
As AI coding agents proliferate, new research reveals programming languages vary dramatically in token efficiency—a hidden factor impacting LLM context limits and computational resources.

The rise of AI-powered coding assistants is forcing developers to reconsider fundamental assumptions about programming languages. Martin Alderson's investigation into token efficiency—how compactly languages represent logic within LLM context windows—reveals unexpected leaders and laggards that could reshape tool selection.
Transformer architectures powering LLMs face severe context limitations. Memory requirements scale quadratically with context length, creating bottlenecks even with today's hardware. When AI agents handle coding tasks, verbose languages consume disproportionate context capacity—potentially requiring more roundtrips, higher costs, and slower iteration. Alderson's analysis suggests token efficiency could become as crucial as runtime performance for AI-augmented workflows.
Using RosettaCode's dataset of 1,000+ tasks implemented across languages, Alderson measured solutions against OpenAI's GPT-4 tokenizer. The study compared 19 mainstream languages using tasks with implementations across all selected languages, excluding TypeScript due to sparse data. While not exhaustive, the methodology provides meaningful comparisons of similar logic implementations.
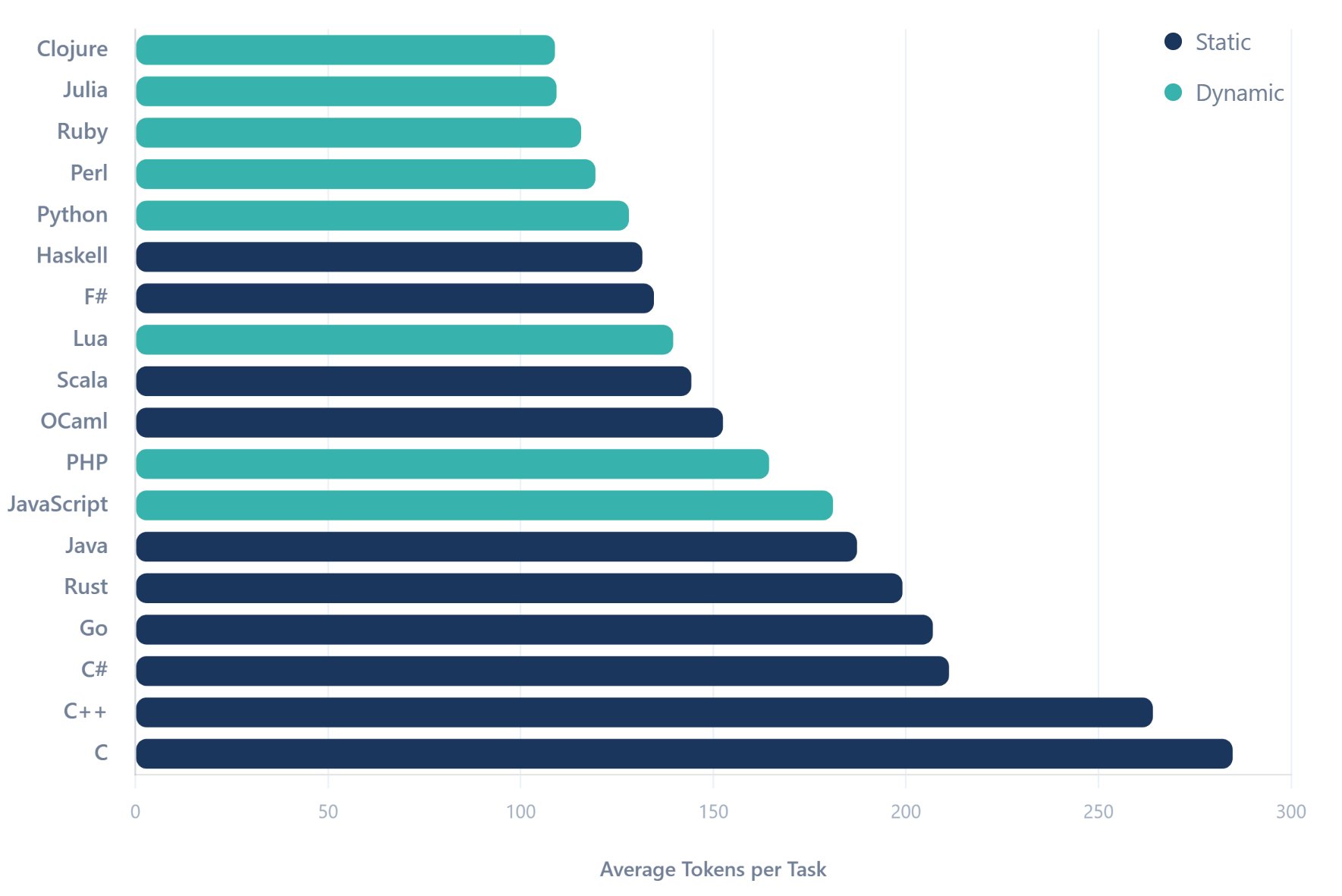
The results revealed stark disparities:
- Dynamic languages averaged 30% fewer tokens than static counterparts, avoiding type declarations (JavaScript proved the least efficient in this group)
- Functional languages like Haskell and F# nearly matched dynamic languages' efficiency due to robust type inference
- C ranked least efficient at 188 tokens per task, while Clojure led at 109 tokens—a 2.6x difference
Follow-up tests uncovered more extreme cases:
- APL's symbolic syntax backfired—unique glyphs (⍳, ⍴) consumed multiple tokens each, placing it fourth at 110 tokens
- J (an ASCII-based array language) dominated at just 70 tokens—40% fewer than Clojure—demonstrating how language design choices directly impact token economy
This efficiency gap carries practical implications. If code occupies 80% of an agent's context window, using Haskell over C# could extend session length by 25-40%. For organizations running thousands of AI coding sessions daily, token-optimized languages might reduce cloud costs substantially. More crucially, concise languages enable agents to retain broader architectural context during complex tasks.
Typed languages offer compensating advantages despite verbosity. Compilation provides immediate error feedback, countering LLM hallucination risks. When paired with LSP tooling, they create a safety net that may outweigh token penalties for certain workflows.
The emergence of token efficiency as a metric reflects computing's paradoxical new reality: despite petabytes of available memory, the economics of transformer architectures make every token count. As Alderson notes, we're entering an era where petaflops of compute coexist with stringent context constraints—forcing reevaluation of what makes a language 'efficient' in AI-native development.
Methodology notes: Analysis used Hugging Face's Xenova/gpt-4 tokenizer. RosettaCode solutions vary in optimization levels, but uniform task requirements enable relative comparisons. Full dataset and code available on GitHub.
Comments
Please log in or register to join the discussion