A comprehensive analysis of seven context management approaches for GPT Realtime in production environments, examining their trade-offs in token usage, cache efficiency, and latency across different conversational AI use cases.
Optimizing GPT Realtime Context Strategies: From Development to Production
Enterprise customers building production voice and conversational AI on gpt-realtime consistently face a critical decision point once they move beyond proof-of-concept: how to optimize their prompt caching strategy to scale from 100 calls a day to 100,000 without exploding their token bill or exceeding their latency budget. Caching represents the highest-leverage optimization opportunity in the realtime API—cached audio input costs 99% less than uncached input, but achieving stable prefix caching requires deliberate architectural decisions.
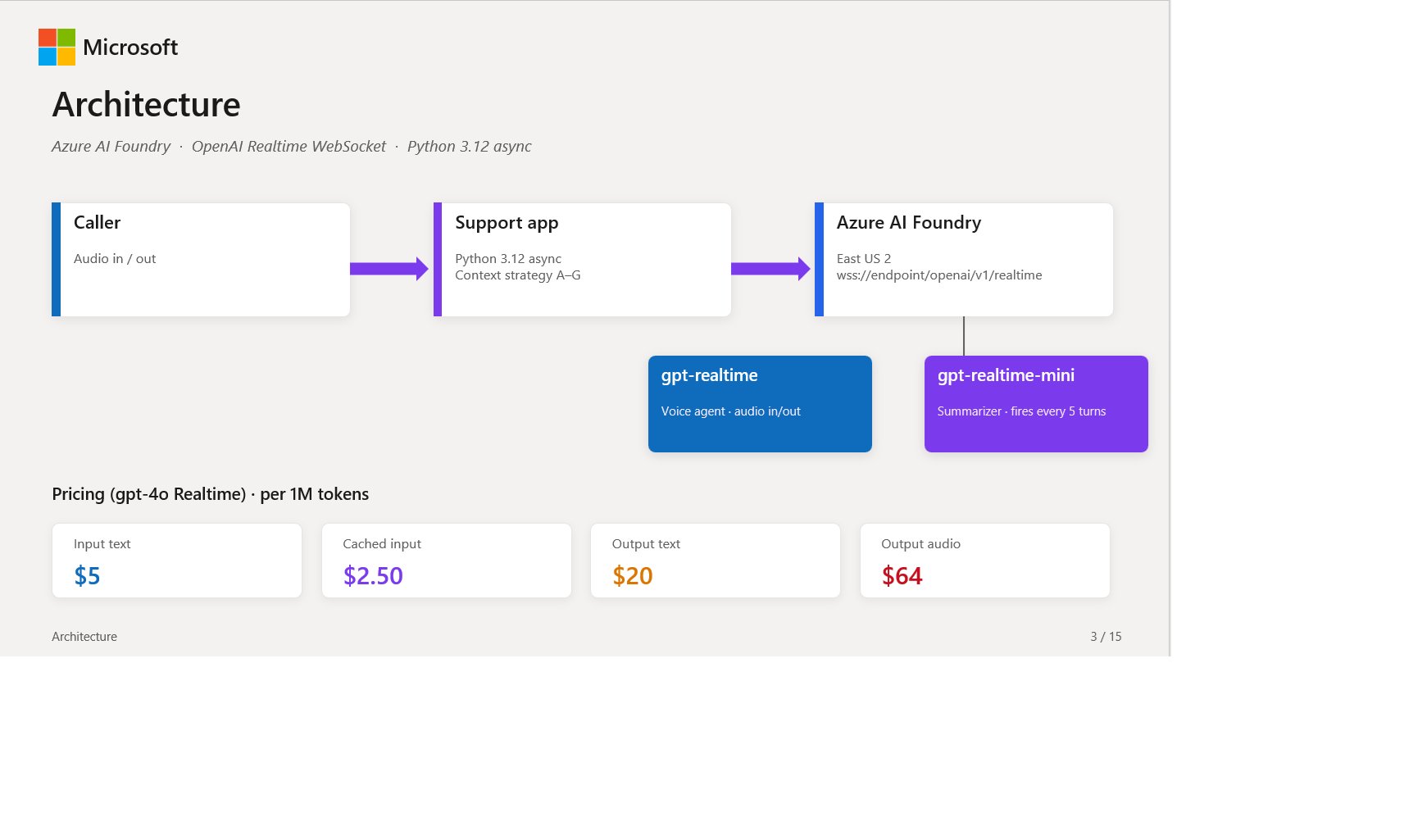
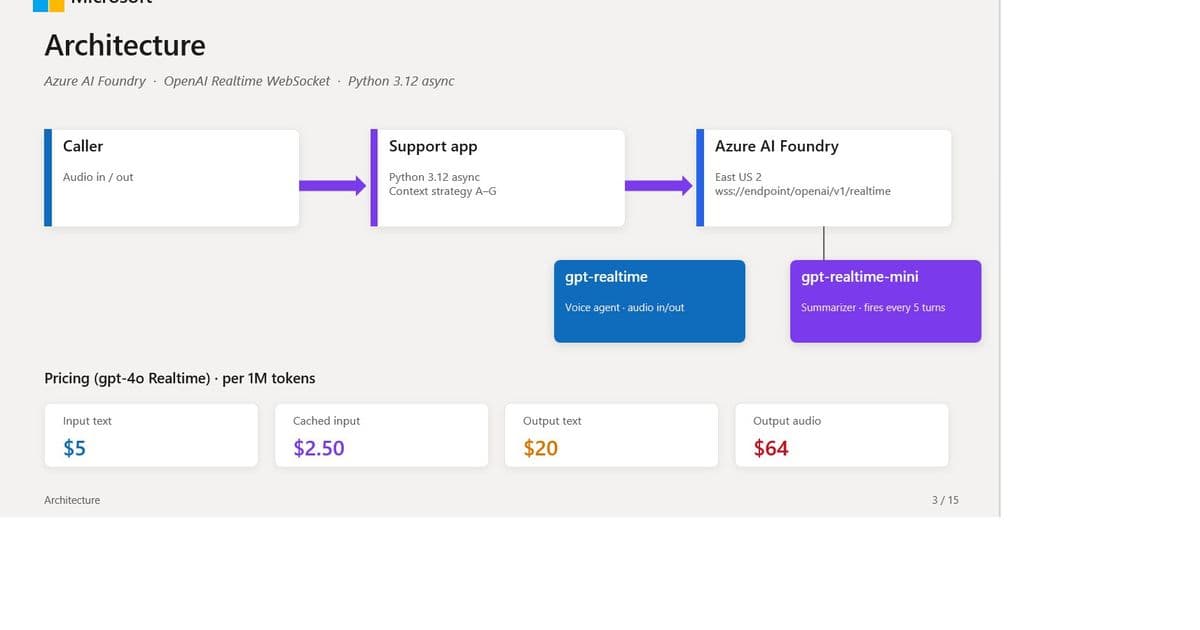
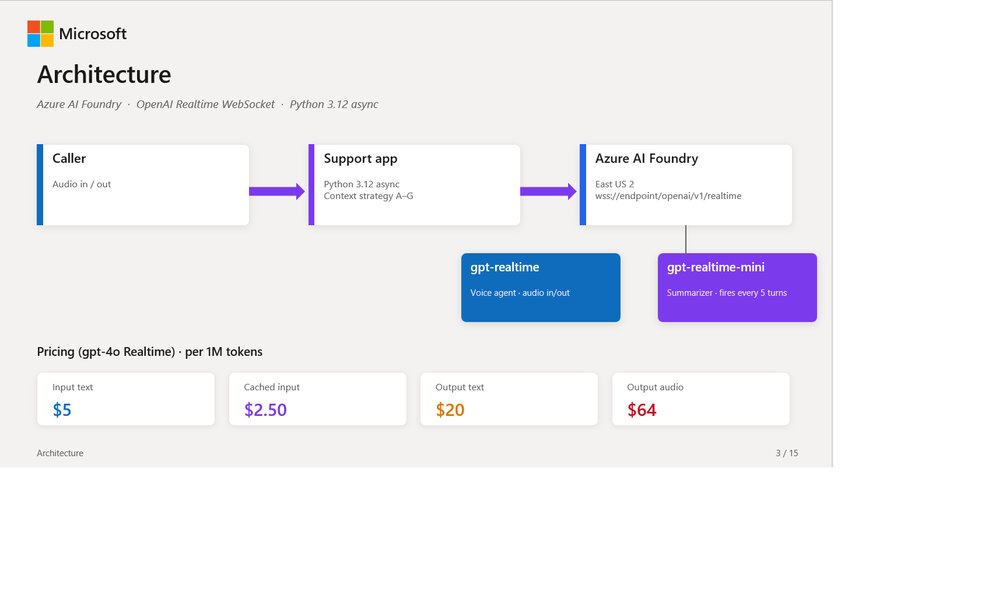
The Context Management Challenge
When deploying gpt-realtime through platforms like Azure AI Foundry, organizations inevitably confront the question: how should we manage conversation context across turns? This implementation detail determines whether your per-call cost is 30 cents or 90 cents, whether your contact-center latency stays under two seconds, and whether customers need to repeat their account number multiple times during the same call.
Azure gpt-realtime pricing creates significant incentives for caching:
- $32/M for audio input
- $0.40/M for cached audio input (a ~99% discount)
- $64/M for audio output
The enormous cache discount means prefix stability becomes paramount. The strategies we'll examine represent different approaches to answering "what belongs in the prompt prefix on turn N?"
Seven Context Management Strategies Benchmarked
To provide concrete guidance, I tested seven strategies against a realistic 10-turn patient-onboarding conversation for a healthcare support scenario. The test used identical model, region, and system prompt—only the context management strategy varied.
A) Full History
- Implementation: Single persistent WebSocket; server retains every conversation item
- Token Count: 18,123 tokens
- Cache Hit Rate: 50.5%
- Pros: Perfect memory, simplest code implementation
- Cons: Worst tail latency (turn 6 took 6.3 seconds as prefix grew), single point of failure
- Best For: Short conversations where context retention is critical and latency can be tolerated
B) Stateless
- Implementation: Fresh WebSocket per turn; model sees only system prompt and current question
- Token Count: 6,557 tokens
- Cache Hit Rate: Low
- Pros: Minimal token usage, consistent performance
- Cons: Zero conversational memory
- Best For: Per-turn lookups where each interaction stands alone (e.g., pharmacist drug lookup, medication-adherence check-in)
C) Sliding Window
- Implementation: Fresh connection per turn with last 2 Q+A pairs injected
- Token Count: 8,655 tokens
- Cache Hit Rate: 20.4%
- Pros: Maintains short-term coherence
- Cons: Early conversation details lost by turn 5, cache rate drops due to moving prefix
- Best For: Conversations requiring immediate context but not long-term memory
D) Compression Every 5 Turns
- Implementation: gpt-realtime-mini produces ~70-word summary every 5 turns, replacing individual turns
- Token Count: 8,660 tokens
- Cache Hit Rate: 7.1%
- Pros: Semantic long-term memory survives (account numbers, original complaints)
- Cons: Each summary refresh invalidates the prefix
- Best For: Longer conversations where semantic preservation matters more than exact wording
E) Sliding + Compression (Hybrid)
- Implementation: Compressed summary of old turns in system prompt plus last 2 turns verbatim
- Token Count: 7,975 tokens
- Cache Hit Rate: 10.4%
- Pros: Covers both time scales ("earlier you mentioned..." and "wait, what did you just say?")
- Cons: More complex implementation
- Best For: Contact centers that tolerate reconnects and need both short and long-term context
F) Server-Side Truncation
- Implementation: Single persistent WebSocket with truncation config (drop oldest items when context exceeds 8,000 tokens)
- Token Count: 18,247 tokens
- Cache Hit Rate: 46.3%
- Pros: No client-side history code needed
- Cons: Cannot tune what gets dropped, cache breaks at trigger turn
- Best For: Safety net layered on another strategy, not primary pattern
G) In-Session Delete
- Implementation: Single persistent WebSocket throughout call; client summarizes oldest turns when token count exceeds threshold (600 in test)
- Token Count: 14,721 tokens
- Cache Hit Rate: 23.9%
- Pros: Maintains WebSocket connection, preserves recent context
- Cons: More complex implementation, requires client-side logic
- Best For: Production voice applications requiring persistent connections
Performance Analysis and Strategic Recommendations
The Token Volume Reality Check
Ranked by total token usage:
- Stateless (B): 6,557 tokens
- Sliding + Compression (E): 7,975 tokens
- Sliding Window (C): 8,655 tokens
- Compression Every 5 Turns (D): 8,660 tokens
- In-Session Delete (G): 14,721 tokens
- Full History (A): 18,123 tokens
- Server-Side Truncation (F): 18,247 tokens
Notably, the strategies with the highest cache hit rates (Full History at 50.5% and Server-Side Truncation at 46.3%) are also the most expensive. Cache hit rate is a vanity metric—a 50% discount on 18K tokens still costs more than a lower discount on 7K tokens. The number that pays your bill is total tokens.
Use Case-Based Recommendations
Per-Turn Lookup Applications (e.g., pharmacist drug lookup, IVR replacement)
- Recommended Strategy: Stateless (B)
- Rationale: When the workflow holds state and the LLM serves only as voice interface, eliminating conversational memory minimizes token usage without compromising functionality.
Short Conversations (3-10 turns)
- Recommended Strategy: Sliding Window (C) or Sliding + Compression (E)
- Rationale: These approaches balance context retention with token efficiency. The sliding window maintains recent context, while the hybrid approach adds long-term memory when needed.
Contact Center Interactions (10-30 turns)
- Recommended Strategy: Sliding + Compression (E)
- Rationale: The hybrid approach provides both short-term coherence and semantic long-term memory, making it ideal for complex customer interactions where context must span multiple topics.
Extended Conversations (30+ turns)
- Recommended Strategy: In-Session Delete (G)
- Rationale: For extended interactions where maintaining a persistent WebSocket connection is critical, this approach provides the best balance between context retention and token management.
Implementation Principles for Production Success
1. Start with Your Call Shape, Not the Leaderboard
A 3-turn lookup, a 10-turn support call, and a 30-turn escalation each have different optimal solutions. Select the strategy that fits your typical session pattern, not the one that wins an artificial benchmark.
2. Optimize for Total Tokens, Not Cache Hit Rate
Cache hit rate appears attractive but only discounts the cached portion of input. Total token volume drives both your bill and your latency. A high cache rate on a bloated context is worse than a modest cache rate on a tight one.
3. Treat the System Prompt as Sacred Prefix Space
Anything that changes turn-to-turn breaks the cache for everything after it. Structure your prompts with stable content (instructions, persona, long-term summary) first and volatile content (current turn, sliding window) last.
4. Decide Your Latency Posture Early
If you have a strict sub-2-second SLA, reconnect-based strategies are off the table. You need a pattern that maintains a single WebSocket for the entire call. If reconnects are acceptable, you typically have more options for token savings.
5. Use Server-Side Truncation as a Safety Net
Server-side truncation guarantees context can't grow unbounded, but with default thresholds it rarely fires on calls where you'd benefit. Implement it as a safety net layered on your primary strategy, not as your main approach.
6. Measure Before You Optimize
Instrument token counts per turn, cache hit rate, and end-to-end latency in production for at least a week before finalizing your strategy. Synthetic benchmarks, including this one, only approximate real customer conversations.
The Strategic Business Impact
Effective context management delivers three key business benefits:
Cost Optimization: The difference between Full History (18K tokens) and Sliding + Compression (8K tokens) represents a 56% reduction in input token costs, potentially saving thousands of dollars monthly at scale.
Performance Consistency: Strategies like In-Session Delete maintain sub-2-second latency even for extended conversations, directly impacting customer satisfaction metrics.
Operational Resilience: Architectures that preserve WebSocket connections through context management reduce failure points and improve system reliability.
For organizations implementing gpt-realtime in production, the context management strategy represents not just an implementation detail but a fundamental architectural decision with cascading implications for cost, performance, and user experience. By aligning your approach with your specific conversational patterns and business requirements, you can build systems that scale efficiently while maintaining the responsiveness customers expect.
For the complete benchmark implementation and testing code, refer to the GitHub repository.
Comments
Please log in or register to join the discussion