge devices. Their approach suggests a future where specialized AI hardware evolves as dynamically as software models—potentially enabling continuous hardware refinement alongside model development.
Yet challenges persist. The very specialization that enables efficiency complicates model iteration: each architectural change requires silicon respins, though Taalas' two-month turnaround mitigates this. Moreover, the viability of their model-specific approach for rapidly evolving frontier models remains unproven. But as an existence proof against computing's current trajectory, Taalas offers more than an accelerator; it presents an alternative paradigm where ubiquitous intelligence emerges not from planetary-scale computing, but from fundamental architectural reinvention.
Developers can apply for API access to experiment with Taalas' instant-Llama implementation. The true test lies not in synthetic benchmarks, but in what becomes possible when generative AI operates at the speed of thought.
Comments
Please log in or register to join the discussion