
Indie multiplayer titles often ship with three hidden pitfalls—client‑authoritative state, unversioned player saves, and monolithic server binaries—that look harmless at MVP scale but crumble between 50 and 500 concurrent users. This article breaks down each failure, shows why it hurts consistency and availability, and presents pragmatic, server‑authoritative, event‑sourced, micro‑service‑oriented solutions.
Three Architectural Mistakes Indie Multiplayer Games Make When Scaling

Indie studios love the rapid feedback loop of shipping a playable prototype within weeks. The first few dozen players are forgiving, the network traffic is tiny, and a single binary that does everything feels just enough. The problem surfaces the moment the player count climbs past the low‑hundreds: the architecture that survived the MVP stage begins to fracture, leading to cheating, data loss, and massive latency spikes.
Below is a hard‑won checklist of the three most common failure modes I have observed while running UE, Unity, and Godot survival/MMO servers for years. For each, I explain the underlying consistency model, the scalability implications, and a concrete, production‑ready remedy.
1. Trusting the client for any value that affects other players
The pattern
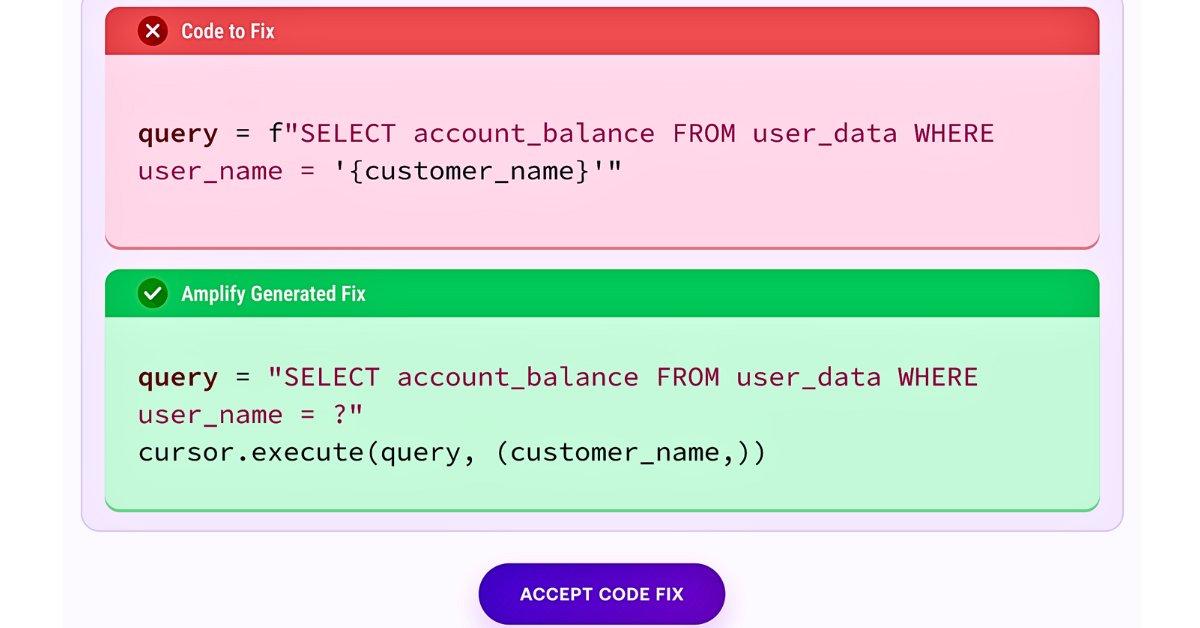
The client computes a result—"I dealt 25 damage to player X" or "my survival time is 14:32"—and sends that raw number to the server. The server dutifully writes it to the authoritative state.
Why it collapses
When a player reverse‑engineers the client binary, they can inject arbitrary numbers. Instantly you get invincible characters, leaderboard inflation, or resource duplication. The moment a few cheaters appear, honest players lose trust and churn.
Consistency model impact
This is a classic violation of server‑authoritative consistency. The client becomes a source of truth for shared state, turning the system into an eventually consistent mess where the truth diverges per peer.
The fix – Intent‑only messages
- Client → Server: "I shot at player X from position (12, 4, 7)".
- Server: validates line‑of‑sight, weapon cooldowns, and damage tables, then applies the result to the world state.
The round‑trip adds a few milliseconds of latency, but the cheat surface drops to near zero because the server is the only place where game‑logic runs. Single‑player progression (e.g., cosmetic unlocks) can stay client‑side; anything that crosses a player boundary must be server‑authoritative.
Real‑world example
A small Unity‑based battle‑royale shipped with client‑authoritative health. Within a week, a modder posted a patched client that set health to 9999. The developers rolled out an intent‑only protocol, added a simple validation layer, and the cheat rate fell from dozens per hour to virtually none.
2. No versioning or event log on player save data
The pattern
Each player’s progress is stored as a single JSON blob. On every checkpoint the blob is overwritten. Backups rely on the host’s nightly snapshot.
Failure scenarios
| Situation | Symptom |
|---|---|
| Bad patch corrupts saves | Hundreds of players lose hours of progress overnight |
| Duplication exploit | No way to tell who benefitted, no rollback point |
| Parallel sessions (mobile + desktop) | Race condition silently overwrites the newer state |
| Support ticket "I lost 3 h of progress" | Only a day‑old snapshot is available |
Consistency implications
Without immutable history you cannot replay or audit state transitions. The system behaves like a write‑through cache with no fallback, making it impossible to guarantee strong consistency after a failure.
The fix – Append‑only event sourcing per player
- Event log: Every meaningful action (item pickup, level completion, currency change) is appended as a small record.
- Projection: The current player profile is a materialized view built by replaying events up to the latest offset.
- Rollback: To revert to a prior state, simply re‑project from the desired event index.
- Audit: Each event carries a timestamp, source (client ID, server ID), and optional checksum, making investigations trivial.
Trade‑offs
- Storage: Event logs grow linearly; cheap object stores (e.g., S3, GCS) or time‑series databases handle the volume.
- Complexity: You need a replay engine and occasional compaction (snapshotting every N events) to keep read latency low.
- Operational benefit: Support tickets shrink from hours to minutes because you can restore a player to exactly the point before the bug.
3. One binary handling auth, matchmaking, simulation, persistence, and anti‑cheat
The pattern
A single executable runs the world tick, talks to the database, validates JWTs, performs matchmaking, and runs anti‑cheat scans—all on the same thread pool.
Why it fails at scale
- World simulation – CPU‑bound, needs deterministic frame timing.
- Auth – I/O‑bound, bursty spikes when many users log in.
- Persistence – DB latency can stall the main loop.
- Anti‑cheat – Periodic CPU‑heavy scans.
When any of these subsystems experiences a hiccup, the simulation thread stalls, causing frame drops, desyncs, or mass disconnects. The failure mode is cascading: a slow DB write blocks physics, which in turn blocks auth callbacks, and the whole server appears dead.
The fix – Service decomposition
| Concern | Recommended deployment |
|---|---|
| Auth & token issuance | Stateless microservice behind an API gateway (e.g., FastAPI, Go net/http) |
| Matchmaking | Separate matchmaking service that maintains a queue and hands out server endpoints |
| Persistence | Write‑behind worker pool that consumes events from a message broker (Kafka, NATS) |
| Anti‑cheat | Dedicated scan service that pulls player snapshots from a cache and reports violations |
| World simulation | Lean process that only consumes validated intent events and updates the authoritative state |
By isolating stateless workloads, you can scale each horizontally, apply independent rate limits, and restart a faulty component without taking down the game world. The architecture also aligns with the CAP theorem: the simulation remains consistent (C) while the stateless services can favor availability (A) during spikes.
Real‑world migration
A 150‑player indie survival game hit a “90‑second blackout” when a sudden surge of login attempts saturated the single binary’s auth routine. The team extracted auth into a Go service behind Envoy, added a Redis rate‑limiter, and the blackout vanished. CPU usage on the simulation process dropped from 85 % to a steady 30 %.
The Common Thread: Separate concerns, enforce server authority
All three fixes share a single design principle: different failure domains must not share the same execution path. When you keep the client out of the truth‑making loop and give each subsystem its own lifecycle, you gain predictable latency, easier scaling, and a clear audit trail.
Quick checklist for indie teams
- Validate on the server – never trust client‑generated numbers that affect other players.
- Make player state immutable – store actions as events, not overwriting blobs.
- Split the monolith – run auth, matchmaking, persistence, and anti‑cheat as independent services.
If you’re still below 50 concurrent users, you can defer most of this. The moment you cross the 100‑player threshold, the cost of refactoring spikes dramatically.
Further reading
- Tick‑server vs. event‑driven split: https://gsb.supercraft.host/blog/multiplayer-game-backend-architecture/
- Per‑player event sourcing for save data: https://gsb.supercraft.host/blog/player-data-schema-design-nosql-vs-sql/
- Orchestrating stateless services: https://gsb.supercraft.host/blog/game-server-orchestration-guide/
What failure have you run into?
In my experience, the third category—monolithic servers choking on auth bursts—has become the most common as indie teams push past the 200‑player mark. Splitting services early saves you from a painful rewrite later.
Comments
Please log in or register to join the discussion