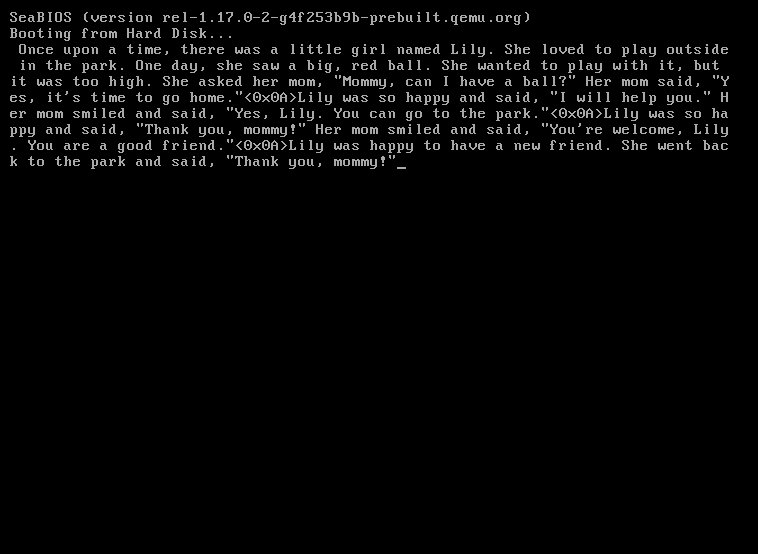
A remarkable achievement in extreme computing efficiency, sectorllm demonstrates a complete Llama2 inference engine that runs in just 1369 bytes of x86 assembly, booting directly from disk without any operating system.
In an era where AI models often require massive computational resources, the sectorllm project presents a fascinating counterpoint—a fully functional Llama2 inference engine that fits within an astonishingly small footprint. This isn't just another optimization exercise; it represents a philosophical statement about what's possible when we strip away all unnecessary complexity and focus on the absolute essentials of AI computation.
At its core, sectorllm accomplishes something extraordinary: it implements a complete transformer-based language model that can boot directly from a storage device, load a quantized model, and generate text—all before any operating system begins to initialize. The system runs the stories260K model, a tiny but functional neural network with 260K parameters spread across 5 layers and 8 attention heads, using a vocabulary of just 512 tokens.
The technical achievements behind this implementation are worthy of deeper examination. The entire inference engine is compressed into 1369 bytes of x86 real mode assembly code—the kind of environment typically associated with basic bootloaders in the early days of personal computing. This extreme constraint necessitates clever optimization strategies that challenge conventional approaches to AI implementation.
One particularly elegant solution is the custom binary format for the model weights, designed specifically to minimize decoding overhead. The Python quantization script packs weights into int8 precision using a global absolute maximum scale, dramatically reducing the space required compared to floating-point representations. Further efficiency gains come from precomputing and embedding lookup tables for exponential and SiLU activation functions directly into the code, eliminating the need for runtime computation of these expensive operations.
The architecture demonstrates impressive fusion of weight matrices—combining query, key, value, and gate/up projections into single operations rather than separate matrix multiplications. This optimization reduces the number of instructions needed during inference, a critical consideration when working with such severe space constraints. The KV cache is similarly optimized through runtime quantization to int8 with per-token scaling, allowing the entire 512-token context window to fit within the limited memory segments available in real mode.
What makes sectorllm particularly compelling is its demonstration of the fundamental principles that underpin large language models. By implementing these complex neural networks in such an austere environment, the project reveals the essential computational requirements of transformer architectures, stripped of all modern abstractions and conveniences. It serves as both an educational tool and an engineering marvel, showing how attention mechanisms, layer normalization, and token prediction can be implemented with minimal resources.
The limitations of the system are equally revealing. The current implementation uses greedy argmax for sampling, the simplest possible approach to token selection. While this works for basic text generation, more sophisticated sampling strategies like top-k or temperature sampling would require additional code that couldn't be accommodated within the 1369-byte limit. Similarly, the model architecture and prompt are hardcoded, reflecting the trade-offs between flexibility and minimalism.
Perhaps most interesting is what this project represents in the broader context of computing efficiency. As AI models grow increasingly large and resource-intensive, sectorllm stands as a reminder that fundamental computation can be achieved with remarkably modest means. This has implications for edge computing, embedded systems, and even theoretical computer science, demonstrating the boundaries between what is possible and what is merely convenient.
The project also raises intriguing questions about the nature of intelligence and computation itself. If a functional language model can be implemented in a few thousand bytes of assembly, what does that tell us about the relationship between model size and capability? How much of modern AI infrastructure is essential to functionality, and how much is incidental to our current technological paradigms?
For those interested in exploring this fascinating intersection of minimal computing and artificial intelligence, the sectorllm repository provides the complete implementation. The project includes a straightforward build process: running ./download.sh && python3 quantize.py && make run will download the model, quantize it, and execute the inference engine. The code is open source and welcomes contributions from assembly programmers who might find ways to further reduce the binary size.
In a world where AI models are increasingly seen as black boxes requiring massive infrastructure, sectorllm offers a refreshing perspective—one that celebrates the elegance and efficiency possible when we return to computing fundamentals. It's not just a technical curiosity; it's a reminder that innovation often happens at the boundaries of what we consider possible.
Comments
Please log in or register to join the discussion