
As open-source models and inference engines erode proprietary API advantages, engineers must optimize for distinct workload types—offline (batch), online (interactive), and semi-online (bursty)—each requiring specialized infrastructure trade-offs.

The dominance of flat-rate LLM APIs is unraveling. Proprietary services from OpenAI and others once offered simplicity through standardized pricing, but they obscured critical engineering trade-offs beneath their per-token costs. Two seismic shifts are driving change: open-source models like DeepSeek and Alibaba Qwen now rival proprietary capabilities, while inference engines such as vLLM and SGLang democratize high-performance serving. This convergence demands engineers architect systems around workload-specific requirements rather than outsourcing complexity.
The Three Tribes of LLM Workloads
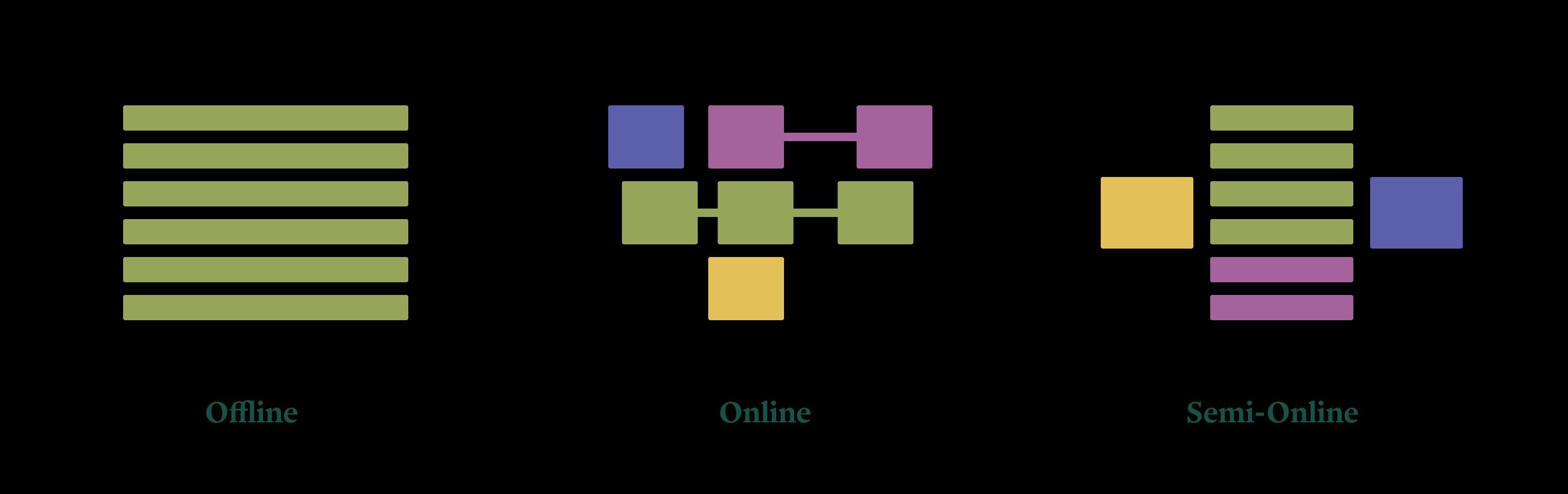 Drawing parallels to database paradigms (OLTP vs. OLAP), LLM workloads split into three distinct categories:
Drawing parallels to database paradigms (OLTP vs. OLAP), LLM workloads split into three distinct categories:
- Offline (Batch): High-throughput tasks like bulk summarization or dataset enrichment. These prioritize cost efficiency via parallelism, tolerate latency, and write asynchronously to storage.
- Online (Interactive): Human-facing applications like chatbots or coding assistants. These demand sub-second latency, handle multi-turn state, and require minimal host overhead.
- Semi-Online (Bursty): Pipeline-driven agents processing variable loads (e.g., document ingestion during peak hours). These need rapid autoscaling to manage unpredictable traffic spikes.
Offline: The Throughput Game
Batch workloads thrive on maximizing tokens per dollar. The core challenge lies in GPU saturation through intelligent batching. vLLM excels here via:
- Mixed batching: Scheduling compute-intensive prefill phases alongside lighter decode tasks
- Chunked prefill: Breaking prompts into segments for finer-grained parallelism
- Async execution: Using Python SDKs instead of HTTP servers to queue large job batches
 Implementation requires minimizing GPUs per replica just enough to saturate large batches. Excess capacity should spawn parallel replicas. This approach exploits older, cheaper GPUs since FLOPs/dollar remains constant across generations—critical for cost-sensitive batch operations. Sample implementations demonstrate vLLM batch optimizations on Modal.
Implementation requires minimizing GPUs per replica just enough to saturate large batches. Excess capacity should spawn parallel replicas. This approach exploits older, cheaper GPUs since FLOPs/dollar remains constant across generations—critical for cost-sensitive batch operations. Sample implementations demonstrate vLLM batch optimizations on Modal.
Online: War on Latency
Interactive systems battle physics to deliver human-response speeds. Key challenges include:
Host Overhead
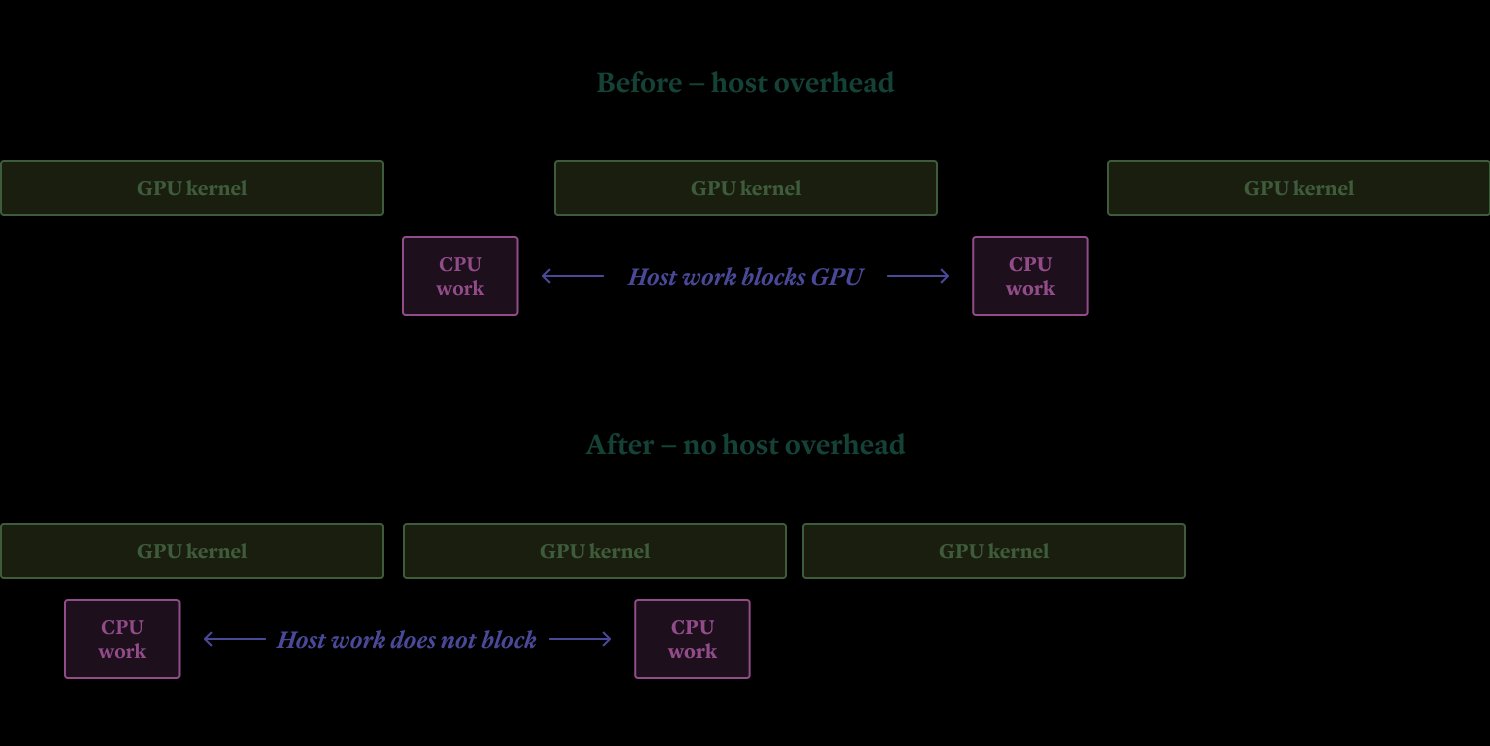 Python-based engines risk CPU operations blocking GPU work. SGLang mitigates this better than alternatives, reducing delays before tokens hit the wire.
Python-based engines risk CPU operations blocking GPU work. SGLang mitigates this better than alternatives, reducing delays before tokens hit the wire.
Memory Bandwidth Walls Autoregressive generation suffers under memory bandwidth limits. Solutions include:
- Tensor parallelism: Distributing matrix math across NVLink-connected GPUs
- Quantization: FP8 (Hopper) or FP4 (Blackwell) to shrink model footprints
- Speculative decoding: Using smaller "draft" models (e.g., EAGLE-3) to predict token sequences validated in parallel
 SGLang’s support for EAGLE-3 enables latency comparable to proprietary stacks. Regional edge deployments combat network delays, while session-based routing preserves KV caches across multi-turn chats. See interactive serving patterns on Modal.
SGLang’s support for EAGLE-3 enables latency comparable to proprietary stacks. Regional edge deployments combat network delays, while session-based routing preserves KV caches across multi-turn chats. See interactive serving patterns on Modal.
Semi-Online: Taming the Burst
Bursty workloads create an economic paradox: costs scale with peak demand, but value derives from averages. Solutions involve:
- Multitenancy: Aggregating uncorrelated workloads to smooth aggregate demand
- Cold start slashing: GPU snapshotting bypasses JIT compilation by restoring pre-initialized states
- Aggressive autoscaling: Instantly provisioning capacity during traffic surges
Without optimization, container startups take minutes; snapshots cut this to seconds. The choice between vLLM and SGLang hinges on model compatibility, but both benefit from Modal’s scaling policies.
Counterpoints and Trade-offs
The API exodus isn’t universal. Proprietary services still hold value for:
- Teams lacking infrastructure expertise
- Applications where marginal latency differences outweigh operational overhead
- Access to frontier models without hosting complexity
Additionally, Modal’s recommendations involve trade-offs:
- Tensor parallelism increases hardware costs for latency gains
- Quantization risks quality degradation in smaller models
- Snapshotting requires code adjustments for state serialization
The Agent-Driven Future
While chatbots dominate today, long-running autonomous agents (e.g., Claude Code) represent the next frontier. These patient systems will favor semi-online patterns, shifting focus from human latency tolerance to economic burst handling. As inference commoditizes, workload-aware architectures—not standardized APIs—will define competitive advantage.
Modal provides tools for each workload type. Explore their LLM deployment guides and GPU snapshotting documentation.
Comments
Please log in or register to join the discussion