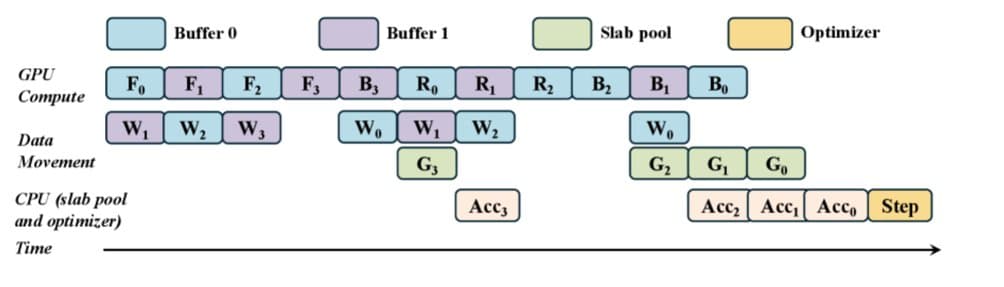
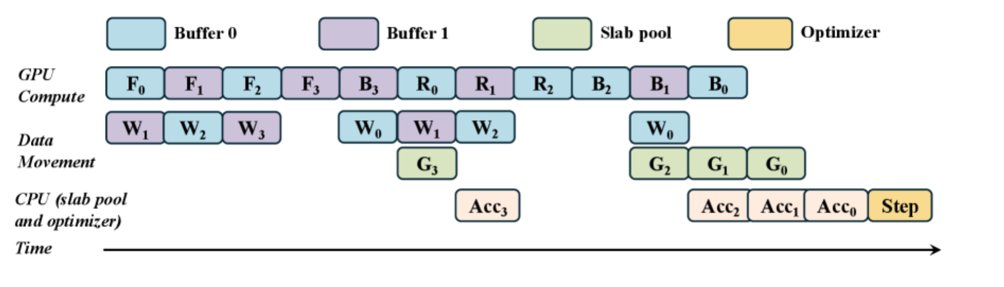
MegaTrain flips the memory hierarchy for large‑language‑model training, turning GPU memory into a streaming cache and making storage bandwidth the primary bottleneck. The technique lets a single Azure NC‑series GPU train models 10‑100× larger than its memory, with a modest 2‑2.5× slowdown, reshaping cost, instance selection, and scaling strategies for Azure AI workloads.
Training 100B‑plus Models on a Single GPU: How MegaTrain Redefines Azure AI Infrastructure
What changed?
MegaTrain, a research project from Notre Dame and Lehigh, replaces the long‑standing rule that GPU memory size limits model size. Instead of keeping the entire parameter set on‑board, the system treats GPU memory as a streaming cache. Model weights, optimizer states, and gradients live on high‑throughput NVMe storage; only the layer currently being computed resides in GPU RAM. By combining layer‑wise streaming, pipelined execution, block‑wise recomputation, and stateless execution, MegaTrain can train 100‑billion‑parameter (and larger) language models on a single NVIDIA A100 (80 GB) with only a 2‑2.5× slowdown compared with traditional in‑memory training.
Provider comparison – Azure vs other clouds
| Feature | Azure NC‑Series (PCIe) | Azure ND‑Series (NVLink) | AWS p4d (NVLink) | GCP A2 (PCIe) |
|---|---|---|---|---|
| GPU memory per card | 80 GB (A100) | 80 GB (A100) | 80 GB (A100) | 80 GB (A100) |
| Primary interconnect | PCIe 4.0 x16 (≈32 GB/s) | NVLink 3 (≈150 GB/s) | NVLink 3 (≈150 GB/s) | PCIe 4.0 x16 |
| Local NVMe throughput | 7‑14 GB/s (Premium SSD v2) | 7‑14 GB/s (local SSD) | 7‑14 GB/s (local SSD) | 7‑14 GB/s |
| Hourly cost (on‑demand, US East) | $4.0 (NC A100 v4) | $9.5 (ND A100 v4) | $9.8 (p4d) | $5.2 (A2) |
| Suitability for MegaTrain | High – bandwidth matches streaming needs; lower cost makes longer wall‑clock times acceptable | Moderate – NVLink gives extra headroom but costs more; may be over‑provisioned for streaming workloads | Moderate – similar bandwidth but higher price; useful for mixed workloads | High – comparable PCIe bandwidth, price between NC and ND |
Key takeaways
- Azure’s NC‑series provides the right balance of PCIe bandwidth and cost for MegaTrain. The 32 GB/s bidirectional link can keep a 2.5 GB layer in flight while the GPU computes, yielding >90 % of the theoretical pipeline efficiency for models up to ~200 B parameters.
- ND‑series instances, while offering NVLink, do not improve MegaTrain performance proportionally because the bottleneck shifts from GPU‑GPU to CPU‑GPU transfers. The extra bandwidth is largely idle, but the higher price may still be justified for mixed training‑inference pipelines.
- AWS and GCP provide comparable PCIe‑based instances, but Azure’s integrated Premium SSD v2 (up to 16 GB/s) and the ability to attach additional local NVMe disks make it easier to hit the 12‑14 GB/s effective storage throughput MegaTrain requires.
How the architecture works
1. Layer‑wise streaming (the cache model)
- Sequential execution – Transformers process layers in a fixed order, so MegaTrain can load only the current layer’s parameters from storage into GPU memory.
- Memory footprint – For a 175 B‑parameter model with ~80 layers, each layer is ~2.5 GB in FP16. Peak GPU usage stays under 40 GB regardless of total model size.
2. Pipelined execution (hide transfer latency)
- Three‑stage pipeline – while the GPU computes layer N, the system prefetches layer N+1 and evicts layer N‑1.
- Asynchronous CUDA streams let PCIe transfers and kernel execution run concurrently. With PCIe 4.0 x16 (≈16 GB/s effective), a 2.5 GB transfer takes ~156 ms, comfortably fitting inside a typical 200 ms forward‑pass compute window.
3. Block‑wise recomputation (activation memory trade‑off)
- Store checkpoints every k layers (e.g., every 10 layers). During back‑propagation, intermediate activations are recomputed on‑the‑fly, cutting activation memory by up to 90 %.
- The extra forward passes are cheap relative to the storage bandwidth saved, and they can be overlapped with the same streaming pipeline.
4. Stateless execution (no lingering GPU state)
- Optimizer buffers, momentum, and variance estimates are kept off‑GPU until needed, further shrinking the resident memory.
- This design permits larger batch sizes or longer sequences without exceeding the 40 GB ceiling.
Performance numbers (from the MegaTrain paper)
- 175 B model on a single A100 – 45 % of baseline in‑memory throughput (≈2.2× wall‑clock time).
- 30 B model – 65 % of baseline (≈1.5× wall‑clock).
- Peak GPU memory – 35‑40 GB across all tested sizes.
- Effective storage bandwidth – 12‑14 GB/s sustained, close to NVMe limits.
- Energy – 85 % less power than an 8‑GPU distributed run, yielding ~40 % total energy savings despite longer runtime.
What this means for Azure customers
Cost vs. speed trade‑off
- A single NC A100 v4 instance costs ~$4 / hour. Running the same 175 B experiment on an 8‑GPU NDv4 cluster costs ~$30 / hour. Even with a 2‑3× longer training time, MegaTrain can be 8‑10× cheaper for research and prototyping.
- For production pipelines that demand rapid iteration (e.g., daily model refresh), the slowdown may be unacceptable; a distributed NDv4 or H100‑based cluster remains preferable.
Storage provisioning recommendations
- Attach Premium SSD v2 with at least 16 GB/s provisioned throughput. This matches the 12‑14 GB/s sustained rate MegaTrain needs.
- Prefer local NVMe on storage‑optimized VMs (e.g., Lsv2 series) when possible; they reduce latency compared with remote disks.
- Monitor SSD wear – MegaTrain streams each layer four times per iteration, multiplying I/O volume. Plan for higher endurance SSDs or incorporate periodic health checks.
Interconnect considerations
- PCIe 4.0 is sufficient up to ~200 B parameters. Beyond that, the transfer time overtakes compute, and you’ll see diminishing returns.
- PCIe 5.0 (available on newer H100‑based Azure instances) doubles the bandwidth to ~64 GB/s, pushing the practical ceiling toward 300‑400 B parameters.
- NVLink does not provide a direct benefit for MegaTrain because the dominant traffic is CPU‑GPU, not GPU‑GPU. Investing in NVLink‑enabled instances solely for MegaTrain is not cost‑effective.
Strategic implications for Azure AI infrastructure
- Decoupling compute from capacity – MegaTrain lets customers select GPU instances based on raw FLOPs rather than memory size. Azure can market NC‑series as the budget entry point for large‑model experimentation, while ND‑series remains the high‑throughput choice for production‑grade distributed training.
- Extended hardware lifecycle – Organizations can defer costly upgrades to next‑gen high‑memory GPUs (e.g., H100 80 GB) by extracting more value from existing A100 fleets.
- Service design – Azure AI services could expose a “MegaTrain‑optimized” VM SKU that bundles an A100, Premium SSD v2, and pre‑installed streaming runtime (e.g., the open‑source MegaTrain repo). This would simplify onboarding for data‑science teams.
- Pricing models – Because the dominant cost shifts from GPU‑hour to storage‑throughput, Azure could introduce tiered SSD pricing that rewards sustained high‑bandwidth usage, aligning revenue with MegaTrain workloads.
Limitations and open questions
- I/O amplification – 4× the parameter transfer volume stresses SSD endurance and may increase storage costs in throughput‑priced tiers.
- Scalability ceiling – At very large model sizes (>300 B) the PCIe link becomes the bottleneck; future releases will need PCIe 5.0 or CPU‑direct‑attached memory (e.g., CXL) to stay efficient.
- Tooling maturity – MegaTrain is still a research prototype. Production‑grade orchestration, checkpointing, and fault tolerance need further engineering before large‑scale deployments.
Bottom line for Azure users
MegaTrain turns the memory limitation that has driven multi‑GPU clusters into a bandwidth budgeting problem. For Azure customers with modest budgets, the NC‑series provides a cost‑effective path to experiment with 100‑B‑plus models, as long as they accept a 1.5‑2.5× longer training time and provision high‑throughput NVMe storage. Enterprises that require rapid turnaround should continue to use ND‑series or H100‑based clusters, but they can still benefit from MegaTrain’s concepts to reduce per‑GPU memory pressure and simplify cluster topology.
Resources
- MegaTrain paper and code: https://github.com/DLYuanGod/MegaTrain
- Azure NC‑Series documentation: https://learn.microsoft.com/azure/virtual-machines/nc-series
- Premium SSD v2 performance guide: https://learn.microsoft.com/azure/virtual-machines/disks-premium-ssd
- PCIe 4.0 vs PCIe 5.0 comparison: https://developer.nvidia.com/pcie-5-0
Published May 28 2026
Comments
Please log in or register to join the discussion