
A comprehensive guide to building scalable, secure, and observable diffusion model platforms on Azure Kubernetes Service, addressing the unique challenges of moving from prototype to production.
Scaling Diffusion Models on Azure: Architecting Production-Ready AI Workloads
Diffusion models have transformed the AI landscape, generating remarkable visual and creative outputs from simple text prompts. However, the journey from a single GPU demo to a production-scale platform presents substantial architectural challenges. While prototype implementations can run on a single GPU-backed virtual machine, real-world deployments must handle bursty demand, long-running jobs, model artifact distribution, secure public access, rollout safety, and hardware-level observability.
Azure Kubernetes Service (AKS) emerges as an ideal foundation for these workloads when the requirement extends beyond merely running a model to operating a repeatable, scalable platform for GPU inference. This article examines a production-ready architecture pattern that addresses the unique demands of diffusion workloads while maintaining security, scalability, observability, and operational excellence.
The Challenge: From Prototype to Production

At prototype scale, diffusion models appear straightforward—deploy a container with the necessary dependencies, point it to a GPU, and process incoming requests. However, production environments introduce complexities that demand thoughtful architecture:
- Bursty demand: Diffusion workloads experience unpredictable request patterns that can overwhelm simple deployments
- Model management: Efficient distribution and caching of large model artifacts across multiple workers
- Job isolation: Preventing long-running jobs from blocking short inference requests
- Security requirements: Protecting APIs while enabling public access to generated content
- Operational observability: Monitoring both application performance and GPU hardware utilization
- Cost optimization: Balancing performance requirements with efficient resource utilization
These challenges necessitate an architecture that treats diffusion workloads as first-class citizens within a broader platform ecosystem rather than isolated experiments.
Core Architecture Pattern
The production-ready pattern for diffusion models on AKS follows a clear separation of concerns:
- Control plane: Lightweight API tier on CPU nodes handling authentication, validation, and request admission
- Dispatch layer: Buffering work between requests and execution, either Kubernetes-native or externalized
- Execution plane: Isolated GPU capacity for actual model inference
- Persistence layer: Durable storage for outputs and model caching
- Observability: Comprehensive monitoring of both application and hardware telemetry
- Security: Edge protection, workload isolation, and secure secret management
This separation enables independent scaling of each component based on its specific requirements and performance characteristics.
Detailed Architecture Components
Edge and Ingress Layer
The architecture begins with a robust edge layer that handles incoming traffic:
- DNS routing with Azure Front Door for global entry when multi-region deployment is required
- Application Gateway with Web Application Firewall (WAF) for security inspection and TLS termination
- Optional Front Door for global load balancing, caching, and routing policies
This edge layer provides several benefits:
- Centralized security policies and DDoS protection
- Global distribution with reduced latency for users worldwide
- TLS termination offloading from application workloads
- Consistent security posture across all diffusion endpoints
The Application Gateway Ingress Controller integrates directly with AKS, allowing Kubernetes to manage routing rules while leveraging Azure's enterprise-grade edge capabilities.
Node Pool Separation
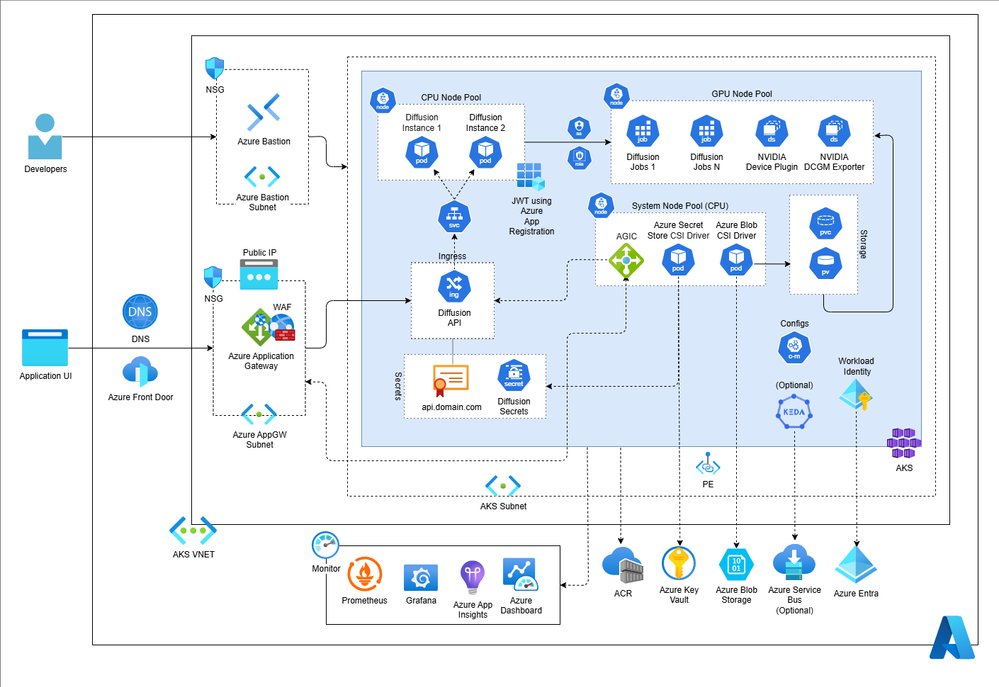
AKS node pools form the foundation of the architecture, with clear separation of concerns:
- CPU pool: Hosts the API tier and control-plane components that remain accessible to external traffic
- GPU pool: Dedicated resources for model execution, isolated from other workloads
- System pool: Shared cluster services such as Application Gateway Ingress Controller (AGIC), Secret Store CSI Driver, and Blob CSI drivers
This separation provides several operational advantages:
- Independent scaling of CPU and GPU resources based on workload demands
- Security boundaries between public-facing components and execution infrastructure
- Platform services remain unaffected by application or GPU workload behavior
- Cost optimization by allocating appropriate instance types to each pool
The AKS node pools documentation provides detailed guidance on implementing this separation.
Dispatch Layer Design
The dispatch layer represents a critical architectural decision point with two primary approaches:
Kubernetes-Native Dispatch
For teams preferring minimal external dependencies, the Kubernetes-native approach keeps all dispatch logic within the cluster:
- API tier creates or signals Kubernetes work objects (Jobs, Custom Resources, etc.)
- Internal queueing or controller patterns manage admission and dispatch
- AKS workload autoscaling and cluster autoscaling handle scaling based on queue depth or pending work
This approach simplifies the operational footprint when:
- The team has deep Kubernetes expertise
- Workload patterns are well-understood and relatively stable
- Burst characteristics can be managed with Kubernetes autoscaling alone
- External dependencies need to be minimized
Azure Service Bus with KEDA
For more complex scenarios requiring explicit queue visibility and durability, the external queue approach provides advantages:
- API tier publishes work to Azure Service Bus topics/queues
- Separate consumers or schedulers materialize GPU execution from the queue
- KEDA (Kubernetes Event-driven Autoscaling) scales worker pods directly based on queue depth
- Azure Service Bus provides guaranteed message delivery and backlog visibility
This approach excels when:
- Queue depth and backlog visibility are operational requirements
- Burst patterns exceed Kubernetes autoscaling capabilities
- Durability guarantees are essential for job processing
- Independent observability of queue pressure is needed
The KEDA documentation provides detailed implementation guidance for this pattern.
GPU Execution and Isolation
The GPU execution lane represents the core of the diffusion workload platform:
- Dedicated node pool with GPU-optimized VM instances (NC, ND, or NDv4 series)
- Pod isolation using taints and tolerations to ensure only diffusion workloads run on GPU nodes
- NVIDIA device plugin DaemonSet that advertises GPU resources (including MIG slices) to the kube-scheduler
- Persistent volume mounts for model caching to minimize download times
This isolation provides several critical benefits:
- Prevents non-GPU workloads from consuming expensive GPU resources
- Enables precise monitoring and management of GPU utilization
- Supports specialized GPU configurations like multi-instance GPUs (MIG)
- Simplifies quota management and cost allocation
The NVIDIA k8s-device-plugin enables Kubernetes to recognize and schedule GPU resources effectively.
Storage Architecture
The storage layer serves two primary purposes in the diffusion model architecture:
- Durable output storage: Persisting generated images or other model outputs for retrieval and potential long-term retention
- Model cache: Providing shared access to Hugging Face model artifacts across GPU workers
Two primary storage patterns address these needs:
Node-Local Persistence
For scenarios where model artifacts benefit from warm data already present on the same node:
- Local persistent volumes or ephemeral storage with model pre-loading
- Simplifies management by keeping cache close to execution
- Reduces network overhead for frequently accessed models
Best suited when:
- Models are relatively small and fit within node storage constraints
- Job startup latency benefits from pre-loaded models
- The team prefers simpler storage management
Azure Storage-Backed Persistence
For scenarios with larger models or longer download times:
- Azure Blob Storage with Blob CSI driver for shared persistent volumes
- Model artifacts stored once in blob storage mounted by multiple GPU pods
- Reduces job startup latency by avoiding repeated model downloads
- Provides durability across pod restarts and node failures
Best suited when:
- Models are large and download times significantly impact performance
- Multiple workers need concurrent access to the same model artifacts
- Durability across node failures is essential
The Azure Blob CSI driver documentation provides implementation details for this pattern.
Security Architecture
Production diffusion platforms require a security-first approach across multiple layers:
Edge Security
- DNS with Azure Front Door and Application Gateway with WAF
- TLS termination with certificates stored in Azure Key Vault
- WAF rules to block malicious requests and prevent common attack vectors
- Rate limiting to protect against abuse and cost overruns
Workload Isolation
- Separate node pools for API, GPU, and system components
- Kubernetes namespaces for tenant or environment isolation
- Resource quotas and limits to prevent noisy neighbor problems
- Network policies to control traffic between components
Identity and Access Management
- Microsoft Entra Workload ID for workload authentication to Azure resources
- Azure Key Vault with Secrets Store CSI Driver for secret management
- Kubernetes RBAC scoped to minimum required permissions
- Private endpoints for Azure service access when possible
The Microsoft Entra Workload ID for AKS documentation provides detailed implementation guidance for this security model.
Observability and Monitoring
Effective operation of diffusion workloads requires visibility into both application behavior and GPU hardware performance:
Application Monitoring
- Application Insights with OpenTelemetry for request tracking and error analysis
- Structured logging with correlation IDs for distributed tracing
- Dashboard metrics for request rates, latency, and error rates
- Integration with AKS metrics for cluster health assessment
Hardware Monitoring
- NVIDIA DCGM exporter for GPU-level metrics
- Azure Managed Prometheus for metric collection and storage
- Azure Managed Grafana for visualization and alerting
- Metrics for GPU utilization, memory pressure, temperature, and power consumption
The AKS monitoring documentation provides comprehensive guidance on implementing this observability stack.
Operational Dashboards
Critical dashboards should include:
- Request volume and latency by model type
- GPU utilization and memory pressure across the cluster
- Queue depth and dispatch latency for the chosen dispatch pattern
- Job success and failure rates with error categorization
- Cost metrics showing resource utilization and optimization opportunities
CI/CD and Deployment Strategy
A production-grade deployment model should be:
- Automated: Full pipeline from code commit to production deployment
- Immutable: Container images built from Git commit SHA with no mutable tags
- Secretless: Credentials managed externally through Azure Key Vault
- Reversible: Rollback capabilities with zero-downtime deployments
- Environment-aware: Promotion through environments with approval gates
A practical implementation uses:
- GitHub Actions with OpenID Connect and Azure workload identity federation
- Azure Container Registry as the image source of truth
- Environment-specific deployments with approval gates for production
- Kubernetes rolling updates with health checks and smoke tests
- Infrastructure as code for platform components with controlled change management
The GitHub Actions documentation provides detailed guidance on implementing this secure CI/CD pattern.
Scaling Strategies
Effective scaling requires treating different workload classes independently:
API Tier Scaling
- Scales based on concurrent request volume
- Horizontal pod autoscaler with CPU/memory metrics
- Connection pooling and request batching for improved efficiency
- Rate limiting to prevent abuse and ensure fair usage
Dispatch Scaling
- Kubernetes-native: Scales based on pending work or queue depth
- Service Bus + KEDA: Scales based on explicit queue backlog
- Cluster autoscaling to add/remove nodes based on pending capacity
- Predictive scaling based on historical demand patterns when available
GPU Worker Scaling
- Scales based on job demand or queue backlog
- GPU-aware autoscaling using custom metrics like pending inference requests
- Multi-instance GPU configurations for lighter workloads
- Spot instances for cost optimization when fault tolerance is acceptable
The KEDA documentation provides detailed guidance on implementing event-driven autoscaling for these patterns.
Alternative Approaches
For teams with different requirements, several alternative approaches exist:
KAITO
KAITO provides a managed solution for rapid experimentation with supported model presets on AKS:
- Simplified deployment with pre-configured model environments
- Optimized for supported models rather than custom pipelines
- Less suitable for custom diffusion pipelines or specialized workflows
The KAITO documentation provides details on this alternative approach.
AI Toolchain Operator Add-on
The AI Toolchain Operator provides more managed LLM serving with AKS-native operational features:
- Standardized deployment patterns for supported models
- Integrated monitoring and lifecycle management
- Less suitable for custom diffusion pipelines or application-specific dispatch logic
Business Impact and Considerations
Implementing this architecture delivers several business benefits:
- Operational Excellence: Production-ready platform with built-in observability, security, and automation
- Cost Efficiency: Optimized resource utilization through proper scaling and isolation
- Developer Productivity: Self-service platform with standardized patterns and reduced operational overhead
- Scalability: Ability to handle variable demand from prototype to production scale
- Risk Reduction: Comprehensive security, monitoring, and rollback capabilities
The total cost of ownership depends on several factors:
- GPU instance type and utilization rates
- Storage requirements for models and outputs
- Network bandwidth and egress costs
- Operational overhead and staffing requirements
Organizations should start with a proof-of-concept implementation focused on their most critical use case, then expand the platform as additional requirements emerge.
Implementation Roadmap
Organizations can adopt this architecture incrementally:
- Phase 1: Single-region deployment with basic Kubernetes-native dispatch
- Phase 2: Add observability stack and security hardening
- Phase 3: Implement external dispatch with Service Bus and KEDA for complex workloads
- Phase 4: Multi-region deployment with global load balancing
- Phase 5: Advanced optimization with MIG, spot instances, and predictive scaling
Each phase delivers immediate value while building toward a comprehensive platform.
Conclusion
Running diffusion models at scale is fundamentally a platform engineering challenge with specialized hardware requirements. By treating AKS as the control surface for isolation, observability, identity, and repeatable rollout discipline, organizations can build systems that scale beyond benchmarks and survive real operational demands.
The architectural pattern described—separating control-plane traffic from GPU execution, choosing appropriate dispatch mechanisms, implementing robust security, and maintaining comprehensive observability—provides a foundation for production diffusion workloads. This approach enables organizations to move from prototype experiments to reliable, scalable services that deliver consistent value to users while managing operational complexity and cost.
As diffusion models continue to evolve and new use cases emerge, this fundamental architecture will remain adaptable, with only the specific implementation details needing updates to accommodate new model types, hardware capabilities, and operational requirements.
Comments
Please log in or register to join the discussion