
In high-performance Rust systems, RwLock's read operations can be 5× slower than Mutex in read-heavy workloads due to atomic contention and cache-line ping-pong, challenging conventional concurrency wisdom.
The promise of read-write locks seems straightforward: optimize read-heavy workloads by allowing concurrent access while protecting exclusive writes. Yet in the trenches of high-performance systems like Redstone's Tensor Cache, this conventional wisdom shatters against hardware realities. My benchmarking revealed a startling inversion—RwLock's read operations trailed Mutex by 5× in throughput despite a read-dominated workload. This counterintuitive outcome exposes fundamental misunderstandings about how locking primitives interact with modern processors.
At the heart of this paradox lies Apple's M4 architecture—a 10-core beast where memory coherence protocols transform seemingly innocent read locks into resource battles. The parking_lot::RwLock implementation, like all reader-writer locks, maintains an atomic counter for tracking active readers. Each invocation of .read() requires incrementing this counter, a hardware-level write operation that triggers cache-line invalidation across cores. When thousands of threads attempt near-simultaneous access—as in a tensor cache processing nanosecond-scale .get() operations—cores engage in vicious cache-line ping-pong: ownership of the 64-byte memory segment containing the counter bounces between cores like a hot potato, saturating the memory bus while actual work stalls.
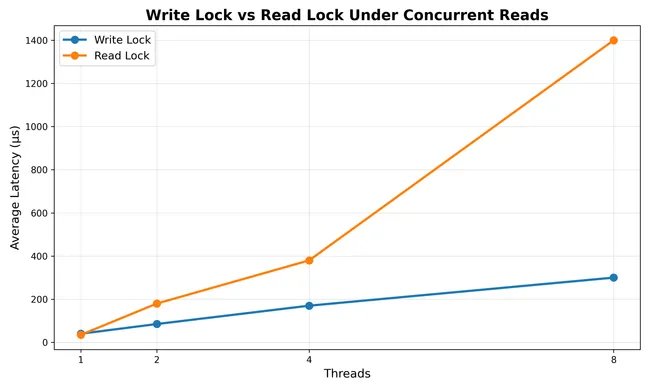
The Mutex alternative avoids this death spiral through deliberate limitation: its exclusive access guarantee eliminates atomic counter contention entirely. Though conceptually permitting fewer concurrent operations, Mutex's streamlined lock-unlock cycle proves unexpectedly efficient for microsecond-scale critical sections. As threads queue politely rather than stampeding the reader counter, net throughput surges precisely because the hardware isn't perpetually reconciling cache inconsistencies.
This revelation demands architectural reconsideration. First, recognize that locking overhead dominates execution time for operations under ~100ns—hashmap lookups, integer increments, or other trivial manipulations should never bear RwLock's reader-counting tax. Second, profiling tools like cargo-flamegraph become essential: disproportionate cycles spent in atomic_add reveal cache contention. Finally, consider sharding strategies that partition datasets across independent locks, reducing contention points while preserving concurrency.
RwLock retains value in specific scenarios—notably when read operations involve millisecond-scale processing or writes are genuinely rare—but its deployment requires empirical validation. The M4's behavior reflects broader hardware trends: as core counts increase and memory delays dominate performance budgets, the true cost of shared-state synchronization escalates nonlinearly. Concurrency abstractions must therefore evolve beyond textbook models to embrace memory hierarchy realities, transforming locking from blunt instrument to precision tool.
Ultimately, this case underscores that concurrent system design demands empirical validation. Assumptions about "read-friendly" locks crumble under hardware scrutiny, reminding us that processor architectures—not theoretical models—dictate performance. Profiling remains the only antidote to intuitive fallacies, exposing hidden bottlenecks before they metastasize into production crises.
Comments
Please log in or register to join the discussion