
A veteran developer reconsiders Test-Driven Development after years of skepticism, discovering that coding agents fundamentally change the economic equation of testing. What was impractical for iterative products becomes viable when AI can write thousands of tests in seconds.
I've been a TDD sceptic for most of my career. The economics never made sense - why spend hours writing tests for features that might not survive first contact with users? Then coding agents came along and completely flipped the calculation.
How I used to think about testing
I've worked on a lot of different projects over the years. I was most comfortable heavily leaning into e2e based tests, running against the full application running in Docker. Combined with TestContainers (which is awesome!) it was very easy to spin up a complete copy of your entire infrastructure and run it against each commit.
I tended to combine browser based testing with API testing, where you would run through each use case of the app and run the API requests the client would make in sequence and assert various parts. Depending on the project, there would be some level unit testing for core 'calculations' or 'business logic', with projects with complex financial or business logic requiring more unit tests.
I found this very successful - in my experience so many bugs and errors in software aren't caught by unit tests per sé, especially in complex web or mobile apps. The hard bit about these apps is the very complex interplay between the client, state, backend, caches, message queues, databases and often 3rd party services at various levels of the stack. Unit tests tend to avoid testing this (by definition).

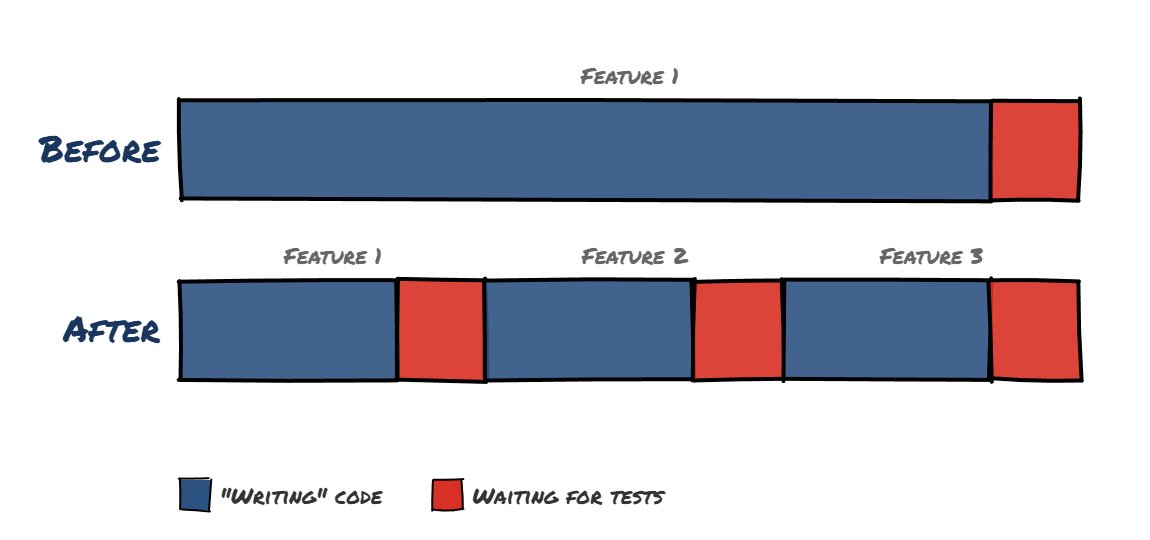
The issue with heavy e2e testing is it is slow. You have to spin up all the related infrastructure, start your application(s), seed data, and then execute the tests. Browser based tests are especially slow, as you now need to run browser(s) to execute the workflows. We'll come back to this later, but LLMs change the calculus on this directly in my experience.
TDD scepticism
I definitely used to think of myself as a TDD sceptic. While I've always seen the promise of it, in my experience it often led to codebases that were optimised to be easy to test, but not focussed on product outcomes. To be clear, for some codebases this is the correct outcome. If you're building highly critical software which has a highly defined use case (that doesn't change much), then optimising for this is the right call. Stability/reliability actually is the most important product outcome.
I've been involved with some codebases that had definitely drank the TDD kool-aid too much. It was clear there was pushback on product changes based on how difficult it was to update the codebases tests. If you've done TDD and your product definition changes dramatically, it can result in an awful lot of tests going in the bin and a lot of new ones having to be written. Often this is for seemingly (product facing) trivial things that change a lot of assumptions about the data model of the product at hand.
I'm sure there will be many that argue that actually this is the whole point - TDD makes you really think hard about how you are going to build reliable, testable software upfront and avoid the technical debt of it later down the line. The issue though is that this often led to a culture of treating the tests as more important than user requirements, which often ended up with so much time being spent writing tests for features that didn't get user traction and were deleted anyway[1].
Enter LLMs
So now we've established how I used to think about testing. Coding agents have totally changed the ballgame on this. I mentioned e2e testing was slow before - and this is true, but if you're doing things at "human speed" you're probably spending most of your time writing code, and much less waiting for tests to pass (though it does get frustrating when you are stuck in a slow fix test -> wait for tests to pass -> fail -> try again cycle that I'm sure many are all too familiar with on certain projects).
When you're shipping features faster with agents, waiting for tests becomes a much larger proportion of your time. I quickly noticed that when I was working with Claude Code, I seemed to be spending nearly all my time waiting for e2e test cases to pass. And worse, the output of these tests (especially browser based) are difficult for LLMs to reason about - LLMs still don't work brilliantly with screenshots, and the test output can be enormous.
This resulted in often comically bad results where it'd read the test failure screenshots, decide it was working brilliantly (when it clearly wasn't!) and then get confused why it was still failing and generally reasoning itself into the nearest psychiatric ward. Even worse, I was noticing that small regressions were starting to creep in even when the tests did pass. Subtle behaviour and data bugs were starting to mount up, which required me to keep a very close eye on all the changes the agent was building and interrupting it all the time.
This was almost certainly confounded with the models being dramatically worse back then, but I was seemingly spending all my time staring at either Claude Code output or test log output.
Where I'm at now
After much trial and error I feel I've got into a far better place with this. I'm not sure if you'd call it TDD - but for each 'ticket' I give an agent, I ask it to come up with a testing plan before implementing[2]. I don't necessarily require it to write the tests first then get them passing, but the idea is me and the agent debate on the best testing approach for a feature ahead of time.
I've leaned far heavier into unit testing and integration testing (on mostly "mocked" infrastructure, vs the e2e approach I discussed before) as well. While I still have a bunch of e2e tests that run on PR, I instruct the agent to just ensure unit and integration tests are passing, and then make a PR which CI will then run e2e against. This seems to strike the right balance - the agent can run the fast tests locally, and then at PR review any failing e2e tests are flagged before merge (which I can then tell the agent to fix).
The agent can write all these unit and integration tests in seconds, and it really doesn't matter if the feature flops and needs to be deleted.
The other interesting approach I've done when I do come across a bug is while working on the bug ticket, get the agent to explain why this was missed in our test suite while fixing it. Then add test case(s) specifically for this edge case, covering the reasons outlined before[3]. This is obviously just best practice - not some new breakthrough! But in highly iterative products there often just wasn't enough time or resources to add detailed test cases for every single edge case that came up - you'd have to do some level of triage to decide what was worth writing good test cases for.
LLMs clearly change the economics of this, and now even quite simple hobby projects I've made with agents end up with 1,000+ test cases - some of them quite basic, but a lot really running through real use and edge cases. I now somewhat shudder looking back at quite how fragile some of the human written projects were, test coverage wise.
The hidden benefits
The side effect of this is you end up codifying so much behaviour of the app in the tests. The agent has to understand these subtle edge cases, because the tests won't pass otherwise. And as the models and agent harnesses continue to get better and better they figure the inferred meaning of the failing tests far better.
The other surprising benefit is reviewing LLM PRs gets a lot easier. Reviewing the code from an LLM is a lot easier when you know all the tests are passing. Now what I do is start by reviewing the new or updated test files - not the actual implementation code. This has two benefits. Firstly, if me and the agent did a good job of defining the tests and these pass, I can be pretty confident the code at least does what it should do - and I can focus review time on other things. Secondly, I can quickly see if the LLM has "cheated" by simplifying/removing the tests. It's a clear giveaway if some test file has suddenly had a few tests removed that probably some weird edge case has come along, and the agent has decided to be lazy and remove it instead. This doesn't happen very often, with some careful instructions in AGENTS.md to tell it not to do this, but it's still another good sanity check.
Everything I read about TDD and testing was correct and I was wrong
However, it required basically infinite close-to-free "labour" in the form of agents for me to get the economics right for most projects. The results I've got from this approach are genuinely impressive to me. I've built some really complex pipelines that I keep thinking are going to break every time I do a change with an agent, but don't. Maybe I'm just kicking the can further and further down the line, but I haven't hit the 'ceiling' yet.
Turns out the TDD folks were right all along. They just needed a mass-produced army of robotic junior devs to make it practical.
[1] This is particularly problematic in early-stage startups where product-market fit is still being figured out. Writing comprehensive tests for features that might be pivoted away from within weeks is genuinely wasteful.
[2] I typically use a structured prompt like: "Before implementing this feature, let's plan our testing strategy. What are the main user flows? What edge cases might break this? Should we test at the unit, integration, or e2e level? What mocking strategy makes sense?"
[3] This has become my standard bug-fix workflow: 1) Reproduce the bug, 2) Have the agent write a failing test that captures the bug, 3) Fix the bug so the test passes, 4) Review the test to ensure it's actually testing the right thing. This creates a regression test that will catch this specific issue forever.
Comments
Please log in or register to join the discussion