A deep investigation into write-heavy database performance reveals troubling throughput variation in Postgres across versions 16-19 beta1, while MySQL's InnoDB storage engine shows more consistent results on a large 48-core server. The findings raise important questions about regression patterns and storage engine efficiency for write-intensive workloads.
The story of database performance is rarely told in clean, linear progressions. Instead, it unfolds through careful measurement, patience, and a willingness to question assumptions about what we think we know about our most trusted systems. This blog post represents one such step in that journey, a methodical exploration of write-heavy workloads on modern Postgres and MySQL that reveals patterns worth examining.
The benchmark results presented here are part of an ongoing investigation into potential performance regressions in Postgres versions 16, 17, 18, and 19 beta1. While the author remains appropriately cautious about drawing definitive conclusions, the data tells a compelling story about how these two database systems handle write-intensive operations at scale.
The Hardware and Configuration
The testing environment is substantial: a 48-core server powered by an AMD EPYC 9454P processor with SMT disabled, 128GB of RAM, and two Intel D7-P5520 NVMe storage devices configured in RAID 1 with ext4 filesystem. The systems were compiled from source: Postgres versions 15.17, 16.13, 17.9, and 18.3; MySQL version 8.4.7.
What makes this benchmark distinctive is its deliberate design choices. The sysbench microbenchmarks were run for two hours each, far longer than the typical 15-minute duration, and the tables were sized larger than memory to ensure the storage layer remained under sustained pressure. After each test, a manual vacuum was performed to reset state. The goal was to isolate the overhead of MVCC garbage collection, vacuum for Postgres and purge for InnoDB, which is precisely where subtle regressions might hide.
The configuration files were carefully maintained across versions, with Postgres 18 using settings as close as possible to Postgres 17, including the use of io_method=sync to ensure comparable I/O behavior.
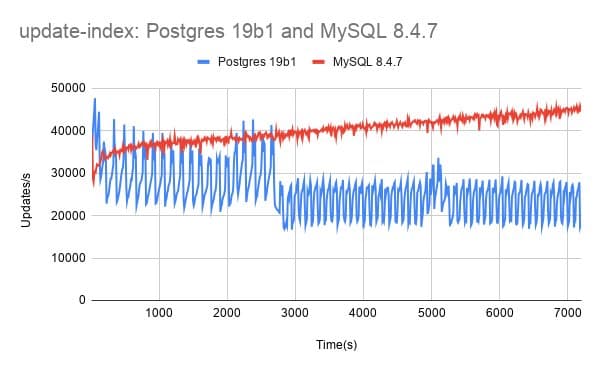
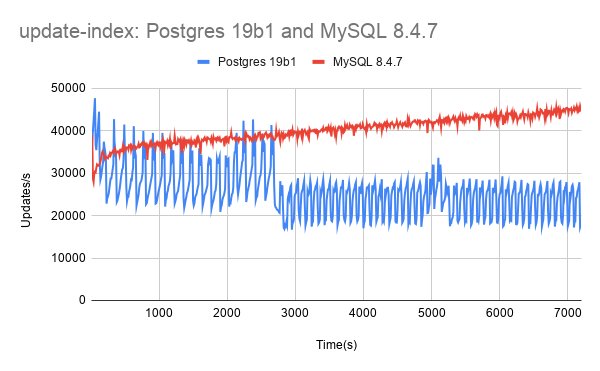
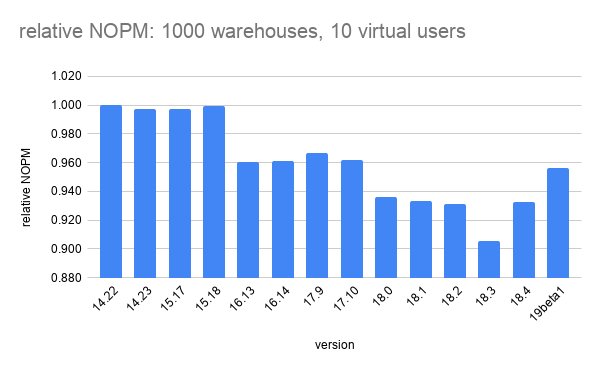
Throughput Variation: The Core Challenge
The most striking finding is that Postgres suffers significantly from throughput variation on these write-heavy tests, while MySQL with InnoDB does not exhibit the same instability. This is not merely an academic observation. In production environments where consistent performance matters as much as peak throughput, variation itself becomes a problem.
{{IMAGE:2}}
The relative QPS metric, calculated as QPS for some version divided by QPS for Postgres 15.17, provides a clear lens for examining regressions. When values fall below 1.0, performance has degraded relative to the baseline. The data shows concerning trends across multiple Postgres versions:
- update-index: Throughput dropped from 0.94 in version 16.13 to 0.86 in version 17.9, recovered slightly to 0.87 in 18.3, then improved to 0.92 in 19 beta1
- update-zipf: A more pronounced decline from 0.95 to 0.81 across the version progression
- write-only: Similarly, performance decreased from 0.94 to 0.81, with 19 beta1 showing partial recovery at 0.84
These patterns suggest something systematic may be occurring in how Postgres handles write-heavy workloads as versions progress. Whether this constitutes a regression or an intentional trade-off remains an open question.
The InnoDB Advantage on Writes
The comparison with MySQL 8.4.7 and InnoDB reveals a significant performance gap. In six of ten write-heavy tests, InnoDB achieves substantially higher average throughput. The update-index test is particularly dramatic, with InnoDB delivering approximately 1.55 times the throughput of Postgres.
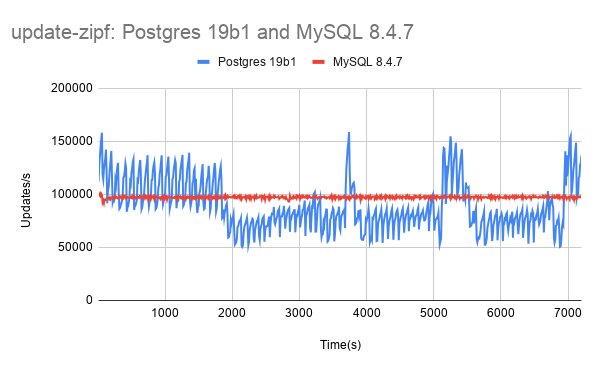
The vmstat and iostat data normalized by operation rate provides insight into why this gap exists. For the update-index test, Postgres performs approximately 1.20 times more write IO per operation than InnoDB. This additional storage overhead translates directly into reduced throughput when I/O becomes the bottleneck.
The context switch and CPU metrics add another dimension. InnoDB uses more CPU and generates significantly more context switches per operation in the update tests. This pattern suggests InnoDB is doing more work per operation but doing it more efficiently from a storage perspective, a trade-off that favors throughput when storage is the limiting factor.
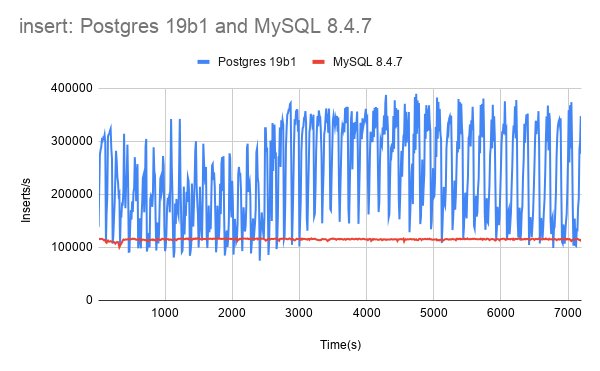
However, the picture is not uniformly favorable for InnoDB. In three of ten tests, Postgres outperforms MySQL. The insert test stands out dramatically, with Postgres achieving approximately 2.06 times the throughput of InnoDB. Here, the dynamics reverse: Postgres does more write IO per operation but handles the insert workload more efficiently. This reversal suggests that the two systems optimize for different access patterns, and neither holds a universal advantage.
The Storage Efficiency Question
The iostat data reveals a consistent pattern across these write-heavy tests: Postgres performs more write IO per operation than InnoDB. This is not simply a matter of raw throughput but reflects fundamental differences in how the two systems manage their on-disk formats and write-ahead logging.
For update-index operations, Postgres writes approximately 53.351 KB per operation compared to InnoDB's 44.326 KB. This difference compounds across thousands of operations per second. The insert test shows an even larger gap: 5.059 KB per operation for Postgres versus 3.029 KB for InnoDB.
These numbers matter beyond raw performance. In storage-constrained environments or on systems where write endurance is a concern, the additional IO per operation becomes a tangible cost. The efficiency question extends beyond CPU and into the realm of total cost of ownership.
Understanding the Regression Question
The author frames this work as a step in understanding whether regressions exist in Postgres versions 16 through 19 beta1. The evidence is suggestive but inconclusive. Several factors complicate interpretation:
First, the baseline version 15.17 might itself have performance characteristics that do not represent an ideal reference point. Second, the tests are specifically write-heavy and larger than memory, conditions that stress particular subsystems. Third, the variance in Postgres throughput could reflect optimization efforts that improved other workloads at the expense of these specific patterns.
The fact that 19 beta1 shows improvement over 18.3 in several tests suggests the Postgres development community may be aware of and addressing performance concerns. Whether these improvements are sufficient or represent fundamental architectural changes remains to be seen.
Implications for Production Systems
For database administrators and architects working with write-heavy workloads, these results carry practical implications. The choice between Postgres and MySQL is not merely about features or ecosystem preference but about how each system handles sustained write pressure.
The variance issue in Postgres is particularly relevant for systems requiring predictable latency. In environments where tail latency matters, such as real-time applications or systems with strict SLA requirements, the instability in throughput could translate directly into user-visible impact.
Conversely, the superior insert performance of Postgres suggests it may be better suited for write-heavy workloads dominated by new row creation rather than updates. The workload mix matters significantly in determining which system provides better performance.
Counter-perspectives and Caveats
It would be premature to draw sweeping conclusions from these tests alone. Several important caveats apply:
The sysbench microbenchmarks are deliberately synthetic. They isolate specific operations but do not represent the complex, mixed workloads found in most production environments. The 2-hour test duration provides more data than typical benchmarks but still represents a snapshot rather than sustained production behavior.
The hardware configuration, while substantial, represents one specific setup. The NVMe storage, large core count, and specific memory configuration could all influence results differently on other hardware profiles.
Furthermore, Postgres and MySQL are not static targets. Each new version brings optimizations, bug fixes, and sometimes architectural changes that can shift performance characteristics. The version-by-version comparison provides useful data points but should not be extrapolated into permanent rankings.
The vacuum and purge mechanisms underlying MVCC are complex systems with many tuning parameters. The configurations used here, while reasonable, represent one set of choices among many possibilities. Different autovacuum settings, work_mem allocations, or maintenance_work_mem values could yield different results.
Looking Forward
This work represents the kind of careful, methodical investigation that benefits the broader database community. The identification of potential regression patterns provides specific targets for investigation by the Postgres development community. The comparative data with InnoDB offers a reference point for understanding storage engine efficiency.
As the author notes, this is a step in a journey rather than a destination. The next steps likely involve deeper investigation into the specific code paths responsible for the observed patterns, testing with additional configurations, and potentially examining whether the regression patterns correlate with specific patches or feature additions in the Postgres codebase.
The broader lesson may be that database performance is not a static property but a dynamic characteristic that requires ongoing measurement and attention. Systems that perform well today may encounter performance challenges as workloads evolve or as optimizations for one pattern inadvertently impact another.
For practitioners, the message is clear: measure your specific workloads on your specific hardware. General benchmarks provide useful context but cannot substitute for testing with your actual access patterns, data sizes, and performance requirements. The variance story alone should prompt testing across extended time periods rather than relying on short benchmark runs that might capture peaks or valleys rather than typical behavior.
The database ecosystem benefits from this kind of transparent, detailed benchmarking. As both Postgres and MySQL continue to evolve, measurements like these provide accountability and direction for future optimization efforts. Whether the patterns identified here persist, worsen, or are addressed in future versions, the act of measurement itself serves the community well.
Comments
Please log in or register to join the discussion