Liquid AI’s new LFM2.5-8B-A1B expands context length, doubles the tokenizer, and adds reasoning‑only training to deliver faster, lower‑hallucination assistant‑style inference on laptops and phones, while remaining competitive with much larger dense and MoE models.
LFM2.5-8B-A1B: A More Capable On‑Device Mixture‑of‑Experts Model
Liquid AI announced the release of LFM2.5-8B-A1B on May 28, 2026. The model is positioned as an edge‑friendly, reasoning‑oriented Mixture‑of‑Experts (MoE) that can run on consumer hardware while delivering tool‑calling capabilities comparable to far larger models. Below we unpack the technical upgrades, examine the benchmark evidence, and consider the push‑back from the community.
What changed from LFM2‑8B‑A1B?
| Feature | LFM2‑8B‑A1B | LFM2.5‑8B‑A1B |
|---|---|---|
| Context window | 32 K tokens | 128 K tokens |
| Tokenizer vocab | 65 K BPE tokens | 128 K tokens |
| Pre‑training data | 12 T tokens | 38 T tokens |
| Model type | MoE + GQA + gated short conv | Same architecture, reasoning‑only head |
| RL fine‑tuning | Standard RLHF | Targeted RL for hallucination reduction and doom‑loop mitigation |
The most visible change is the four‑fold increase in context length. By raising the RoPE base and running an extra 400 B token mid‑training stage, the model can ingest long documents (e.g., research papers, contracts) without chunking. Tokenizer expansion improves token‑per‑character ratios for non‑Latin scripts, with gains up to +238 % for Thai and +120 % for Hindi.
The architecture itself stays the same: a sparse MoE backbone that activates a small subset of experts per token, combined with grouped‑query attention (GQA) and short convolution blocks for local context. The novelty lies in the reasoning‑only training regime, where the model emits an explicit chain‑of‑thought before the final answer. This design exploits MoE’s compute‑bound nature—each reasoning token is cheap because only a few experts fire—yielding higher quality without sacrificing speed.
Benchmark performance
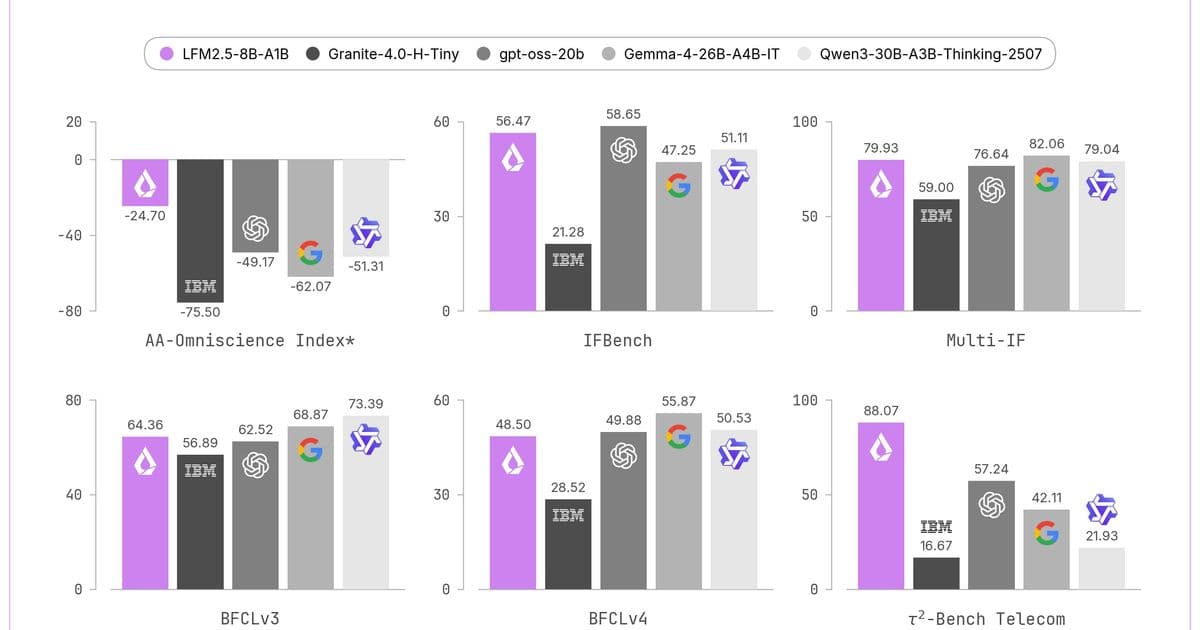
Liquid AI reports the AA‑Omniscience Index, a composite metric that rewards correct answers and penalizes hallucinations. LFM2.5‑8B‑A1B scores ‑24.70, a +53.62 point jump over its predecessor and a sizable lead over dense rivals like Granite‑4.0‑H‑Tiny (‑75.50) and Qwen3.5‑4B (‑51.53).
| Metric | LFM2.5‑8B‑A1B | LFM2‑8B‑A1B | Next best dense MoE |
|---|---|---|---|
| Accuracy | 8.67 | 7.33 | 9.37 (Granite‑4.0‑H‑Tiny) |
| Non‑Hallucination Rate | 63.47 | 7.46 | 6.38 (Qwen3.5‑4B) |
| IFEval | 91.84 | 79.44 | 87.74 (Gemma‑4‑E4B‑IT) |
| MATH500 | 88.76 | 74.80 | 86.48 (Qwen3‑30B‑A3B‑Thinking) |
| Tau²‑Telecom (agentic) | 88.07 | 13.60 | 71.93 (Qwen3.5‑4B) |
The most striking improvement is the non‑hallucination rate, which jumps from single‑digit to 63 %, indicating the model is far more likely to say “I don’t know” when faced with out‑of‑scope queries. This is attributed to a targeted RL stage that rewards abstention on low‑confidence knowledge prompts.
On throughput, the model claims the fastest speed in its class:
- CPU: 253 tokens / s on an Apple M5 Max, 146 tokens / s on a Ryzen AI Max+ 395, <6 GB RAM.
- GPU: 18.5 K output tokens / s on a single H100 (SGLang 0.5.12, 1 024‑token prompt, 256‑token output).
- Mobile: ~30 tokens / s on a modern Android phone, enabling near‑real‑time assistance.
Community sentiment and adoption signals
Positive signals
- Edge‑first positioning – Developers building privacy‑preserving assistants (e.g., the LocalCowork demo) can now avoid cloud APIs, aligning with growing regulatory pressure for on‑device processing.
- Open‑weight release – The model is available on Hugging Face and integrates with llama.cpp, MLX, vLLM, and SGLang, lowering the barrier for experimentation.
- Multilingual efficiency – The tokenizer expansion directly addresses complaints that many edge models under‑perform on scripts like Thai, Hindi, and Arabic.
Counter‑arguments and concerns
- Reasoning‑only head – Some researchers argue that forcing a chain‑of‑thought may increase latency for simple queries, where a direct answer would suffice. The trade‑off between transparency and speed remains under‑explored.
- Sparse inference complexity – While MoE reduces active parameters, it introduces routing overhead. On CPUs without specialized kernels, the routing step can dominate runtime, potentially narrowing the speed advantage on older laptops.
- Hallucination metrics – The AA‑Omniscience Index is proprietary; independent reproductions are needed to verify the reported 63 % non‑hallucination rate. Past releases have shown discrepancies between internal and external evaluations.
- Training cost – Scaling from 12 T to 38 T tokens implies a substantial carbon footprint. The blog mentions “mid‑training” stages but does not disclose the hardware mix, leaving sustainability questions open.
How does LFM2.5‑8B‑A1B fit into broader trends?
- Long‑context models – The 128 K window mirrors the direction taken by models like Claude‑3‑Sonnet and GPT‑4‑Turbo, suggesting that edge devices are now expected to handle document‑scale inputs.
- Hybrid MoE + reasoning – Combining sparse activation with explicit reasoning aligns with research showing that MoE excels at token‑level compute efficiency, while chain‑of‑thought improves factual grounding.
- Tool‑calling as a first‑class capability – By focusing on reliable tool dispatch loops, Liquid AI acknowledges that the next generation of assistants will be agentic rather than purely conversational.
- Open‑weight competition – The release adds pressure on other open‑source projects (e.g., Llama‑3‑8B‑Instruct, Gemma‑2‑8B) to improve multilingual tokenizers and long‑context handling without resorting to closed‑source APIs.
Getting started
- Model download – Both the base and fine‑tuned checkpoints are on Hugging Face.
- Documentation – The official docs cover llama.cpp conversion, MLX inference on Apple Silicon, and vLLM deployment for GPU clusters.
- Demo – The open‑source LocalCowork desktop agent showcases tool‑dispatch latency under a second on a single laptop.
Bottom line
LFM2.5‑8B‑A1B represents a concrete step toward privacy‑first, high‑throughput assistants that can run on everyday hardware. Its longer context, expanded tokenizer, and targeted RL fine‑tuning deliver measurable gains in accuracy and hallucination avoidance. However, the community will be watching closely to see whether the reasoning‑only head truly benefits real‑world workloads and whether the claimed hallucination reductions hold up under independent testing. If the model lives up to its promises, it could become a reference point for future edge‑focused MoE releases.
Image: 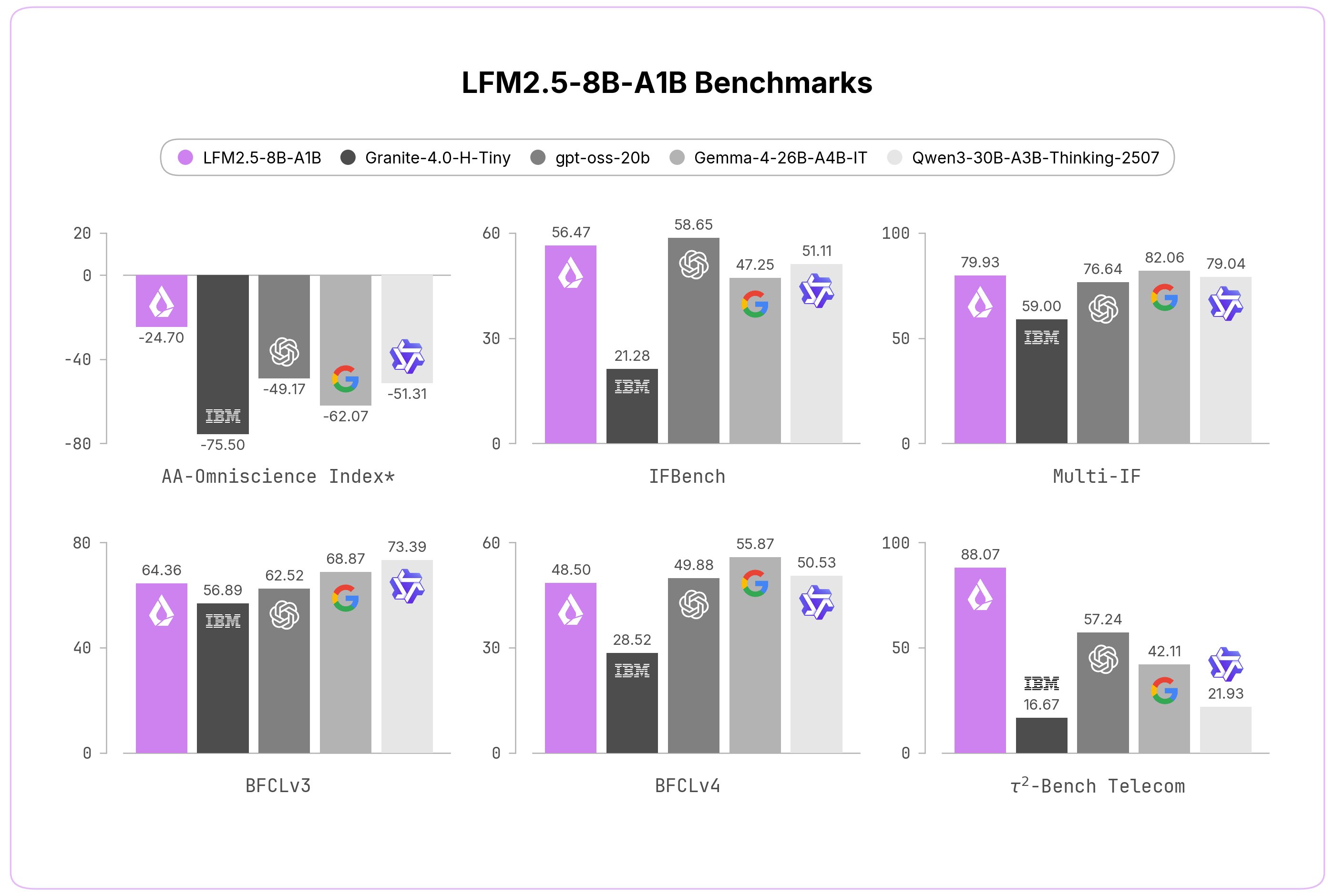
Comments
Please log in or register to join the discussion