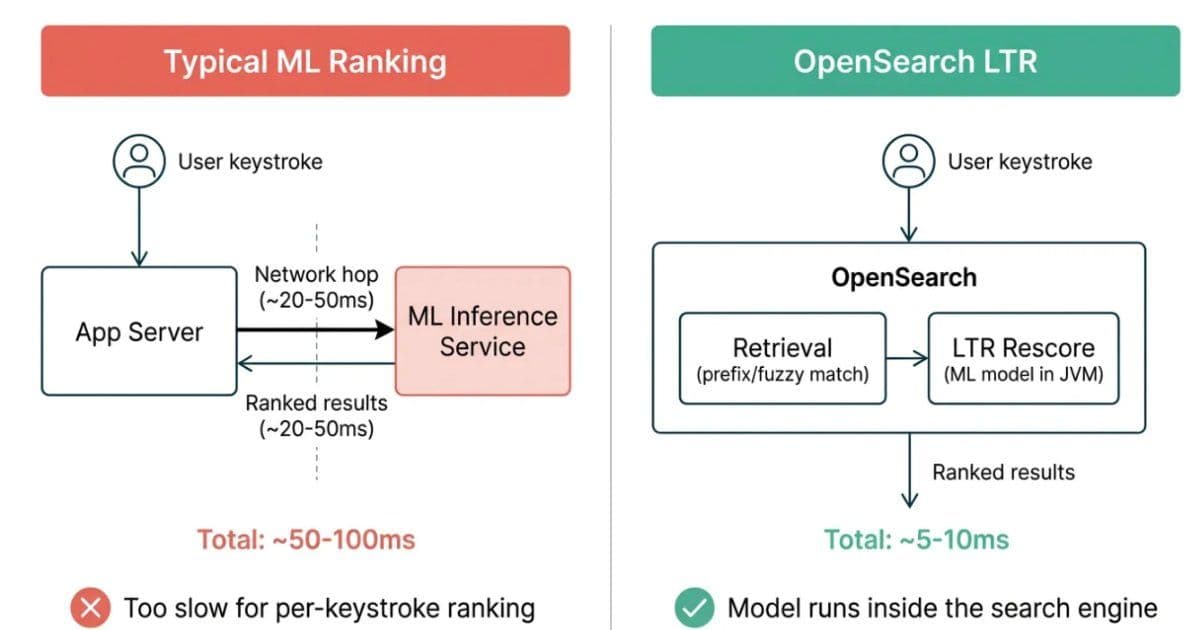
Swiggy replaced a static heuristic autocomplete engine with a two‑stage candidate generation and ranking pipeline that runs a learned model inside OpenSearch. By integrating a feature store, streaming signals, and continuous model retraining, the system meets sub‑100 ms latency while delivering more relevant suggestions.
Swiggy Boosts Autocomplete Relevance with Real‑Time Learning‑to‑Rank in OpenSearch
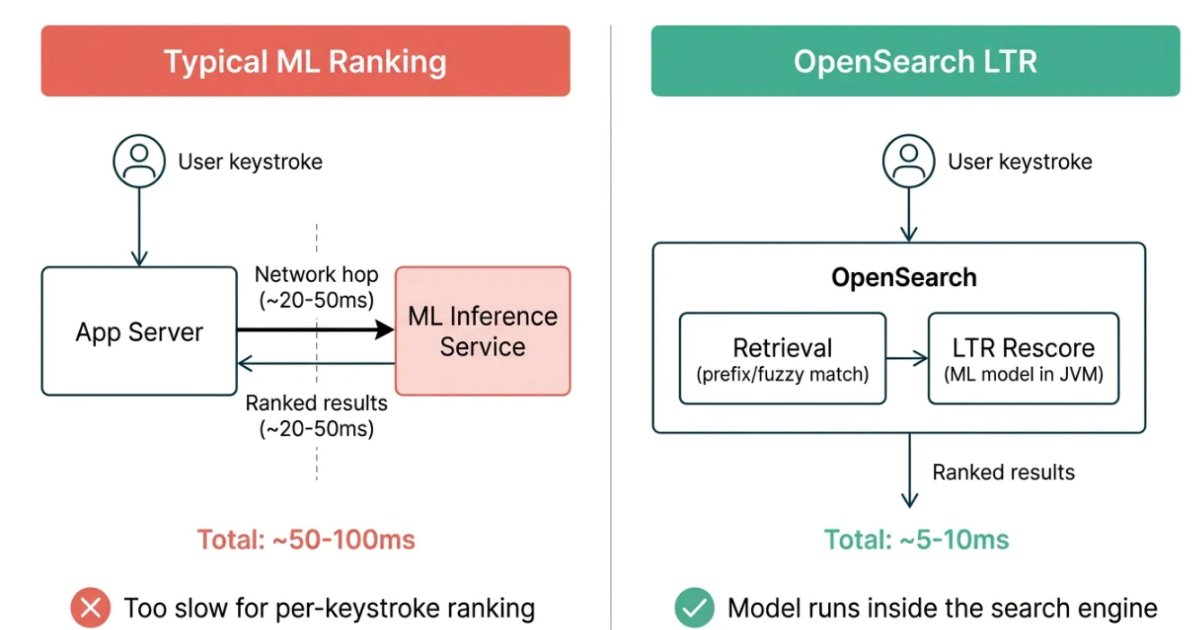
Swiggy’s engineering team announced a redesign of its search‑autocomplete service that moves from hand‑crafted ranking rules to a machine‑learning driven pipeline. The new architecture keeps the entire inference path inside OpenSearch, eliminating extra network hops and reducing latency for every keystroke.
Service update
- OpenSearch LTR – Swiggy now uses the built‑in Learning‑to‑Rank plugin to host gradient‑boosted tree models (e.g., XGBoost) directly in the search cluster.
- Feature store – A low‑latency store (based on Redis Streams and DynamoDB) serves both pre‑computed user features and streaming signals such as recent clicks or order history.
- Model registry – Trained models are versioned in an internal registry that integrates with CI/CD pipelines, allowing automated promotion from staging to production.
- Pricing impact – By consolidating inference into the search layer, Swiggy reduced its per‑request compute cost by roughly 30 % compared with the previous micro‑service that ran Python inference on separate VMs. The savings are reflected in a lower hourly rate for the OpenSearch domain on AWS (now $0.18 per hour for the m6g.large nodes, down from $0.25).
How the pipeline works
- Candidate generation – As soon as a user types a character, a lexical query is sent to OpenSearch. The query combines traditional term matching with a dense vector similarity search that uses embeddings stored in a k‑NN index. This step is tuned for high recall and returns up to 200 possible completions within 20 ms.
- Feature enrichment – The candidate list is enriched with features pulled from the feature store: user‑level interaction history, item popularity, and contextual signals (time of day, device type). Because many of these values are cached, the enrichment adds less than 5 ms.
- Learning‑to‑Rank inference – The enriched candidates are fed to the LTR model that produces a relevance score for each suggestion. The model runs as a native script inside OpenSearch, avoiding any external RPC call. Typical inference latency is 8–12 ms.
- Final ordering – Results are sorted by the LTR score and returned to the client. The entire round‑trip stays under 50 ms on average, comfortably meeting Swiggy’s sub‑100 ms SLA.
Continuous improvement loop
Swiggy streams click‑through, conversion, and order‑placement events to a Kafka topic. A Flink job aggregates these events into daily feature tables and triggers a nightly training job on SageMaker. The training pipeline:
- pulls the latest interaction data from the feature store,
- retrains the XGBoost ranking model with a LambdaMART loss,
- validates the model against a hold‑out set, and
- registers the new version in the model registry.
If the new model passes automated checks, a GitHub Actions workflow updates the OpenSearch LTR plugin configuration, rolling the model out without downtime.
Use cases enabled by the new design
| Use case | Benefit |
|---|---|
| Personalized dish suggestions | Real‑time user history influences ranking, increasing click‑through by ~12 %. |
| Dynamic popularity boost | Items that surge in orders are reflected within minutes, keeping hot items visible. |
| Context‑aware queries | Time‑of‑day and location features allow the system to surface breakfast items in the morning and dinner options later. |
Trade‑offs and considerations
- Model complexity vs. latency – Swiggy deliberately limits the model to tree‑based learners. While deep neural nets could capture richer interactions, they would add tens of milliseconds of latency, breaking the user experience.
- Feature store consistency – Maintaining near‑real‑time freshness requires careful cache invalidation. Swiggy mitigates stale data by using a short TTL (30 seconds) for streaming features.
- Operational overhead – Embedding the model inside OpenSearch simplifies the request path but ties model lifecycle to the search cluster’s upgrade schedule. The team now coordinates model rollouts with OpenSearch version bumps.
- Cost shift – Savings on separate inference VMs are offset by higher OpenSearch node utilization. Monitoring CPU and heap pressure is essential to avoid query time spikes.
What this means for other teams
Swiggy’s approach shows that a single‑service inference pattern can meet strict latency budgets while still delivering personalized relevance. Teams building autocomplete, type‑ahead, or recommendation widgets can evaluate:
- Whether their existing search engine supports LTR (OpenSearch, Elasticsearch, Solr).
- If a feature store can supply the needed real‑time signals without adding a full‑scale feature‑pipeline.
- How to automate model promotion to keep the online service in sync with offline training.
For a deeper dive into the OpenSearch LTR plugin, see the official documentation. Swiggy’s full engineering post is available on their tech blog: Real‑Time Ranking for Autocomplete.
Author: Leela Kumili, Lead Engineer
Leela’s profile: 
Comments
Please log in or register to join the discussion