The Blackwell Ultra GPU marks a fundamental shift in Nvidia's approach to computational precision, reversing fifteen years of deliberate double-precision limitations on consumer hardware.
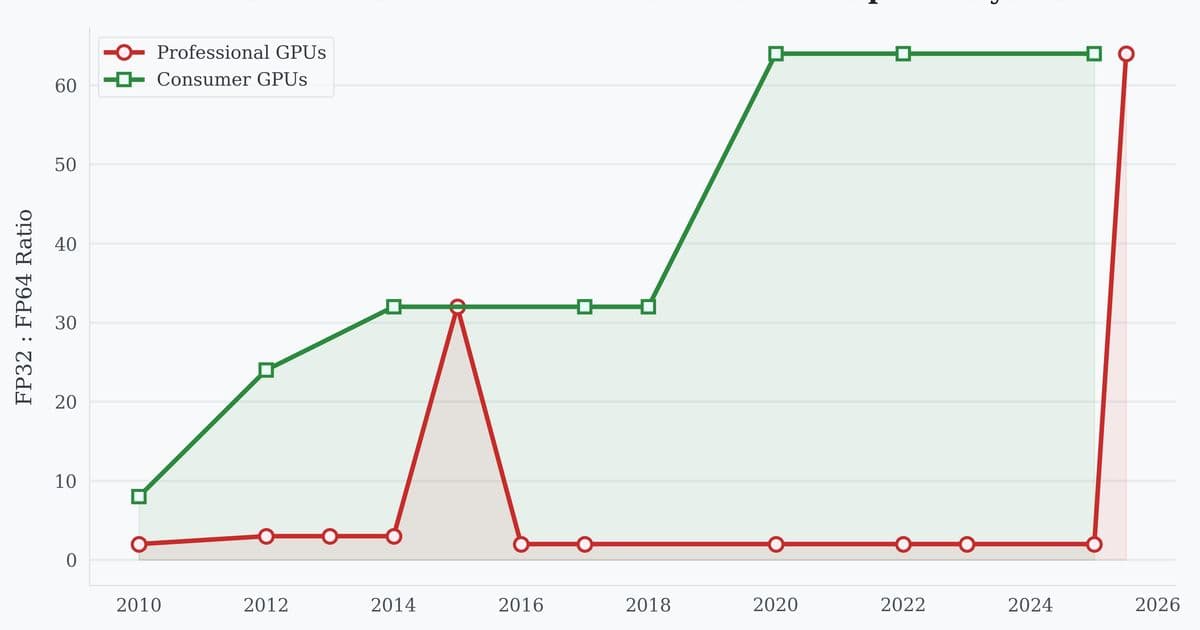
For fifteen years, Nvidia systematically widened the performance gap between single-precision (FP32) and double-precision (FP64) computing on consumer GPUs. Where the 2010 Fermi architecture maintained a 1:8 FP64-to-FP32 ratio, today's RTX 5090 stretches this to 1:64 - enabling 104.8 TFLOPS for gaming-focused workloads while throttling scientific computation to just 1.64 TFLOPS. This wasn't accidental. It represented sophisticated market segmentation: enterprise GPUs commanded 20x price premiums partly through superior FP64 performance essential for computational fluid dynamics, climate modeling, and financial simulations.
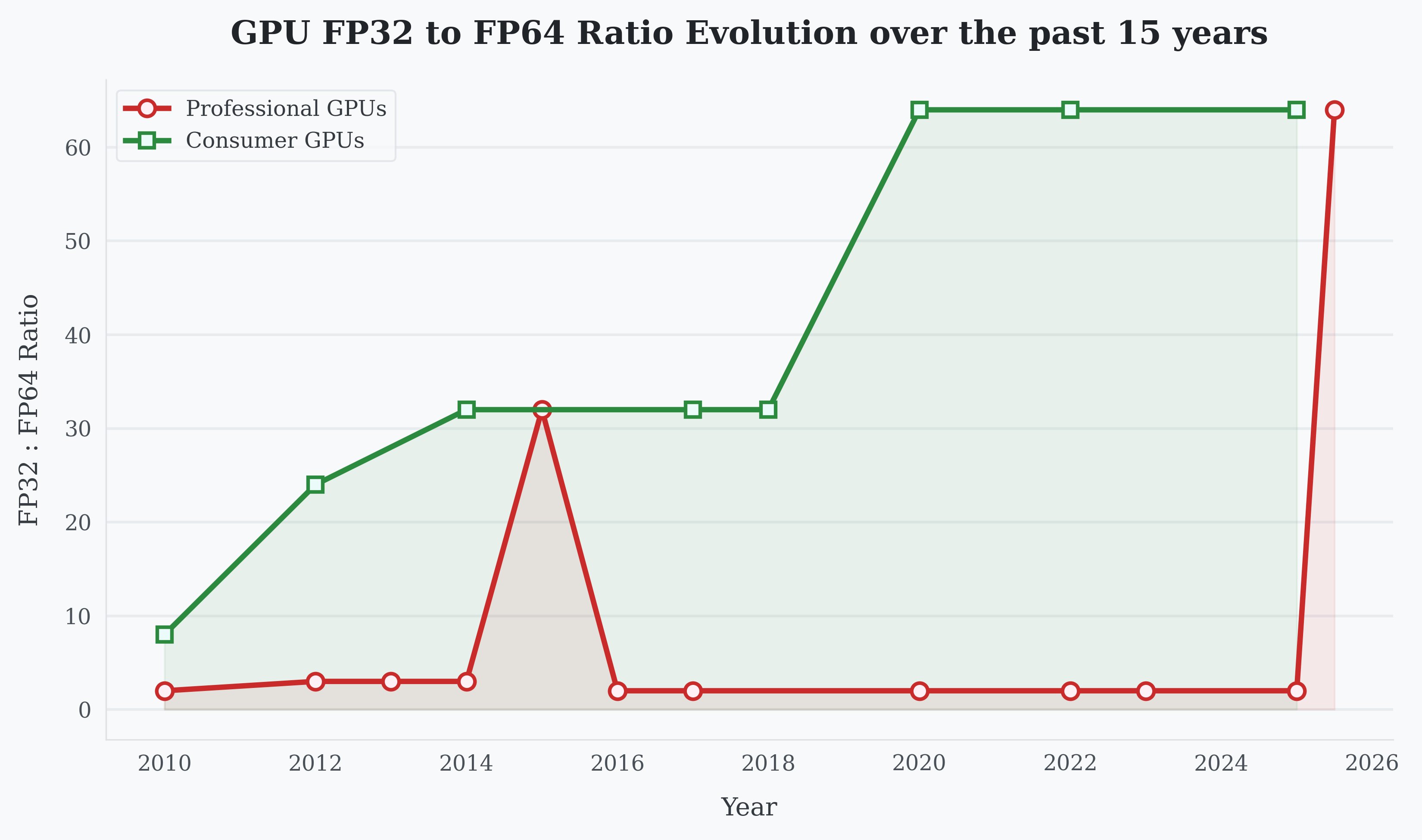 FP32 versus FP64 throughput scaling on Nvidia consumer GPUs over time
FP32 versus FP64 throughput scaling on Nvidia consumer GPUs over time
Between 2010's GTX 480 and 2025's RTX 5090, FP32 performance surged 77x while FP64 crawled forward just 9.65x. The segmentation logic held until generative AI rewrote the rules. Modern AI training thrives on lower precisions (FP16-BF16-FP8), making consumer GPUs unexpectedly capable for serious workloads. Nvidia responded with controversial licensing restrictions, but technological innovation proved harder to contain.
Enter FP64 emulation techniques. Methods like Dekker's double-float arithmetic (1971) split 64-bit values into two FP32 components: a high-precision anchor and low-precision correction term. Andrew Thall later adapted these for GPUs, trading 5 bits of precision for substantially higher throughput. The breakthrough came via tensor cores. The Ozaki scheme decomposes FP64 matrices into FP8 slices, leveraging AI-optimized hardware for distributed computation reassembled into full-precision results.
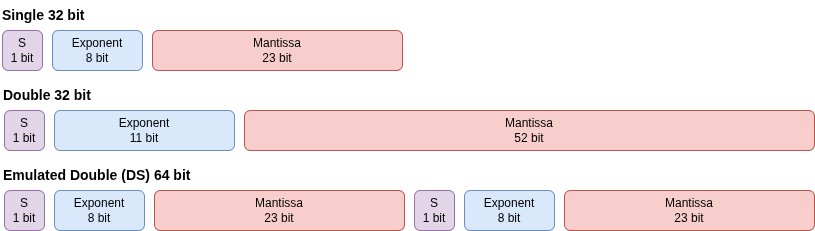 Emulated double representation using high and low FP32 parts
Emulated double representation using high and low FP32 parts
Nvidia integrated Ozaki scheme support into cuBLAS in 2025, coinciding with Blackwell Ultra's radical departure. The enterprise-focused B300 slashes native FP64 performance to 1.2 TFLOPS (1:64 ratio), mirroring consumer constraints while quadrupling FP4 tensor cores. This inversion reflects AI's dominance in enterprise revenue: segmentation now occurs along precision axes that matter to neural networks.
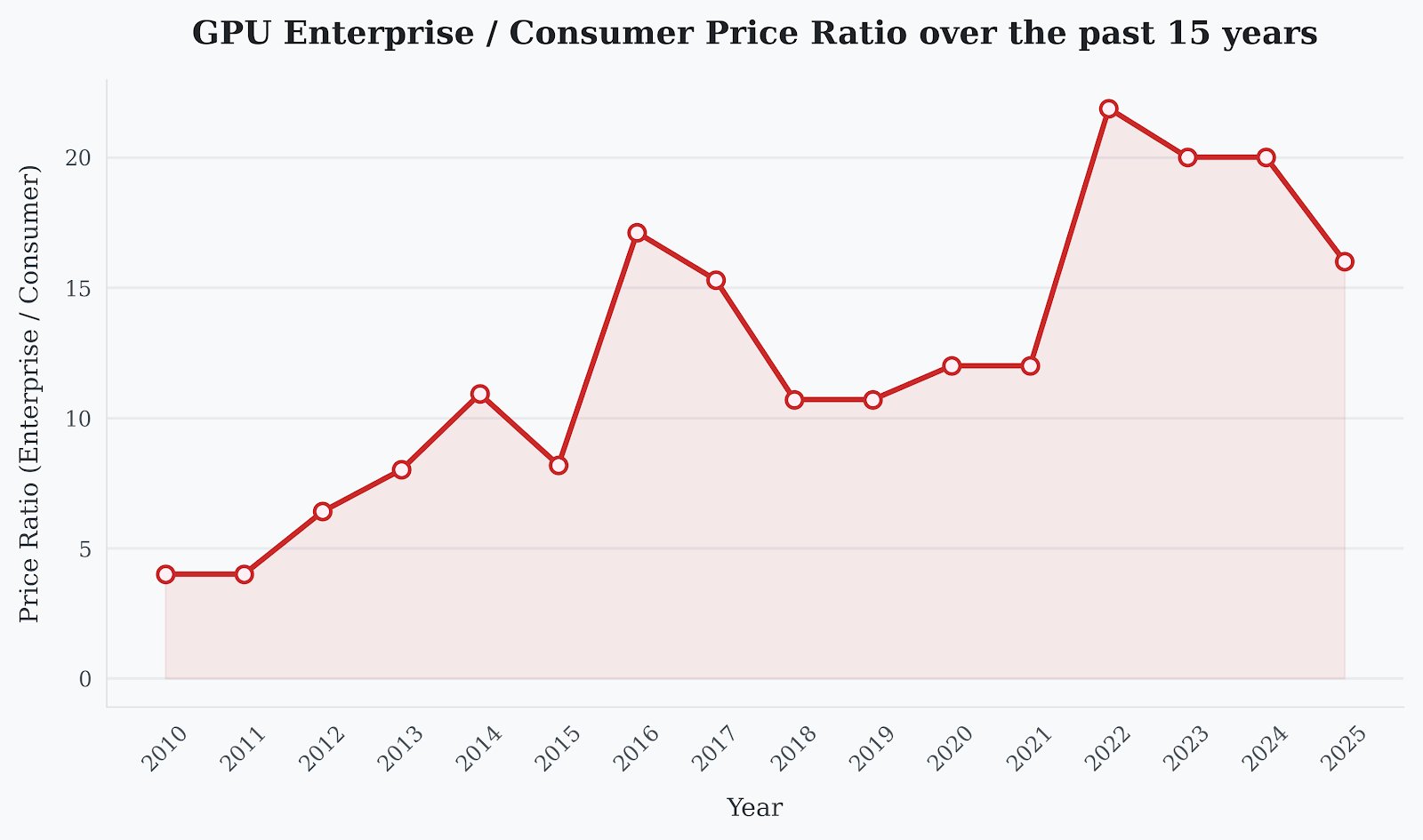 Enterprise vs consumer GPU price ratio over time
Enterprise vs consumer GPU price ratio over time
Market segmentation hasn't disappeared - it migrated. Where FP64 once divided consumer and enterprise silicon, the new frontier emerges in ratios like the RTX 5090's 1:1 FP16:FP32 versus B200's 16:1. Nvidia insists they're not abandoning hardware FP64, but the Blackwell pivot proves that emulation and AI-driven architectures have permanently altered compute economics. Fifteen years of carefully constructed segmentation eroded not by consumer demand, but by the unintended consequences of the AI tsunami.
References
Comments
Please log in or register to join the discussion