
Google’s Gemini 3.5 Flash is fast but pricey, and the company’s fragmented developer tooling may be the real obstacle to broader adoption.
What’s going on with Gemini?
Google sits on a research bench that many consider the deepest in the industry, runs its own TPU silicon, and has virtually unlimited capital. Yet, most developers I talk to rarely touch Gemini in their daily workflows. The recent announcements at Google I/O crystallised a set of contradictions that are worth unpacking.
Where the models stand today
The consensus among practitioners is that Anthropic and OpenAI currently lead the frontier‑model race. Their monthly releases keep the two labs neck‑and‑neck, and a future Mythos‑class model from Anthropic could shift the balance again. Right now, GPT‑5.5 and Anthropic’s Opus 4.8 occupy roughly the same performance tier.
Google’s Gemini 3.1 Pro sits ahead of the Chinese offerings in benchmark scores but still trails the flagship Anthropic/OpenAI models. In my own testing, the best‑in‑class Chinese models—GLM 5.1 and Qwen 3.7—outperform Gemini 3.1 Pro on software‑engineering tasks.
Gemini 3.5 Flash: speed versus price
The headline from I/O was Gemini 3.5 Flash. Its coding benchmark placement was modest:
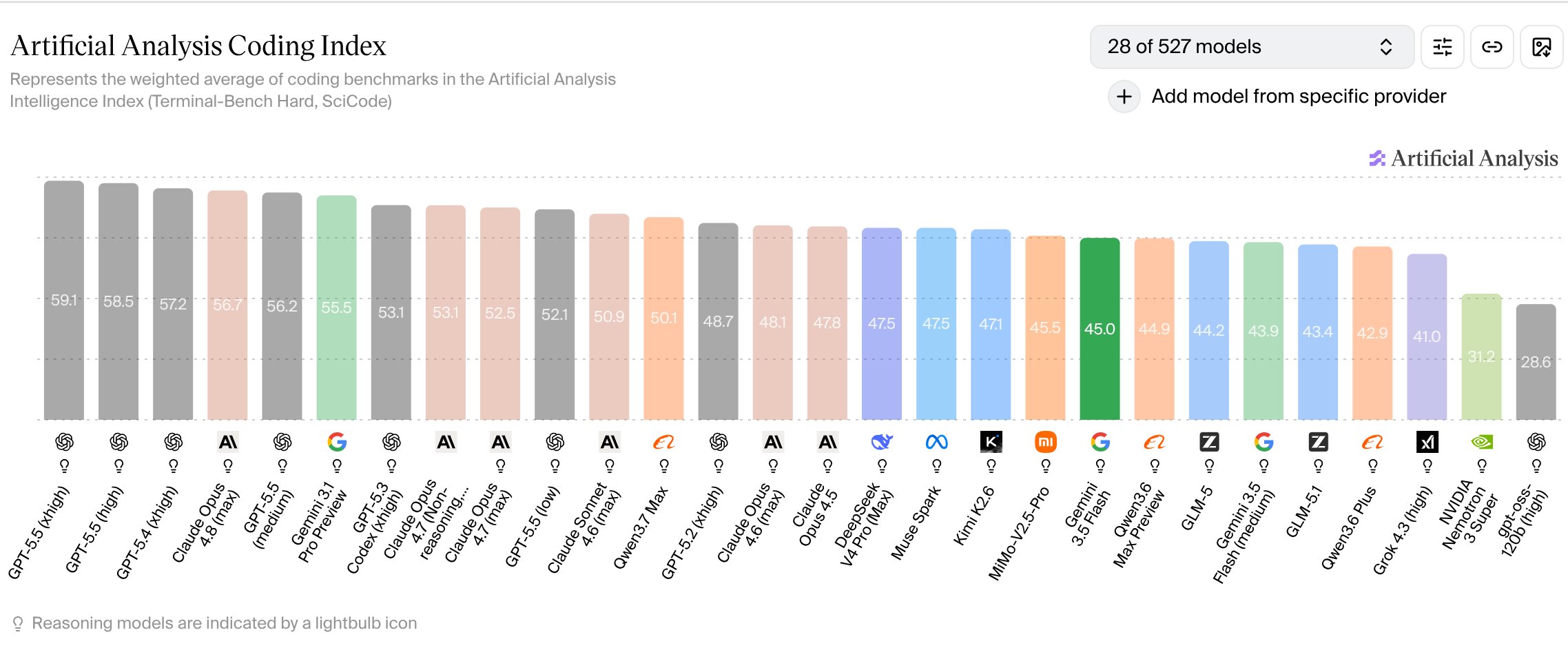
Gemini 3.5 Flash on the Artificial Analysis Coding Index – solidly mid‑pack.
The model’s token‑throughput, however, is striking:
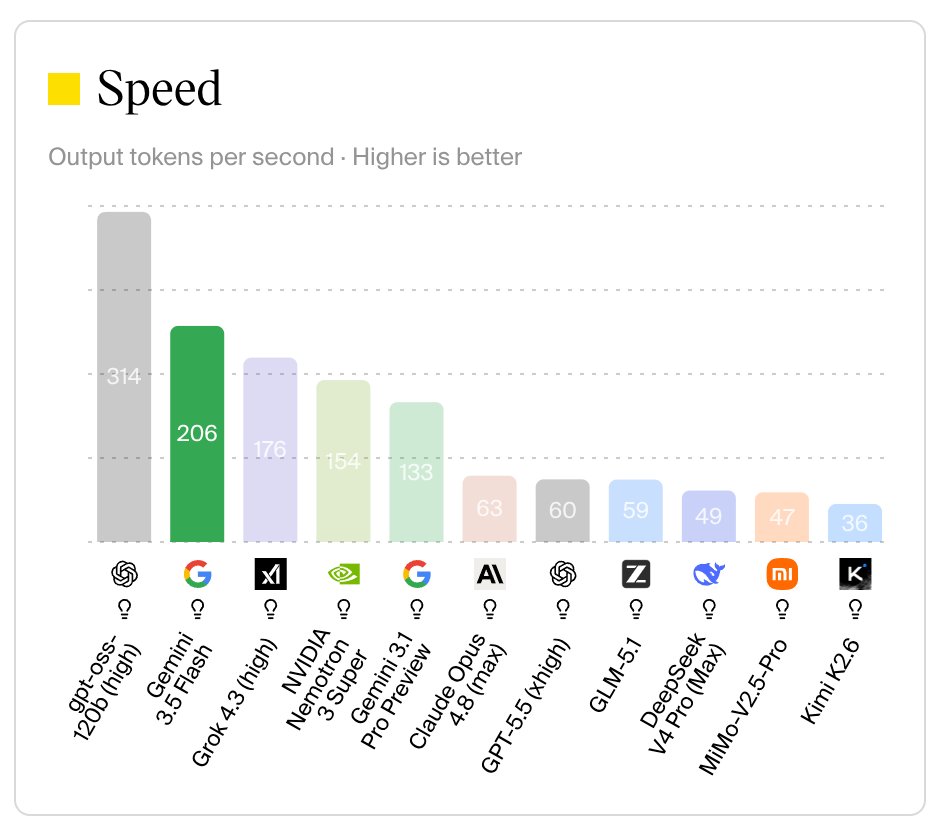
Output tokens per second – Gemini 3.5 Flash at 206 t/s, well ahead of Opus 4.8 and GPT‑5.5.
Four‑times the tokens per second can make a user‑facing chat feel snappy, which matters for products like Google AI Mode or Gmail’s smart compose. The trade‑off is price: Google announced a $9 per million‑token rate, roughly three times the cost of the previous Flash release and far above the rates of the leading Chinese models. If a developer’s priority is raw intelligence, they will gravitate toward Opus or GPT‑5.5; if cost is the dominant factor, the Chinese alternatives become attractive.
Who is the intended audience?
The pricing suggests that Gemini 3.5 Flash is not primarily aimed at external developers. Google consumes massive token volumes across its own services, and internal serving costs are likely a fraction of the public price. For internal use, the speed advantage directly improves end‑user experience, while the cost impact on Google’s balance sheet stays modest.
Hardware advantage and inference efficiency
A comment on Hacker News estimated that Gemini 3.5 Flash could run on a single TPU 8i card—Google’s latest custom inference accelerator. This hardware‑model alignment is a unique lever. Most frontier labs rely on Nvidia or AMD GPUs and must adapt their models to the constraints of those chips. Google’s teams design silicon and models in tandem, allowing them to target a sweet spot where a model’s size, memory footprint, and compute pattern match the next generation of TPU.
When a lab can predict the hardware roadmap without negotiating with an external vendor, it can optimise for inference efficiency at scale. That efficiency translates into lower per‑token costs and the ability to serve faster responses, both of which are decisive factors in the economics of large‑scale AI services.
The coding‑agent puzzle
Anthropic offers Claude Code, OpenAI ships Codex, and both have built clear, single‑purpose APIs that developers can adopt quickly. Google’s approach feels fragmented:
- Antigravity
- Jules
- Gemini Code Assist
- Gemini CLI (now folded into Antigravity)
- AI Studio
- Specialized agents inside Android Studio and other internal tools
The proliferation of overlapping tools creates confusion for external developers. Without a unified surface, Google misses out on the telemetry loop that powers continuous improvement for Claude Code and Codex. The lack of a clear, developer‑first entry point is a strategic weakness in the fastest‑growing revenue segment of AI—software‑engineering assistance.
Google’s internal development stack is highly customised (source‑control, build pipelines, testing frameworks). While that stack delivers efficiency at Google scale, it also isolates the company from the conventions most engineers use elsewhere. This isolation makes it harder for Google to design agentic tooling that feels natural to the broader community.
What the future could look like
If Google aligns its developer‑facing tools into a coherent offering, the underlying advantages—custom TPU silicon, deep research talent, and tight hardware‑model integration—could become hard to overcome. The current situation reads as a company playing a different game: Gemini 3.5 Flash is priced and tuned for Google’s internal token consumption, where speed matters more than raw benchmark scores.
The real hurdle is the surface area presented to developers. A single, well‑documented API for code assistance, paired with transparent pricing, would let the broader ecosystem feed back data that fuels the next generation of models.
Takeaway
Google’s Gemini line showcases a model that is exceptionally fast and tightly coupled to proprietary hardware, but its pricing and fragmented tooling limit external adoption. The company’s structural strengths could eventually give it a decisive edge—provided it resolves the developer‑experience knot that currently hampers its coding‑agent strategy.
For more on the pricing announcement, see the official Google I/O blog post.
Comments
Please log in or register to join the discussion