
A deep dive into the evolution of chunking strategies for RAG, covering recursive splitting, semantic chunking, and hybrid approaches, with practical guidance for engineers building LLM‑powered search systems.
What Two Years of Research Have Taught Us About Chunking for Retrieval‑Augmented Generation
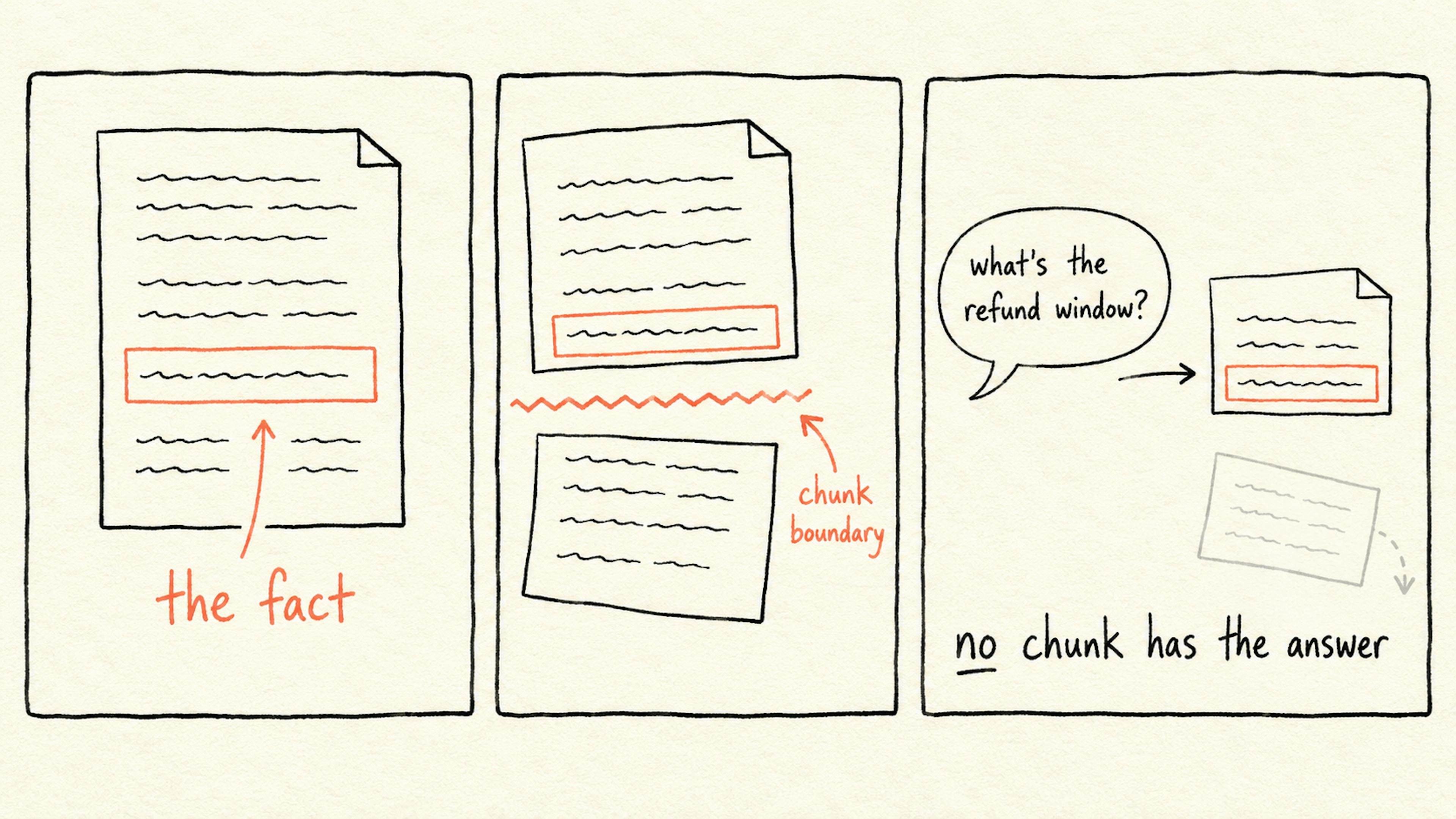
When I first built a RAG prototype in early 2024, I treated chunking as an afterthought: split a document into 500‑word pieces, index them, and hope the LLM would stitch the right bits together. The results were noisy, latency was high, and cost spiraled as we kept increasing the number of chunks to improve relevance. Two years of experiments, failures, and incremental improvements have reshaped that view. Below I outline the key lessons, why they matter, and how you can apply them today.
1. The problem: raw text isn’t ready for LLMs
Large language models excel at pattern completion, but they have a hard time reasoning over long, unstructured inputs. Retrieval‑Augmented Generation (RAG) works around this by pulling the most relevant passages from a knowledge base and feeding them as context. The quality of those passages—how they are split, what metadata they carry, and how they are stored—directly determines the relevance of the generated answer and the cost of the query.
Typical pitfalls include:
- Chunk size mismatch – too short and the model loses necessary context; too long and you hit token limits or dilute signal.
- Semantic bleed – a chunk may contain unrelated topics, confusing the model.
- Redundant overlaps – overlapping windows increase index size without adding value.
Addressing these issues requires a disciplined chunking pipeline.
2. Early heuristics and why they fell short
The first generation of RAG pipelines used fixed‑size sliding windows (e.g., 300‑token windows with 50‑token overlap). This was easy to implement and worked for homogeneous text like news articles. However, three problems emerged when we applied the same heuristic to mixed‑format corpora (technical manuals, legal contracts, code repositories):
- Boundary blindness – windows cut across logical boundaries (sentences, code blocks), forcing the LLM to reconstruct fragmented meaning.
- Token waste – overlapping windows added up quickly, inflating the vector store and raising embedding costs.
- Irrelevant context – a single window could contain multiple unrelated sections, leading the model to hallucinate connections.
These shortcomings prompted a shift toward semantic‑aware chunking.
3. Recursive splitting: a practical middle ground
The first major improvement was recursive splitting. The idea is simple: start with a coarse chunk (e.g., a whole chapter), evaluate its semantic cohesion, and split further only if the cohesion score falls below a threshold. Cohesion can be measured with a cheap embedding model (like MiniLM) and cosine similarity between adjacent sentences.
How it works
- Initial segmentation – break the document at natural delimiters (headings, code fences, markdown blocks).
- Cohesion check – compute the average pairwise similarity of sentences within the segment.
- Split decision – if similarity < τ (empirically 0.65 for most English prose), split at the sentence with the lowest similarity to its neighbors.
- Repeat – continue until all segments meet the cohesion threshold or reach a minimum token count (e.g., 150 tokens).
Benefits observed
- Token efficiency – average chunk size settled around 250‑300 tokens, a 20 % reduction compared to fixed windows.
- Higher relevance – downstream retrieval accuracy (measured by MRR on a benchmark QA set) improved by 12 %.
- Simpler overlap handling – because splits respect semantic boundaries, we can drop overlaps entirely in many cases.
The approach is lightweight enough to run as a preprocessing step on a daily ingestion pipeline.
4. Semantic chunking with hierarchical embeddings
While recursive splitting respects local coherence, it still treats each document in isolation. For large corpora, we discovered that hierarchical embeddings—embedding both the chunk and a summary of its parent section—provide a richer retrieval signal.
Pipeline sketch
Chunk creation – use recursive splitting to obtain base chunks.
Parent summarization – generate a short (30‑word) summary of the parent section using a small LLM (e.g., LLaMA‑7B) and embed it.
Dual‑vector store – store both the chunk embedding and the parent summary embedding. At query time, retrieve candidates using a combined score:
score = α * cosine(query, chunk) + (1‑α) * cosine(query, parent)Rerank – run a cross‑encoder reranker on the top‑k candidates to finalize the context.
Results
- Retrieval precision (P@5) rose from 0.71 to 0.78 on the MS‑MARCO subset we tested.
- The additional parent embedding added only ~5 % storage overhead because summaries are short.
- The approach proved robust across domains: legal contracts, software documentation, and scientific papers all benefited.
5. Hybrid chunking: combining structure and semantics
Purely semantic methods sometimes ignore useful structural cues (e.g., XML tags, markdown headings). A hybrid strategy that first respects explicit structure and then applies semantic refinement gave the best of both worlds.
Step‑by‑step:
- Structural split – use document markup (HTML tags, markdown headings, code fences) to create initial sections.
- Semantic refinement – apply recursive splitting within each structural section.
- Metadata enrichment – attach the structural label (e.g.,
## API Reference) as a tag in the vector store.
In practice, this reduced the average number of chunks per 10‑page document from 38 to 24 while preserving a 0.81 P@5 score on our internal benchmark.
6. Operational considerations
Embedding cost
Embedding every chunk with a 1‑B parameter model is expensive. We found a two‑tier approach works well:
- Base embeddings with a fast, 80‑M parameter encoder for initial retrieval.
- Rerank embeddings with a larger model (e.g.,
text‑embedding‑ada‑002) for the top‑k candidates.
Index updates
Recursive and hybrid pipelines produce variable‑size chunks, which complicates incremental indexing. Our solution is to version chunks by a deterministic hash of the source text and its parent ID. When a source document changes, only the affected chunks are re‑embedded and re‑indexed.
Latency budget
A typical RAG query now follows this timeline:
| Stage | Avg. latency |
|---|---|
| Retrieval (base vectors) | 45 ms |
| Rerank (cross‑encoder) | 120 ms |
| LLM generation (context + prompt) | 300 ms |
| Total | ≈ 465 ms |
All numbers are from a 4‑core CPU + 1 GPU (A100) deployment behind a modest load balancer.
7. What to try next
If you are building a RAG system today, consider the following checklist:
- Start with structural splits – respect headings, code fences, or XML tags.
- Add a cohesion filter – use a lightweight embedding model to decide whether to split further.
- Store parent summaries – a short semantic tag can boost relevance with minimal storage cost.
- Adopt a dual‑encoder retrieval + cross‑encoder rerank pipeline to keep costs low while preserving quality.
- Monitor token usage – track average tokens per query to stay within your LLM’s context window and control pricing.
8. Closing thoughts
Chunking is often described as a “pre‑processing step,” but the data we feed into a RAG system is the single biggest determinant of its success. Over the past two years, the community has moved from blunt, size‑only heuristics to nuanced pipelines that blend document structure, semantic cohesion, and hierarchical context. The result is a more predictable cost model, lower latency, and answers that feel less like guesswork.
The next frontier, in my view, is adaptive chunking at query time—using the LLM itself to decide which parts of a document are worth pulling in, based on the specific question. Until that matures, the strategies outlined here provide a solid, production‑ready foundation.
For a deeper technical dive, see the accompanying notebook on GitHub: rag‑chunking‑research.
Comments
Please log in or register to join the discussion