New research from Roundtable Technologies shows that while vision‑language models can solve classic image CAPTCHAs, they do so with distinct interaction patterns. By measuring click sequences, direction changes, and overselection, the team builds a “Process Turing Test” that separates human users from AI agents, even for state‑of‑the‑art models like GPT‑4 and Gemini.
CAPTCHAs Aren’t Dead: How Process‑Level Signals Reveal AI Bots
Human‑centric verification has been under fire ever since large vision‑language models (VLMs) started acing image‑recognition CAPTCHAs. The headline “CAPTCHAs are broken” circulates on forums, but a recent pre‑print from Roundtable Technologies paints a more nuanced picture. The authors argue that what matters is not just whether an AI can answer correctly, but how it arrives at the answer. Their findings suggest a new class of human‑verification tools that could outlast the current wave of AI‑driven attacks.
The Observation: Output vs. Process
When you ask GPT‑4, Claude, or Gemini to click on “all traffic lights” in a static grid, the models can label the images with near‑human accuracy. This success led many to declare the classic CAPTCHA obsolete. However, Roundtable’s experiments reveal a systematic divergence in the process of solving these tasks.
| Feature | Humans | AI agents |
|---|---|---|
| Sequential click score | Low variance, smooth progression | Higher variance, occasional back‑tracking |
| Direction changes | Few, mostly logical | More frequent, often random |
| Overselection (clicking extra squares) | Rare | More common |
Statistical analysis shows these differences are significant across thousands of trials. In other words, AI can hit the right answer, but the behavioural fingerprint it leaves behind is distinct.
Evidence: The CogCAPTCHA30 Battery
To move beyond anecdotal observations, the team built CogCAPTCHA30, a 30‑task suite that blends a traditional image CAPTCHA with classic cognitive‑psychology experiments (memory recall, Stroop‑like interference, spatial reasoning, etc.).
- Recruitment: 200 human participants were recruited via Prolific, and the same tasks were run on four leading LLMs (GPT‑4, Claude, Gemini, Qwen‑2.5) plus an open‑source “Centaur” model trained on human‑cognition data.
- Metrics: Two axes were measured – output equivalence (how close the answers are, using Cohen’s d) and process equivalence (how similar the interaction patterns are, using AUC of a logistic discriminator).
- Result: Output equivalence clustered tightly (most models performed at >90% accuracy), but process equivalence was uncorrelated with output. Larger frontier models actually diverged more from human process signatures than smaller, purpose‑trained models.
"State‑of‑the‑art models are powerful, but they are not becoming more human‑like in their cognitive footprints," the authors note.
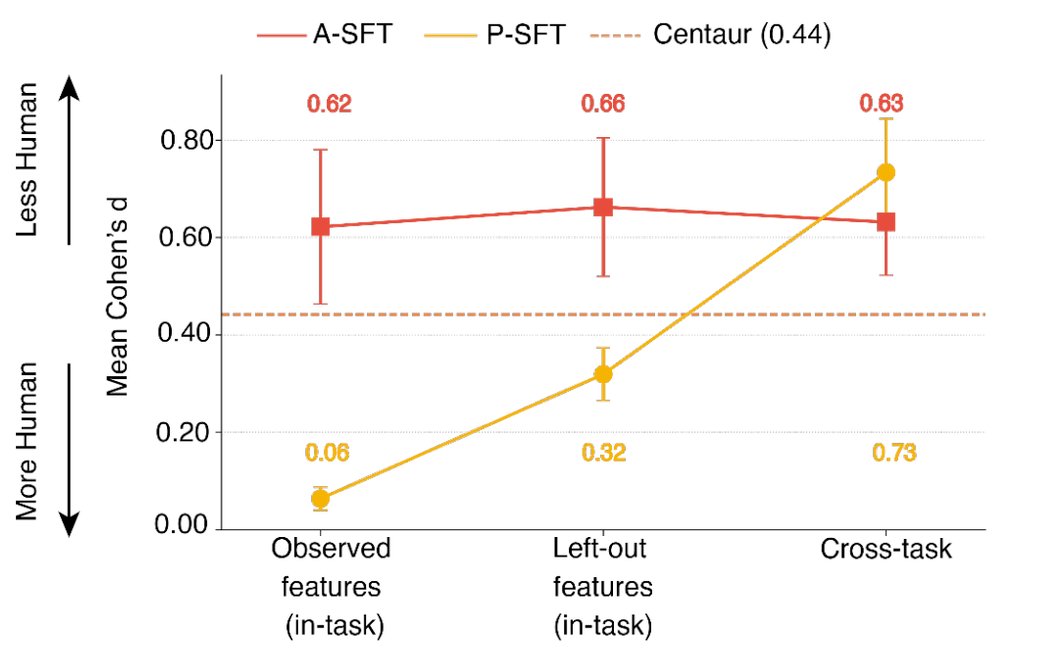
Figure 1: Humans and GPT‑4 achieve similar accuracy on a classic image CAPTCHA, yet their click‑stream features differ markedly.
Counter‑Perspectives
1. Arms Race Concerns
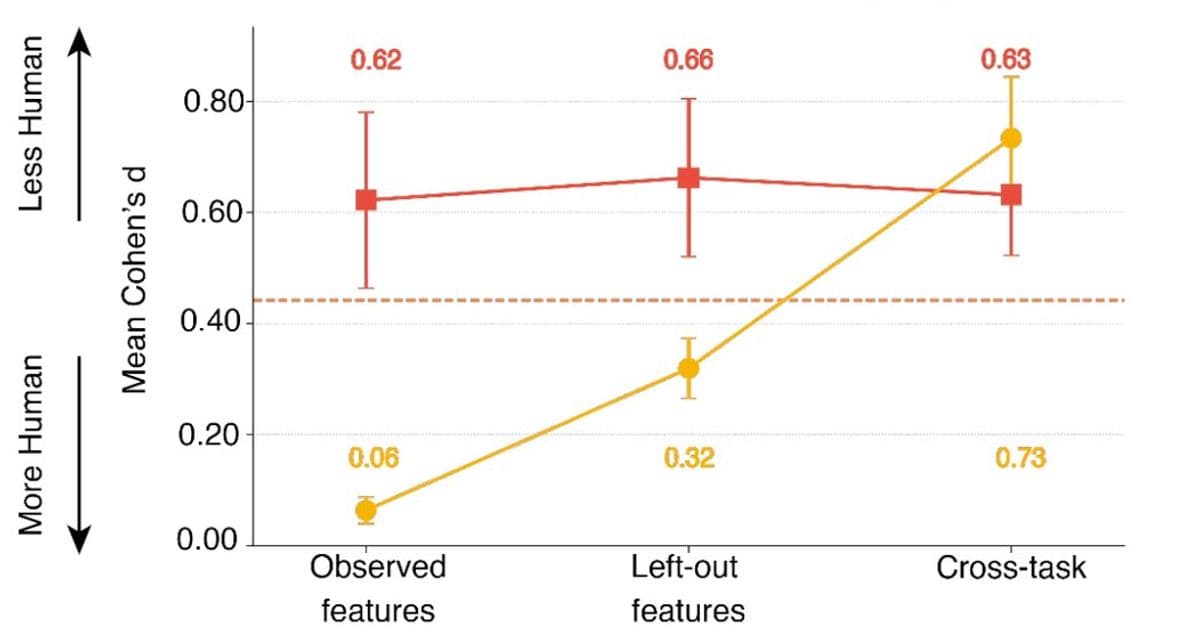
Critics argue that any behavioural detector is only as good as the current attacker model. If developers expose the feature set used by the discriminator, sophisticated bots could optimize for those signals—essentially performing a process‑level fine‑tuning (P‑SFT). The paper demonstrates this: when a Qwen‑2.5 model is fine‑tuned on the full feature set, the gap disappears entirely.
"The Process Turing Test is robust only when the AI does not know the exact features it will be judged on," the authors concede.
2. Generalisation Limits
Even with P‑SFT, the advantage evaporates when the discriminator hides part of the feature space or forces cross‑task generalisation. In real‑world deployments, rotating feature subsets and adding novel cognitive tasks could keep bots from over‑fitting.
3. Usability Trade‑offs
Embedding 30 cognitive tasks into a single verification flow raises concerns about user friction. While the authors envision an invisible authentication layer that runs in the background, practical implementations will need to balance security with latency and accessibility.
What This Means for the Future of Human Verification
- Process‑Based Signals Add a New Defensive Layer – Traditional CAPTCHAs rely on output difficulty; process‑based detectors add a behavioural dimension that is harder to spoof without explicit training data.
- Smaller, Cognitively‑Aligned Models May Pose Greater Risk – Open‑source models like Qwen, when fine‑tuned on human interaction data, can quickly close the process gap. This suggests that security teams must monitor not just flagship APIs but also community‑driven fine‑tunes.
- Dynamic Feature Sets Are Crucial – Rotating which behavioural metrics are evaluated (e.g., hiding direction‑change counts) forces attackers to generalise rather than over‑fit to a static checklist.
- Human‑Centric Design Remains Viable – The research re‑affirms that humans still exhibit unique, statistically measurable patterns when solving perception‑reasoning tasks. Leveraging these patterns could extend beyond CAPTCHAs to broader anti‑bot frameworks like invisible authentication or fraud detection.
How to Follow Up
- Read the full pre‑print for methodological details: Roundtable Research Pre‑print
- Explore the open‑source Centaur model, which was trained on 10M+ human choices across 160 cognitive experiments: GitHub – centaur‑cognition
- For a practical implementation guide, see the blog post on Process‑Level Human Verification: Roundtable Blog
Bottom Line
CAPTCHAs are not dead; they are evolving. By shifting focus from what answer is given to how the answer is produced, researchers have uncovered a durable signal that separates humans from even the most capable AI agents. The challenge now is to keep that signal moving—through dynamic feature selection, cross‑task generalisation, and continuous monitoring of emerging models. As AI continues to outpace traditional output‑based defenses, process‑level verification may become the next cornerstone of web security.
Comments
Please log in or register to join the discussion