How an AI assistant provided closure on a perplexing 2017 Swift/C++ interoperability bug by connecting historical context with language evolution details that the original debugger couldn't access.
In the annals of software development, certain bugs linger in memory not just for their technical complexity, but for the human drama they create. The tale of a decade-old Swift/C++ interoperability bug, recently solved with the help of an LLM, offers profound insights into how our relationship with debugging is evolving. This narrative reveals not only a technical mystery but also demonstrates how AI can serve as a temporal bridge, connecting present knowledge with historical context in ways previously impossible.
The story begins in 2017 with Juke, a pioneering music application boasting 57 million songs. Its architecture represented an ambitious experiment in cross-platform development: UI layers in Java and Objective-C, with core business logic written in C++. The application utilized the Djinni framework from Dropbox, which enabled this hybrid approach. The author led efforts to port the iOS component from Objective-C to Swift, a transition that improved developer experience across the board.
The critical functionality at the heart of the mystery was offline song storage. Users could save encrypted tracks locally, with Android users even having the option to store them on SD cards. The encryption process involved salted hashes and nonces, with UI layers calling C++ encrypt/decrypt functions through the language boundary.
The bug manifested immediately after iOS 11.0.1's release in September 2017. Users who had saved approximately 1GB of songs in iOS 10 found themselves unable to play them after upgrading. The debugging process that followed reads like a thriller: the author had to manually downgrade devices to iOS 10.3.3, download songs, upgrade to iOS 11.0.1, and meticulously trace the execution path through Swift → Objective-C → Objective-C++ → C++ and back.
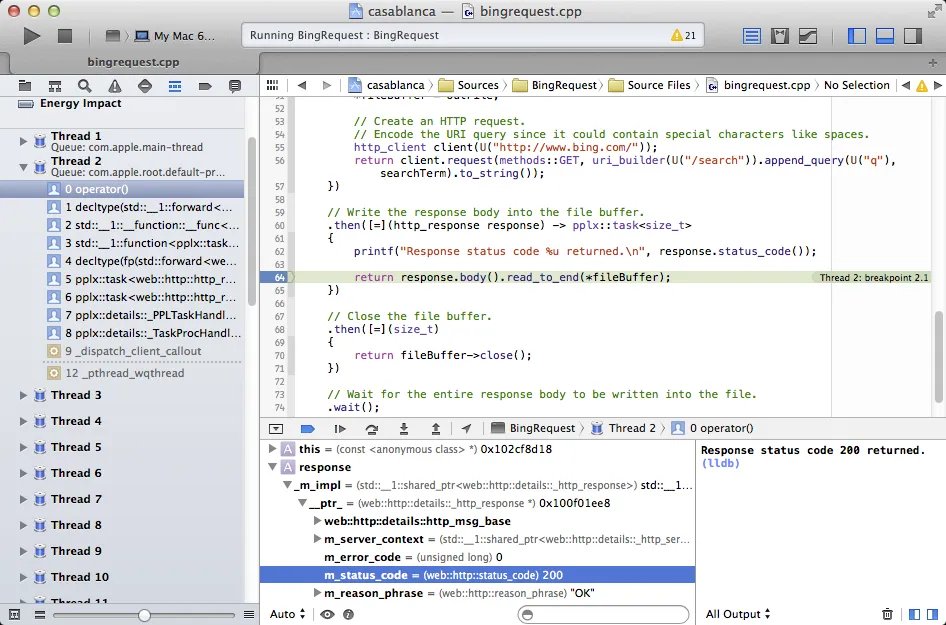
This debugging marathon, occurring under time pressure as Apple's signing window for older iOS versions closed, represents a fascinating artifact of pre-AI debugging practices. The author describes experiencing "scroll blindness" while navigating through Xcode's debugging interface, a visceral reminder of how much cognitive load manual debugging once required.
The breakthrough came not from exhaustive step-by-step tracing, but from a strategic shift: focusing specifically on the encryption and decryption functions rather than the entire call chain. This targeted approach revealed that an inout parameter in the Swift decrypt function was null in iOS 11.0.1—a parameter crucial for song decryption. Removing the inout qualifier resolved the issue, though the root cause remained elusive.
Fast forward to 2026, when the author, prompted by a mentee about documenting quirky work encounters, had an epiphany: What if an LLM could investigate this decade-old mystery? The resulting interaction with Claude Opus 4.6 produced revelations that connected dots the original debugger couldn't see.
The LLM identified that the timeframe (2016-2018) corresponded to critical transitions in Swift's evolution:
- iOS 10/Swift 3.0 (September 2016): Introduced UnsafeRawPointer and formalized strict aliasing rules
- iOS 11/Swift 4.0 (September 2017): SE-0176 enforced exclusive access to memory, fundamentally changing inout semantics
- iOS 12/Swift 4.2 (September 2018): Fully enabled exclusivity enforcement at runtime
The most probable culprit, according to the LLM, was SE-0176, which changed Swift's inout semantics from copy-in/copy-out to strict enforcement of the Law of Exclusivity. This meant that when crossing the Swift → Objective-C → C++ boundary, the compiler would materialize a temporary copy of the buffer, pass a pointer to this temporary buffer to the native side, and then copy back the results.
In iOS 10/Swift 3, the compiler passed the pointer directly (pass-by-reference optimization). When Swift 4 enforced exclusivity, this behavior changed. The decryption function, expecting to read from the original buffer, instead read from a copy (likely all zeros or uninitialized), producing incorrect decryption keys. This explains why the parameter appeared null—it wasn't actually null, but pointing to an uninitialized or zeroed buffer.
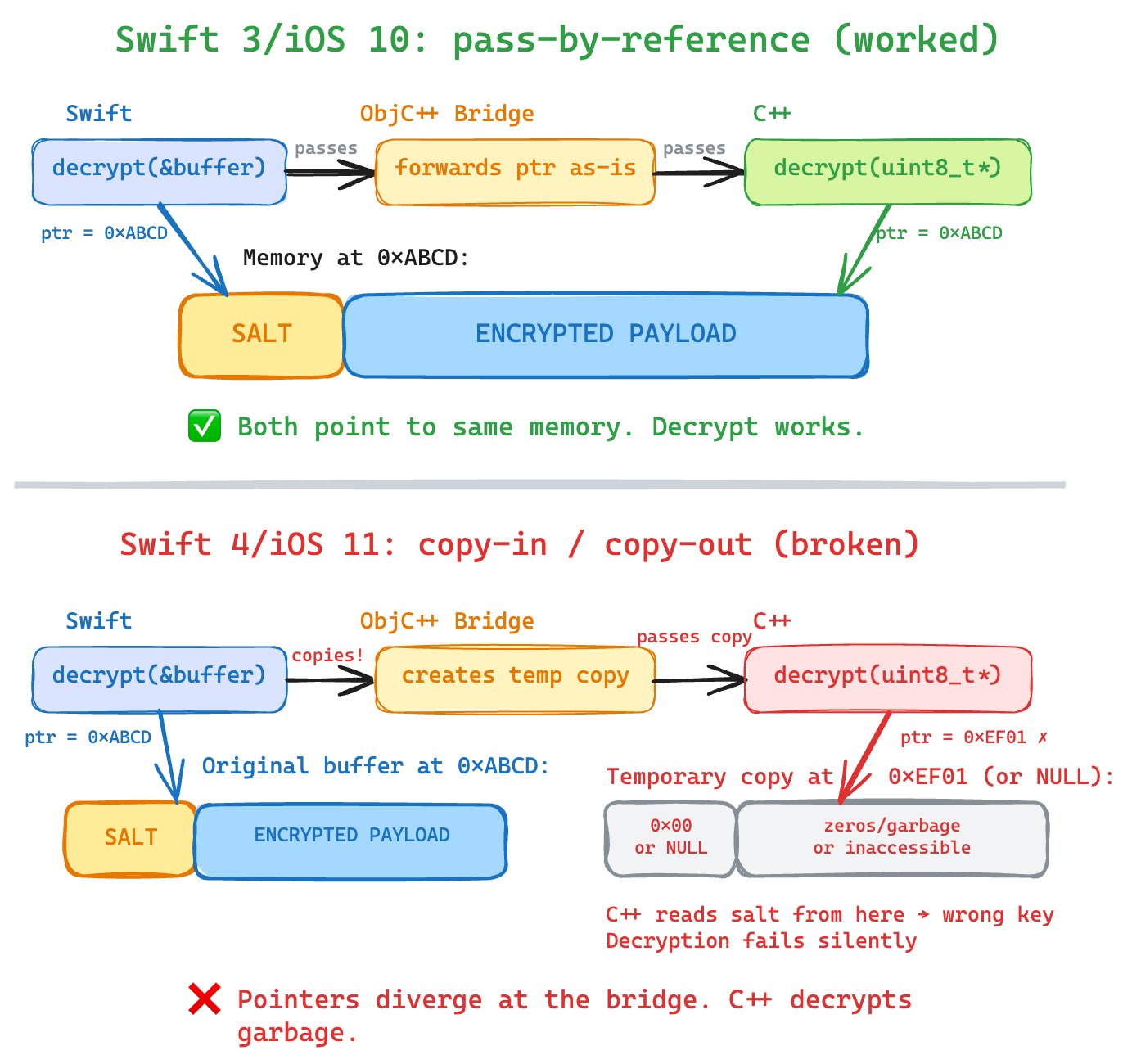
This visualization helps illustrate how the same code behaved differently across Swift versions due to changes in memory management semantics. The LLM essentially served as a time machine, providing access to historical language design decisions and their practical implications that were not readily available to the original debugger.
The implications of this story extend far beyond this particular bug. It demonstrates how LLMs can augment our understanding of technical debt by providing context about language evolution that might otherwise be lost to time. For developers maintaining legacy systems, this capability could prove invaluable when dealing with inexplicable behaviors that originated in framework or compiler changes.
Moreover, the story highlights a fascinating dimension of AI-assisted debugging: the ability to synthesize information across multiple domains—language specifications, OS release notes, compiler behavior, and application architecture—to form hypotheses that would require an impractical amount of cross-disciplinary knowledge for a human developer.
However, this narrative also underscores that LLMs complement rather than replace human expertise. The original debugger's domain knowledge, understanding of the application's architecture, and strategic approach to problem-solving were essential in identifying the area where the bug resided. The LLM provided the missing piece of the puzzle—the "why" behind the behavior—but only after the "what" and "where" had been determined through traditional debugging techniques.
As we continue to integrate AI tools into our development workflows, this case study offers a compelling model for collaboration: humans provide context, domain knowledge, and strategic direction, while AI assistants offer expansive knowledge retrieval, pattern recognition across disparate domains, and temporal context that bridges knowledge gaps.
The author's closing reflection about revisiting other historical bugs with LLM assistance suggests a new frontier in software archeology—one where we can excavate not just code, but the reasoning behind technical decisions and their consequences across time. This capability could transform how we approach legacy systems, technical debt, and understanding the evolution of complex software ecosystems.
In the end, this story is not just about solving a specific bug, but about illuminating a new paradigm in technical problem-solving—one that leverages AI's unique strengths while preserving the irreplaceable value of human experience and intuition.
Comments
Please log in or register to join the discussion