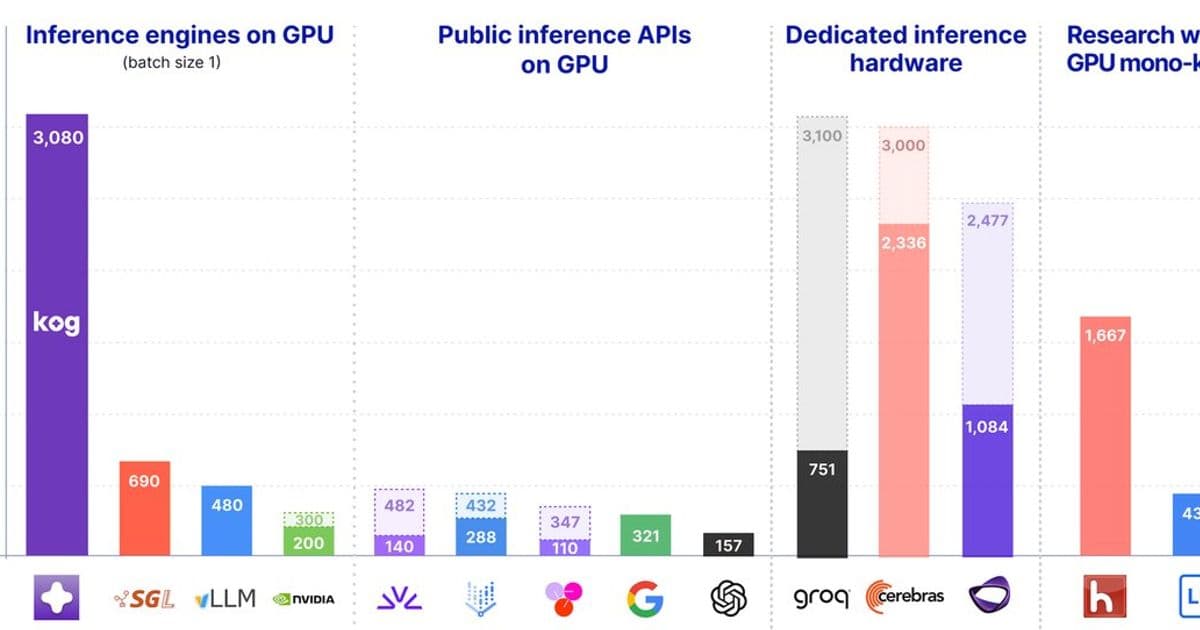
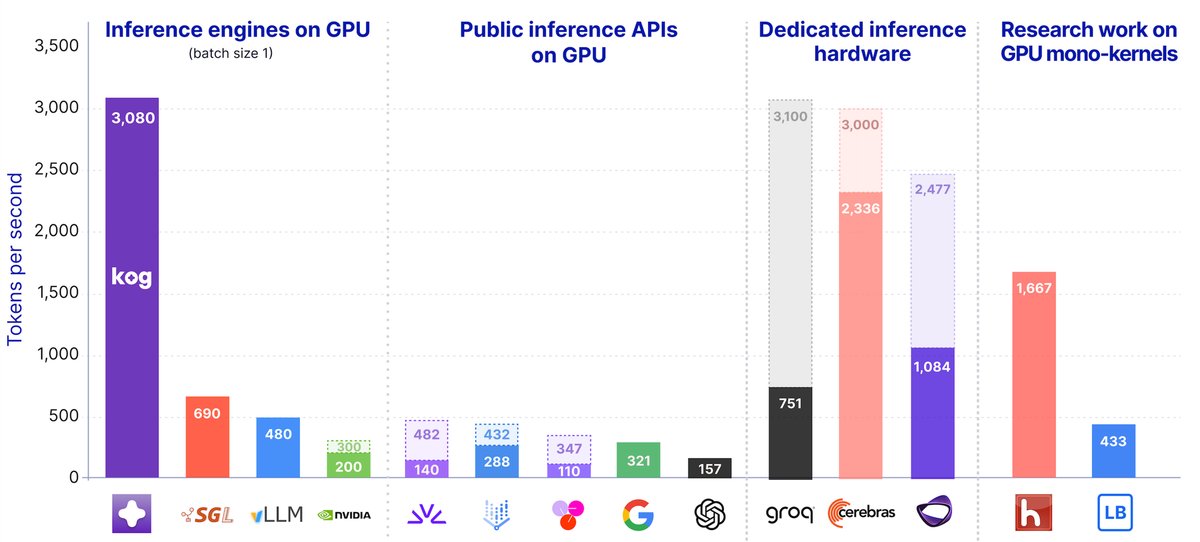
Kog’s new inference engine shows that a single‑request LLM can generate 3,000 tokens per second on an 8‑GPU datacenter node, matching dedicated inference chips by re‑thinking the whole software stack—model, runtime and low‑level kernels—as a single latency‑first pipeline.
Kog’s claim: 3,000 tokens / s on off‑the‑shelf GPUs
Kog has opened a tech preview that lets anyone try a 2 B‑parameter coding model in a live playground (playground.kog.ai). The benchmark they publish is striking: 3,000 output tokens per second per request on a single 8‑GPU node, without any quantisation, speculative decoding or pruning. That puts the speed of a standard NVIDIA H200 or AMD MI300X server in the same ballpark as purpose‑built inference ASICs, but with the flexibility of general‑purpose GPU hardware.
Why single‑request latency matters now
Most inference benchmarks focus on aggregate throughput – how many tokens a server can churn out when it processes large batches. For autonomous AI agents, however, the bottleneck is the decode speed of a single request. An agent that writes, tests, and revises code in a loop may need to generate tens of thousands of tokens before the next tool call. At 100 tokens / s that work takes minutes; at 3,000 tokens / s the same loop finishes in seconds, opening a whole new class of real‑time agentic products.
The metric that matters for these workloads is tokens per second per request, not total tokens per second across users. Kog therefore optimises for batch size = 1, accepting lower overall utilisation in exchange for dramatically reduced wall‑clock latency.
The memory‑bandwidth bottleneck
When batch size is one, each generated token requires a matrix‑vector multiply for every active weight. The operation is memory‑bound: the GPU must stream the model’s weights from HBM to the compute cores faster than it can compute them. In FP16 a weight occupies 2 bytes and contributes roughly one multiply‑add (2 FLOPs), giving a ratio of ~1 FLOP / byte. Modern GPUs, however, can deliver several hundred FLOPs per byte of HBM bandwidth (e.g., NVIDIA H200’s ~400 FLOP / byte). The consequence is clear – memory bandwidth, not raw compute, caps token‑generation speed.
A back‑of‑the‑envelope calculation for a 2 B‑parameter dense model (≈4 GB of active weights) on an 8‑GPU H200 node (≈30.7 TB / s effective bandwidth) yields a theoretical ceiling of ~7,700 tokens / s. Similar numbers hold for AMD MI300X. The challenge is to approach that ceiling by eliminating micro‑second‑scale stalls that waste bandwidth.
Where conventional stacks lose time
Typical inference engines (vLLM, SGLang, TensorRT‑LLM) are built on top of high‑level frameworks such as PyTorch or Triton. The execution path looks like this:
- CPU runtime schedules a series of kernels for each transformer layer.
- Kernel launch incurs ~4–5 µs overhead on AMD hardware.
- Synchronization between kernels and across GPUs adds more microseconds.
- Host‑GPU communication for sampling and KV‑cache handling further stalls the pipeline.
With ten kernels per layer and 25 layers, just the launch overhead can consume >1 ms per token, capping speed at ~900 tokens / s. Even aggressive kernel fusion (five kernels per layer) only raises the ceiling to ~1,800 tokens / s. The remaining gap to the memory‑bandwidth limit is caused by:
- Grid synchronisation (barriers, AllReduce) – a few µs per layer.
- Tensor‑parallel communication – multiple AllReduce steps per layer.
- Cache‑misses and weight reloads – imperfect reuse of tiled data.
- Non‑GEMM work (softmax, layer‑norm, routing, sampling) – pauses the streaming of weights.
Kog’s three‑layer co‑design
Kog tackles the problem by treating the model, the runtime and the GPU kernels as a single system:
| Layer | Conventional approach | Kog’s approach |
|---|---|---|
| Model architecture | Fixed transformer, tensor‑parallel only | Laneformer with Delayed Tensor Parallelism (DTP) that overlaps cross‑GPU communication with useful compute. |
| Runtime | Multi‑kernel scheduler, CPU‑driven, heavy host‑GPU round‑trips | Monokernel – one persistent GPU program that runs the entire decode path without leaving the device. |
| GPU code | Library kernels (CUTLASS, cuBLAS, NCCL) with generic launch parameters | Hand‑crafted CUDA/HIP kernels + inline PTX/ISA, custom KCCL collectives tuned for sub‑3 µs latency. |
Monokernel runtime
Instead of launching a new kernel for each operation, Kog compiles a single GPU‑resident program that streams weights, performs attention, normalisation, routing, sampling and inter‑GPU collectives in a tightly scheduled loop. The result is a continuous memory‑streaming pipeline where the only pauses are the inevitable synchronisation points, now reduced to ~600 ns per intra‑GPU barrier (thanks to topology‑aware placement on AMD’s XCD/IOD layout).
KCCL communication layer
Kog replaces vendor collectives (NCCL, RCCL) with KCCL, a hand‑optimised implementation that trades raw bandwidth for deterministic sub‑3 µs latency. By aligning the collective schedule with the monokernel’s execution, communication can overlap with weight prefetch, keeping the pipeline fed.
Laneformer & Delayed Tensor Parallelism
Traditional tensor parallelism forces a synchronise‑then‑compute pattern: all GPUs must finish a matmul before they can exchange partial results. DTP restructures the dependency graph so that each GPU can start the next matmul while the previous layer’s reduction is still in flight. The net effect is a latency‑friendly parallelism that scales the bandwidth of an 8‑GPU node to the level required for 3,000 tokens / s.
Benchmarks and scaling estimates
| Hardware | Model | Tokens / s (preview) |
|---|---|---|
| 8× MI300X | Laneformer 2 B (FP16) | 3,000 |
| 8× H200 | Same model | 2,100 |
The preview model scores 50 % on HumanEval, comparable to larger open‑source coders, proving that speed does not come at the expense of basic capability.
Projected speeds for larger MoE models
Using the same memory‑bandwidth‑only ceiling (active‑parameter bytes per token) and assuming Kog’s current ~36 % memory‑bandwidth utilisation (MBU), the table below shows rough token‑per‑second estimates for frontier models when run on an 8‑GPU node:
| Model (active params, precision) | 8× H200 (≈30 TB / s) | 8× MI300X (≈33 TB / s) |
|---|---|---|
| Qwen3‑Coder‑Next (3 B, FP8) | ~3,650 | ~4,000 |
| GPT‑OSS‑120B (5.1 B, FP4/BF16) | ~2,200 | ~2,400 |
| DeepSeek‑V4‑Flash (13 B, FP8) | ~1,160 | ~1,270 |
| Kimi‑K2.6 (32 B, INT4) | ~325 | ~355 |
These are upper bounds; real‑world numbers will be lower due to the extra AllReduce steps required for third‑party models that cannot use DTP. Nevertheless, even a conservative 30 % of the theoretical ceiling places many large MoEs comfortably above 1,000 tokens / s per request, a regime previously only reachable with dedicated inference chips.
What this means for AI agents
- Iteration speed becomes a first‑order product differentiator. An autonomous coding assistant that can finish a full edit‑test‑revise loop in under 30 seconds can be embedded directly into IDEs or CI pipelines.
- Standard datacenter GPUs stay relevant. Enterprises that already own H200 or MI300X hardware can now run latency‑critical agents without buying proprietary silicon.
- Future hardware will only help. Upcoming GPUs (Rubin, MI450) promise 4× the HBM bandwidth, pushing the same pipeline to handle models four times larger at unchanged latency.
Next steps and how to get involved
- Play with the demo – the live playground runs the Laneformer 2 B model on an 8‑GPU MI300X node. No sign‑up required.
- Read the deep‑dive posts – Kog’s engineering blog explains the monokernel implementation and the DTP architecture in detail.
- Join the design partner program – teams building coding agents, app‑generation systems or any workflow where iteration speed is a bottleneck are invited to collaborate.
About Kog
Kog is a Paris‑based AI infrastructure startup founded in 2023 by Gaël Delalleau, a former cybersecurity researcher turned high‑performance GPU engineer. The company now has 11 staff members, including five PhDs, and has raised $5 M from Varsity VC and BPI France’s Deep Tech Program. It was awarded the French Tech 2030 label in October 2025, recognizing its contribution to strategic deep‑tech sectors.
Explore the links below for more technical depth:
- Delayed Tensor Parallelism blog post – the architectural reasoning behind Laneformer.
- Monokernel runtime deep dive – low‑level GPU tricks for AMD MI300X and NVIDIA H200.
- Design Partner Program – contact form for early‑access collaborations.
Comments
Please log in or register to join the discussion