
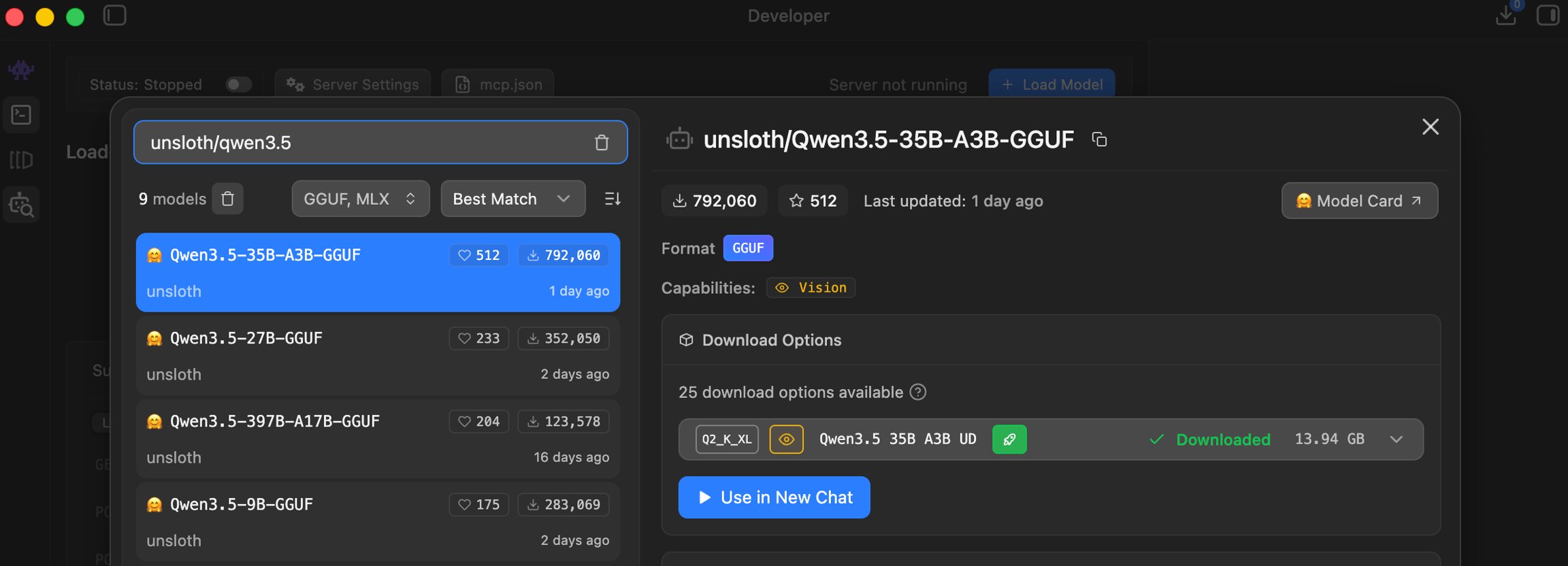
Unsloth has published an extensive documentation guide enabling developers to run Alibaba's new Qwen3.5 model family locally across various hardware configurations, making these powerful multimodal LLMs more accessible to the developer community.
Alibaba's Qwen3.5 model family has quickly gained attention for its impressive performance across various benchmarks, and now Unsloth has made these powerful models significantly more accessible with a comprehensive local running guide. The documentation provides detailed instructions for developers to run everything from the small 0.8B parameter model up to the massive 397B-A17B variant on their own hardware.

Qwen3.5 represents Alibaba's latest advancement in large language models, available in multiple sizes including 0.8B, 2B, 4B, 9B, 27B, 35B-A3B, 122B-A10B, and 397B-A17B. These multimodal hybrid reasoning LLMs deliver strong performance for their sizes, supporting 256K context across 201 languages, with capabilities in agentic coding, vision, chat, and long-context tasks.
"The 35B and 27B models work on a 22GB Mac / RAM device, which makes these powerful models accessible to many developers who previously couldn't run similar-sized LLMs locally," notes the documentation. "This democratizes access to state-of-the-art AI capabilities without relying on cloud services."
The guide details hardware requirements for each model size, with quantization options ranging from 2-bit to 8-bit, allowing developers to balance performance and resource constraints. For example, the 397B-A17B model can run on a single 24GB GPU + 256GB system RAM via MoE offloading, achieving 25+ tokens/s performance.
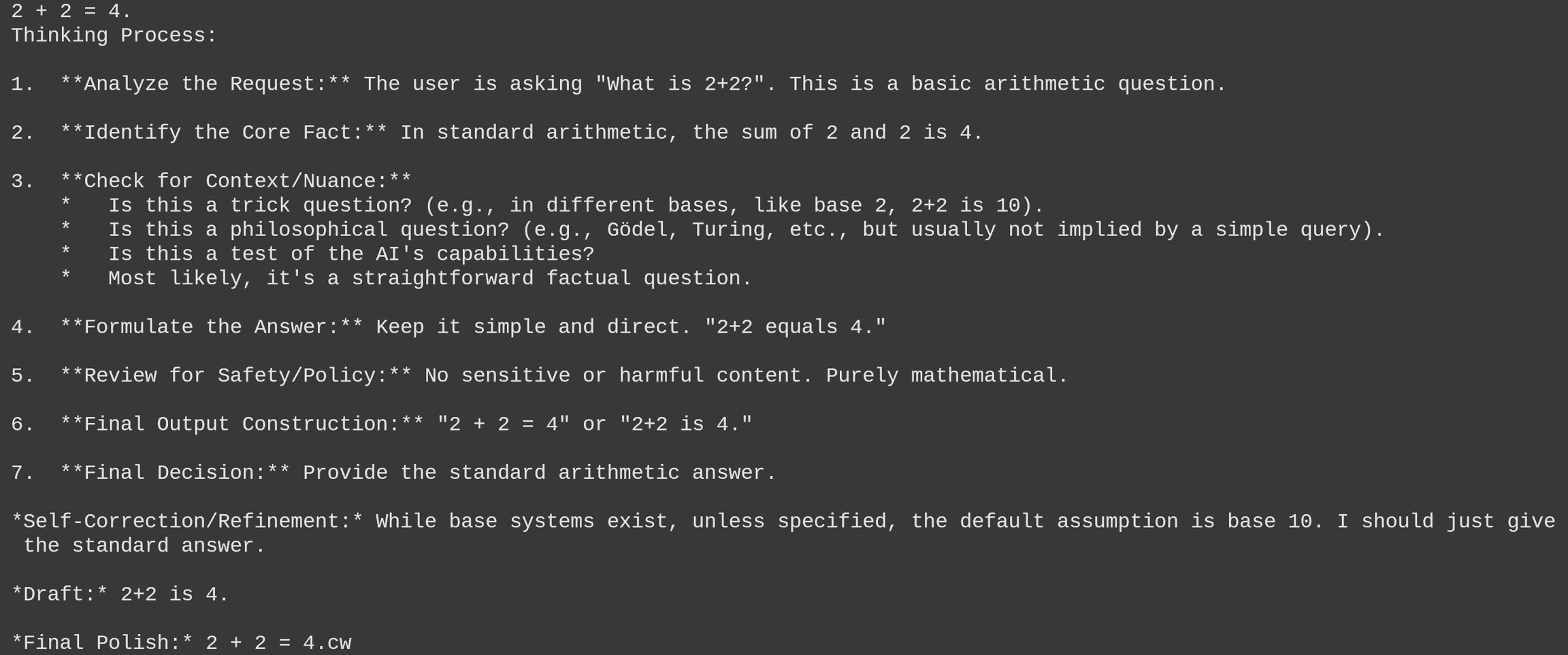
A significant aspect of the guide is the detailed explanation of Qwen3.5's "thinking" mode, which can be enabled or disabled based on the use case. The documentation provides specific parameter recommendations for different scenarios:
- Thinking mode for general tasks: temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
- Thinking mode for precise coding tasks: temperature=0.6, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0
- Instruct (non-thinking) mode for general tasks: temperature=0.7, top_p=0.8, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
The Unsloth team has implemented several technical optimizations in their GGUF (GPT-Generated Unified Format) versions of Qwen3.5. They've updated all GGUFs with an improved quantization algorithm using new imatrix data, resulting in better performance in chat, coding, long context, and tool-calling use-cases. They've also fixed a tool-calling chat template bug that affects all quant uploaders.
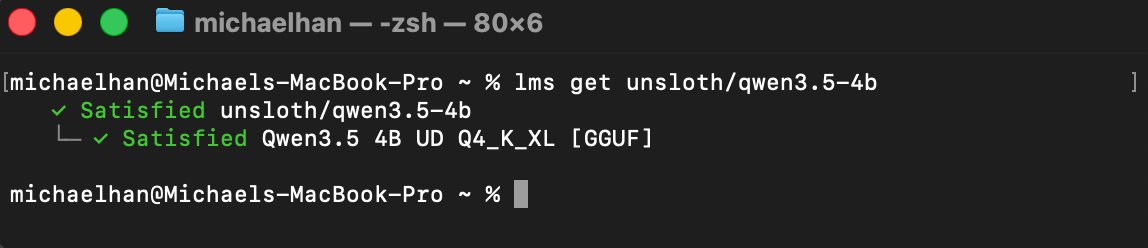
"We're retiring MXFP4 layers from 3 Qwen3.5 GGUFs: Q2_K_XL, Q3_K_XL and Q4_K_XL. All uploads use Unsloth Dynamic 2.0 for SOTA quantization performance - so 4-bit has important layers upcasted to 8 or 16-bit," the documentation explains.
The guide includes benchmarks showing that Unsloth's dynamic quantization methods maintain impressive accuracy even at lower bit depths. For the massive 397B-A17B model, UD-Q4_K_XL maintains 80.5% accuracy compared to the original 81.3%, with just a 0.8-point drop and only 4.3% relative error increase.
Developers can follow the step-by-step instructions to set up llama.cpp, download appropriate quantized versions of the models, and run them locally. The guide covers different scenarios including conversation mode, tool calling, and integration with OpenAI's completion library for production deployments.

For developers working with smaller hardware, the Qwen3.5 Small series (0.8B, 2B, 4B, 9B) offers an entry point, with reasoning disabled by default to optimize resource usage. The documentation notes that reasoning can be enabled when needed using specific chat template parameters.
The availability of such detailed local running documentation represents a significant step forward in making state-of-the-art AI models more accessible to developers and researchers. By providing clear instructions for running these models on consumer hardware, Unsloth is helping to democratize access to advanced AI capabilities that were previously limited to organizations with substantial cloud computing resources.
For developers interested in exploring Qwen3.5 locally, the complete guide is available in the Unsloth documentation, with direct links to model downloads and implementation examples. The documentation includes troubleshooting tips for common issues and guidance on optimizing performance for specific use cases.
Comments
Please log in or register to join the discussion