
A backend that passes the demo can still fail in the spaces between writes, commits, subscriptions, and retries.

Problem
Most backend failures worth studying do not appear while clicking through the intended flow. They appear between two operations that the demo treats as one: writing bytes and updating an index, subscribing to a stream and starting work, committing durable state and publishing a live event.
The DEV Community article describes two internship projects that make this concrete. The first was a database-free append-only event store built with Python and FastAPI. The second was a streaming persona-refinement endpoint using FastAPI, Celery, Redis pub/sub, and Server-Sent Events, documented well by MDN.
Both tasks look small if described as feature work. Append records to a file. Stream model output to a browser. The interesting part is that neither feature is one system. The write-ahead log is a protocol between append, index, read, and recovery. The streaming endpoint is a protocol between browser, API relay, Redis, worker, model, and database.
That distinction matters because distributed systems do not fail at feature boundaries. They fail at consistency boundaries.
Solution Approach
A file-backed event store is still a storage engine
The event store used compact newline-delimited JSON. Each event was encoded as UTF-8, appended to events.log, and indexed in memory by event_id to a byte offset and byte length. Reads could then jump directly to a record with seek() and read() instead of scanning the file.
That is a reasonable shape for a small append-only log. It keeps the data model simple, makes recovery understandable, and avoids inventing a page cache or secondary index too early. It also removes the database layer that normally absorbs many unpleasant details.
Once PostgreSQL or another database is out of the design, the application owns the storage contract. It must decide what a committed record means, how record boundaries are represented, what recovery does after a crash, and which operations share a lock.
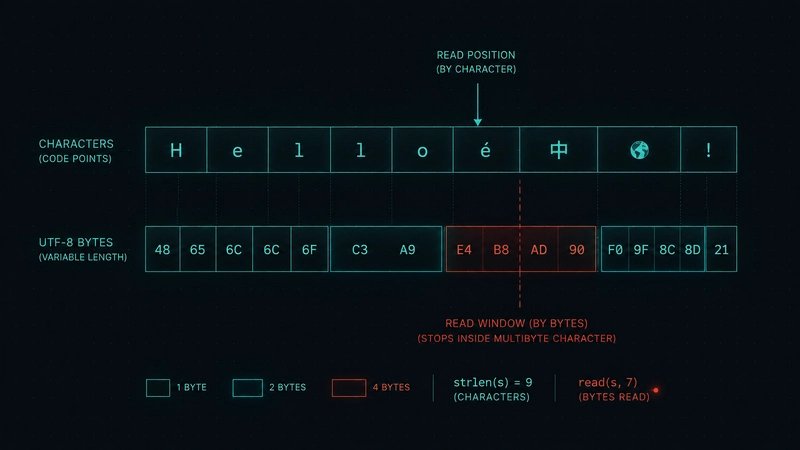
The first failure mode was byte accounting. Python strings count Unicode code points. Files are addressed in bytes. For ASCII payloads, character length and byte length match, which makes the bug easy to miss. For é or 🎉, they diverge. If the index stores len(serialized_json) instead of len(serialized_json.encode("utf-8")), reads can stop inside a multibyte character. The result is invalid UTF-8 or truncated JSON.
The fix was not complicated: store the encoded byte length. The more important engineering move was writing a regression test with non-ASCII data so the bug cannot be reintroduced by accident.
The second failure mode was a consistency snapshot. A /stats endpoint read the file size from disk and the event count from the in-memory index. If those reads happened outside the append lock, a concurrent request could observe bytes already flushed to the file but not yet reflected in the index. Both values were individually accurate, but together they described a state the system never committed.
The fix was to move stats behind the same lock as append. That made stats an observation of a single transaction boundary rather than two unrelated reads.
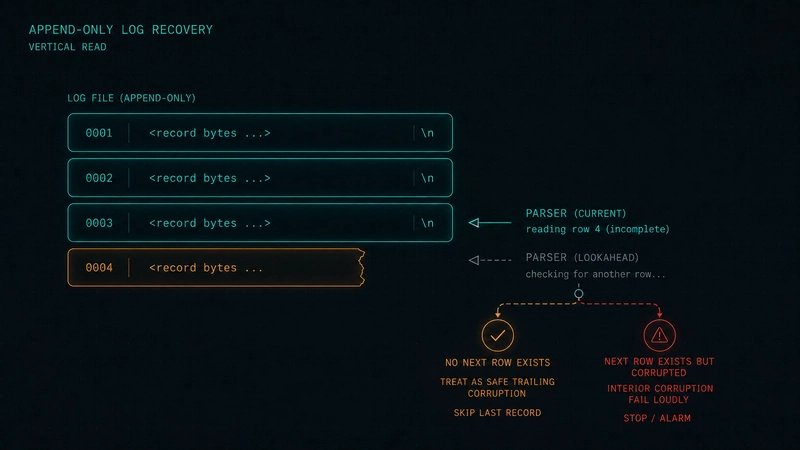
The third failure mode was recovery from a torn tail. A valid append-only log should tolerate a process crash during the final write. It should not tolerate silent corruption in the middle of committed history.
Those cases need different behavior. A malformed final fragment can be treated as an interrupted append and skipped. A malformed interior record should fail loudly, because ignoring it means the service is now lying about its durable state.
The article’s lookahead recovery loop captures that distinction. It reads the current line and the next line. If parsing fails and there is no next line, recovery skips the incomplete trailing record. If parsing fails and there is another line after it, startup fails because committed history is damaged.
This is the storage-engine version of a larger rule: recovery logic and write logic are one protocol split across time. If append says a newline-delimited UTF-8 JSON record is the unit of commitment, recovery must interpret the file with the same contract.
Streaming AI output is a distributed workflow
The second project moved from a local file protocol to a multi-process workflow. The endpoint allowed a user to refine an AI persona and watch model output arrive incrementally over SSE. The worker could emit ordinary streamed text, or it could regenerate persona files and skills.
A useful architecture emerged:
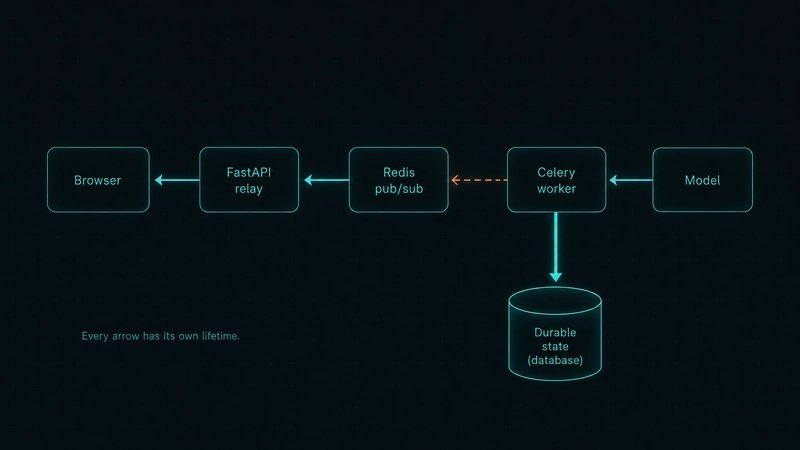
The browser holds an SSE connection to FastAPI. FastAPI subscribes to a Redis channel and relays messages. A Celery worker performs the long-running model call, writes durable results to the database, and publishes live events to Redis.
That design separates request lifetime from work lifetime. The API process does not block on model execution. The worker can run longer jobs. The user still sees progress.
It also creates several failure domains. Redis pub/sub is ephemeral. Celery can retry. The database is durable. The browser can disconnect. The model stream can be slow without being dead.
The first ordering rule was subscribe before enqueue. Redis pub/sub does not retain messages for late subscribers. If the worker starts quickly and publishes before the API relay has subscribed, the beginning of the stream disappears. The test records the order and asserts that subscription happens before the Celery task is enqueued.
That is a small test with high value. It forces the actual race instead of relying on timing in normal development.
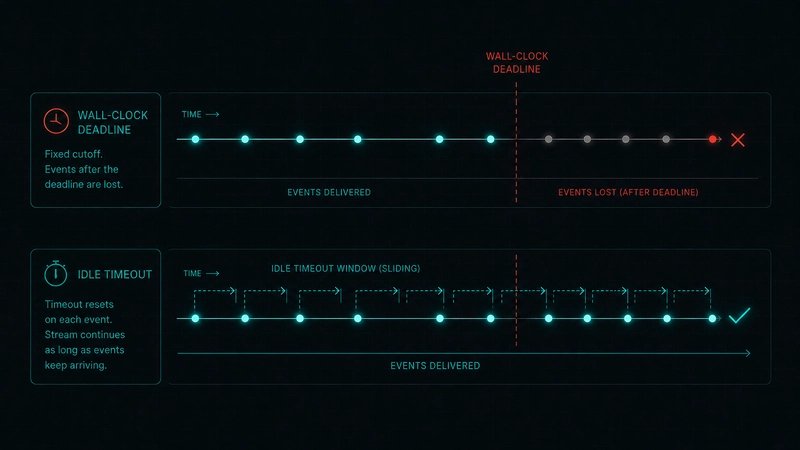
The second issue was timeout semantics. A fixed wall-clock deadline treats a long healthy stream the same as a dead worker. That is the wrong model. The failure condition is silence, not age.
The fix was an idle timeout. Each delivered event resets the deadline. If events keep arriving, the stream remains alive. If no events arrive for the configured interval, the relay times out.
This distinction shows up often in distributed systems. A duration cap answers, “How long has this operation existed?” An idle timeout answers, “How long has this operation been quiet?” For streaming protocols, the second question is usually the one that maps to failure.
The most serious issue was retry behavior after durable writes. The Celery task writes assistant messages, usage information, persona files, and skills. It also publishes ephemeral Redis events for the live stream. Those two actions cannot be made atomic with ordinary Redis pub/sub and a relational database.
That means the system needs an explicit consistency policy. If Redis publish fails after the database commit, retrying the whole task can duplicate the assistant turn or usage accounting. If the task suppresses the Redis failure, the live stream may degrade, but stored state remains correct.
The right hierarchy is durable state first. Redis delivery is best-effort. A publish failure should be logged, but it should not cause Celery to re-execute committed work.
This is not free. A user may miss a token or need to reload to see the final result. But the alternative is worse: an ephemeral transport failure gets to decide whether durable business state runs twice.
Trade-offs
The write-ahead log project trades operational simplicity for implementation responsibility. A flat file is easy to inspect, easy to append to, and easy to reason about in a prototype. It also means the application must handle byte lengths, torn writes, startup replay, locking, and durability language precisely.
Calling flush() is a good example. It moves Python-buffered data to the operating system. It does not provide the same guarantee as fsync(). If the process crashes, flushed bytes are likely available to recovery. If the machine loses power, the guarantee is weaker. A production storage engine has to say that clearly because durability is not a boolean property.
The streaming endpoint makes a different trade. It favors responsiveness and background execution, but it accepts that the live event channel is not the source of truth. Redis pub/sub is a delivery mechanism, not a durable log. That is fine if the database remains authoritative and clients can recover by reloading committed state.
A stronger design could use Redis Streams or a durable message broker if replayable delivery mattered. That would add consumer offsets, retention policy, and operational complexity. For a live UI stream, best-effort events plus durable database state may be the better contract.
The API pattern is the same in both systems: define the boundary, then make each side honest about what it owns.
For the event store, the boundary is between bytes on disk and index entries in memory. The lock makes append and index update one logical operation from the perspective of readers and stats. Recovery then rebuilds the index from the disk format using the same record definition.
For the AI refinement endpoint, the boundary is between durable database writes and ephemeral stream delivery. The task commits state before announcing completion. Publish failures do not control retry after durable work has happened. The client experience can degrade, but the stored conversation must not fork.
There is also an API design lesson. Streaming endpoints are not just normal endpoints with incremental output. They need documented behavior for listener readiness, idle timeout, completion events, disconnects, and replay. Without that contract, every caller has to infer semantics from timing, and timing is exactly where these bugs hide.
The broader pattern is practical. Treat every backend feature as a set of smaller protocols. Ask what happens if the process crashes between two lines. Ask what a concurrent request can observe. Ask whether a retry is still safe after a commit. Ask whether the transport is allowed to be less reliable than the database.
The happy path is still useful. It proves the feature can work when the world cooperates. Production asks a harsher question: what state remains when the world stops cooperating halfway through an operation. The answer lives in byte counts, locks, timeout definitions, retry rules, and recovery tests.
Comments
Please log in or register to join the discussion