A hands-on course and implementation for building a simplified LLM inference engine from scratch, focusing on practical CUDA programming and understanding the fundamentals of high-performance inference.
tiny-vllm: Building Your Own LLM Inference Engine
jmaczan/tiny-vllm presents an educational approach to implementing a high-performance LLM inference engine using C++ and CUDA. Rather than another production-grade inference system, this project offers a learning resource that walks developers through implementing a simplified version of systems like vLLM from the ground up.
What tiny-vllm Actually Is
At its core, tiny-vllm is both a complete implementation and a course focused on teaching how to build an LLM inference engine. The project specifically targets the Llama 3.2 1B Instruct model, providing a concrete example that learners can follow and implement. The engine includes:
- Loading models from Safetensors format
- Complete LLM forward pass (prefill and decode phases)
- CUDA kernels for core operations
- KV cache implementation
- Static and continuous batching
- Online softmax and PagedAttention-like mechanisms
The educational aspect is central to this project. The author, Jędrzej Maczan, structures the repository to guide learners through implementing each component step-by-step, explaining the underlying concepts and implementation decisions along the way.
Technical Implementation Details
Model Loading and Architecture
tiny-vllm loads models from the Safetensors format, which consists of three sections: header size, header (JSON), and tensor data. The implementation focuses specifically on the Llama 3.2 1B Instruct architecture, which includes:
- Embedding layer (128256 tokens, 2048 dimensions)
- 16 transformer layers with:
- RMS normalization
- Grouped-query attention (GQA)
- Rotary position embeddings (RoPE)
- Feed-forward networks with SiLU activation
- Output layer with linear projection and argmax
The project provides a clear implementation path for understanding LLM architecture components
CUDA Kernel Development
The implementation emphasizes CUDA programming for performance-critical operations. Key kernels include:
Embedding Gathering: Retrieves embeddings for input tokens using optimized CUDA kernels that handle the 1024-thread block limitation by processing two values per thread.
RMSNorm: Implements root mean square normalization with a tree reduction algorithm for parallel computation across GPU threads.
Matrix Operations: Leverages cuBLAS for high-performance matrix multiplication, with careful handling of row-major to column-major conversions.
Attention Mechanisms: Implements attention with causal masking, softmax, and GQA optimizations.
Precision and Numerical Stability
tiny-vllm uses bfloat16 precision for model weights and computations. The project explains the rationale behind this choice:
- bfloat16 provides the same exponent range as float32 (8 bits) with only 7 bits of fraction (vs 10 in float16)
- This reduces the likelihood of overflow/underflow while maintaining acceptable precision for LLM inference
- The implementation includes careful handling of numerical stability, such as adding epsilon values to prevent division by zero in normalization operations
Performance Optimizations
Several optimization techniques are implemented:
- Buffer Reuse: Memory buffers are reused when their lifetimes don't overlap, reducing memory allocation overhead
- Static Batching: Processes multiple requests simultaneously, improving throughput at the cost of latency
- Continuous Batching: Dynamically replaces completed requests with new ones, reducing idle time
- Online Softmax: An implementation of softmax that computes results incrementally
What's Actually New vs. What's Claimed
While the project describes itself as a "high-performance LLM inference engine," its primary contribution is educational rather than algorithmic or architectural innovation. The implementation follows established patterns from systems like vLLM but provides:
- Simplified Implementation: A more manageable codebase for learning purposes
- Detailed Explanations: Thorough explanations of each component and implementation decisions
- Hands-on Course: A structured learning path that complements the implementation
- Concrete Examples: Focused implementation for a specific model (Llama 3.2 1B)
The project doesn't introduce novel algorithms or techniques but rather provides a clear implementation of existing approaches in an educational context.
Limitations and Practical Considerations
Several limitations are worth noting:
- Model Specificity: The implementation is tailored to Llama 3.2 1B Instruct, requiring significant modifications for other architectures
- Hardware Constraints: Limited by GPU constraints like maximum threads per block (1024 for most consumer GPUs)
- Scalability: Doesn't support model parallelism or distributed inference needed for larger models
- Production Readiness: Lacks features needed for production systems like advanced error handling, monitoring, or deployment tools
- Precision Trade-offs: bfloat16, while efficient, may not be suitable for all applications requiring higher precision
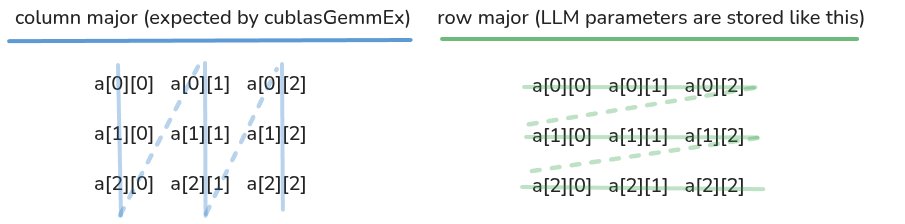
Understanding memory layouts and data structures is crucial for efficient implementation
Learning Path and Prerequisites
The project assumes several prerequisites:
- C++ programming experience
- CUDA programming knowledge
- Understanding of deep learning fundamentals
- Familiarity with linear algebra concepts
The implementation follows a logical progression from basic operations (embedding retrieval) to complex components (attention mechanisms), making it suitable for developers looking to deepen their understanding of LLM inference implementation.
Conclusion
tiny-vllm serves as a valuable educational resource for developers seeking to understand the practical implementation of LLM inference systems. By focusing on a specific model and providing detailed explanations, the project bridges the gap between high-level overviews of LLM inference and the low-level implementation details.
While not a replacement for production systems like vLLM or TensorRT, it offers a hands-on approach to learning the core concepts and optimization techniques used in high-performance LLM inference. The combination of complete source code and structured course materials makes it particularly valuable for educators, students, and developers looking to deepen their understanding of LLM inference implementation.
For those interested in exploring the implementation, the complete source code and course materials are available at https://github.com/jmaczan/tiny-vllm.
Comments
Please log in or register to join the discussion