Uber has rearchitected its data lake ingestion platform, replacing scheduled batch jobs with a streaming-first system that reduces latency from hours to minutes while cutting compute usage by 25%.
Uber engineers have rearchitected the company's data lake ingestion platform, moving from scheduled batch jobs to a streaming-first system. The platform, IngestionNext, processes event streams continuously, reducing ingestion latency from hours to minutes and enabling faster availability for analytics and machine learning workloads.
Previously, ingestion pipelines relied on Apache Spark and ran as scheduled batch jobs. While capable of large-scale processing, batch pipelines delayed data availability for analytics and experiments. As noted by Kai Waehner, Global Field CTO in a LinkedIn post: This move is all about treating data freshness as a key dimension of data quality.
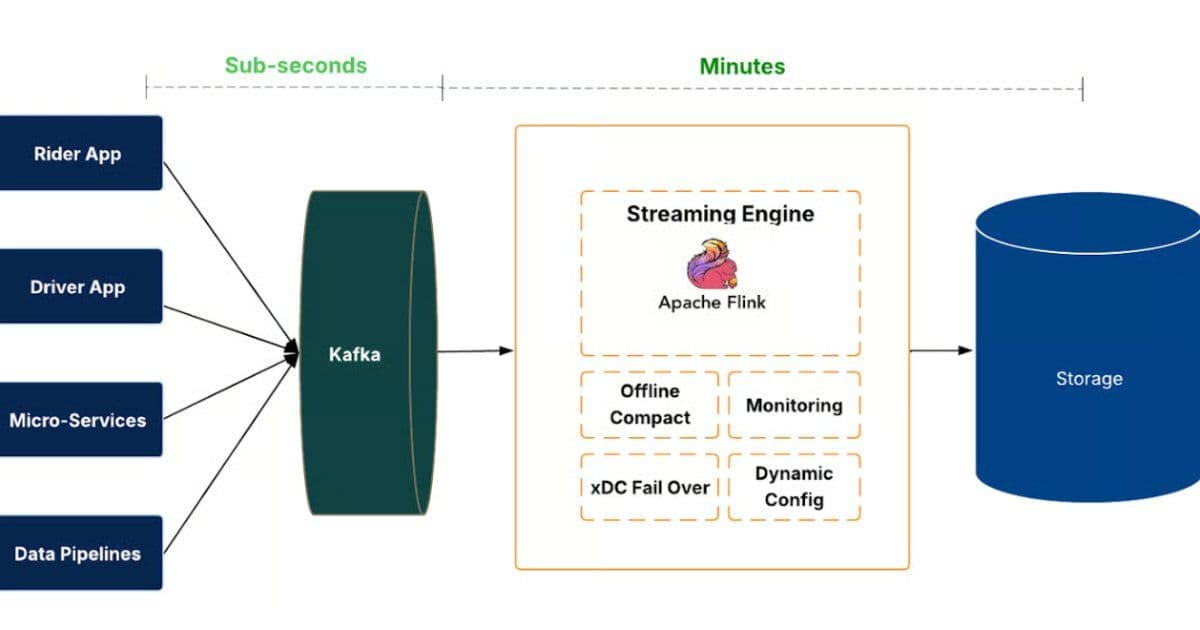
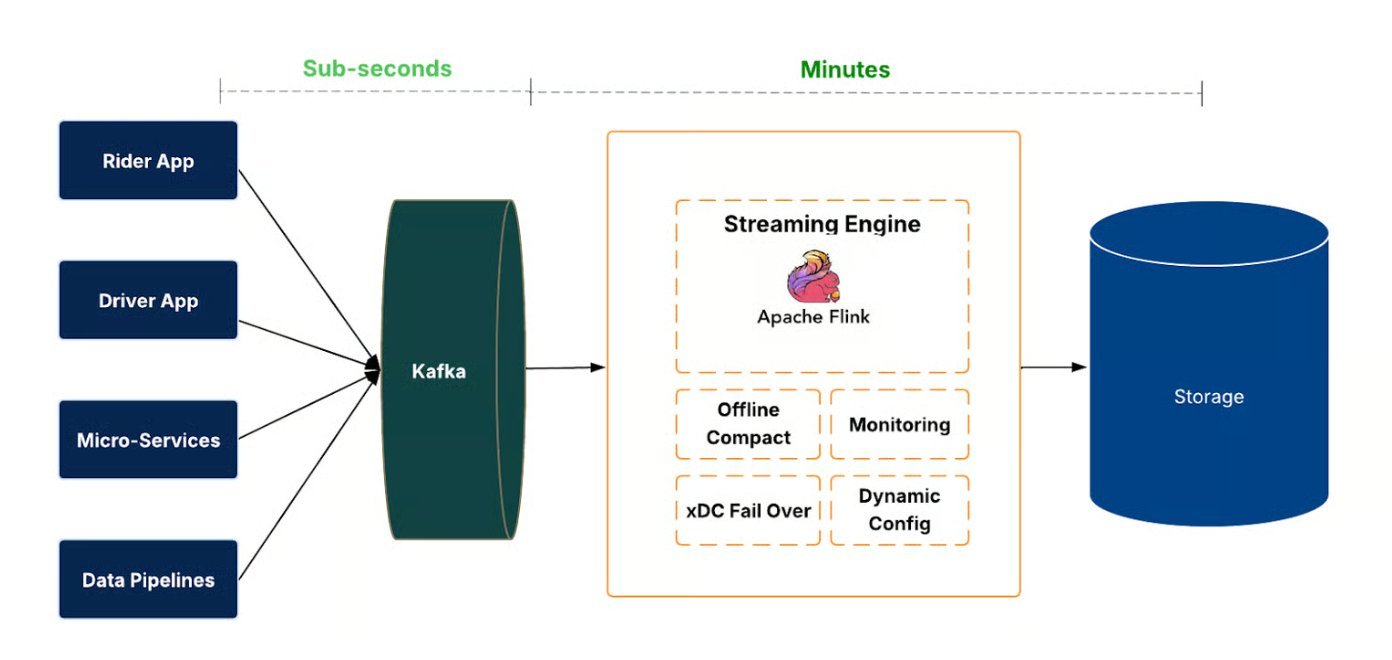
IngestionNext introduces a streaming-first pipeline that continuously processes event streams before committing them to the data lake. Events flow through Apache Kafka and are processed by Flink jobs, which write to Hudi tables with transactional commits, rollbacks, and time travel. Freshness and completeness are measured end-to-end. The architecture supports thousands of datasets and high global data volumes, enabling faster availability for analytics dashboards, experimentation platforms, and machine learning models.
A control plane automates job life cycle, configuration, and health monitoring, while regional failover and fallback strategies maintain continuity and prevent data loss during outages.
Moving to a streaming ingestion model introduced several technical challenges. One challenge was creating many small files in the data lake, which can degrade query performance and storage efficiency. To address this issue, the engineers implemented row-group-level merging strategies for Parquet files and added compaction mechanisms to maintain efficient file layouts during continuous data ingestion. Open-source efforts, including Apache Hudi, explored schema-evolution-aware merging using padding and masking to align differing schemas, though this adds implementation complexity and maintenance overhead.
The team also implemented mechanisms to handle checkpointing, partition skew, and recovery in distributed streaming pipelines. The system tracks offsets from upstream streams and coordinates commits to ensure that ingestion jobs maintain data correctness and can recover reliably in the event of failures.
According to the engineers, the transition to streaming ingestion also improved resource efficiency. By replacing scheduled batch workloads with continuously running streaming jobs that scale with incoming data volume, the system reduced compute usage by roughly 25%. Suqiang Song, who co-authored the Uber Engineering blog, mentioned in his LinkedIn Post: This enabled a fully end-to-end real-time data stack, from ingestion to transformation to analytics.
While the new ingestion platform improves the freshness of raw data entering the data lake, engineers acknowledged that downstream transformations and analytics pipelines may still introduce additional latency. Future work will focus on extending streaming capabilities into the data processing stack to ensure freshness improvements propagate across the entire analytics workflow.
The IngestionNext platform represents a significant architectural shift for Uber's data infrastructure. By treating data freshness as a first-class concern and building a streaming-first ingestion pipeline, Uber has achieved substantial improvements in both latency and resource efficiency. The system processes thousands of datasets continuously, enabling analytics and machine learning workloads to operate on fresher data while reducing the computational overhead of scheduled batch jobs.
The technical implementation leverages well-established open-source technologies including Apache Kafka for event streaming, Apache Flink for stream processing, and Apache Hudi for managing the data lake with transactional capabilities. The platform's ability to handle schema evolution, maintain data consistency through checkpointing, and provide regional failover demonstrates the engineering maturity required for production-scale streaming systems.
For organizations considering similar transitions from batch to streaming architectures, IngestionNext provides a concrete example of the benefits and challenges involved. The 25% reduction in compute usage demonstrates that streaming architectures can be more efficient than batch processing, while the file management strategies show how to address the common problem of small file proliferation in streaming systems. The platform's success suggests that streaming-first approaches may become increasingly viable for organizations seeking to reduce data latency and improve resource utilization in their data infrastructure.
Comments
Please log in or register to join the discussion