A deep dive into historical cases of scientific progress shows that verification loops can span decades or centuries, making it hard for reinforcement‑learning systems to evaluate and prioritize transformative theories. The article argues that AI’s strength in tightly‑looped domains does not automatically translate to breakthroughs in fields where evidence is sparse, experiments are ambiguous, and progress relies on long‑term heuristics.
Why AI May Struggle More Than Expected with Scientific Breakthroughs
In a recent conversation with Michael Nielsen, the question that kept resurfacing was how we recognize scientific progress. The answer is far from a clean, algorithmic rulebook, and that fact has serious implications for any attempt to close the reinforcement‑learning (RL) loop on scientific discovery.
The claim: AI will be disproportionately good at science
Proponents often point to two observations:
- Science is verifiable – hypotheses can, in principle, be tested against data.
- AI excels where verification loops are tight – tasks like theorem proving, code generation, or game playing provide rapid feedback, allowing RL agents to iterate quickly.
From these premises they extrapolate that AI will soon outpace humans in generating and confirming new scientific theories.
What history actually tells us
Long‑term verification loops
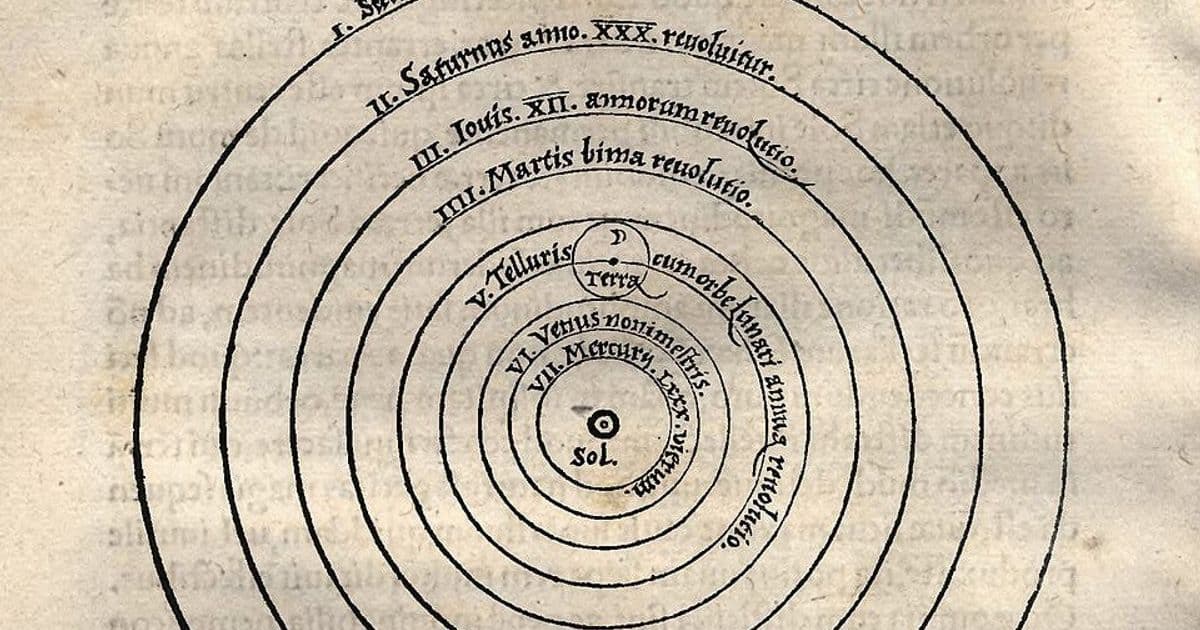
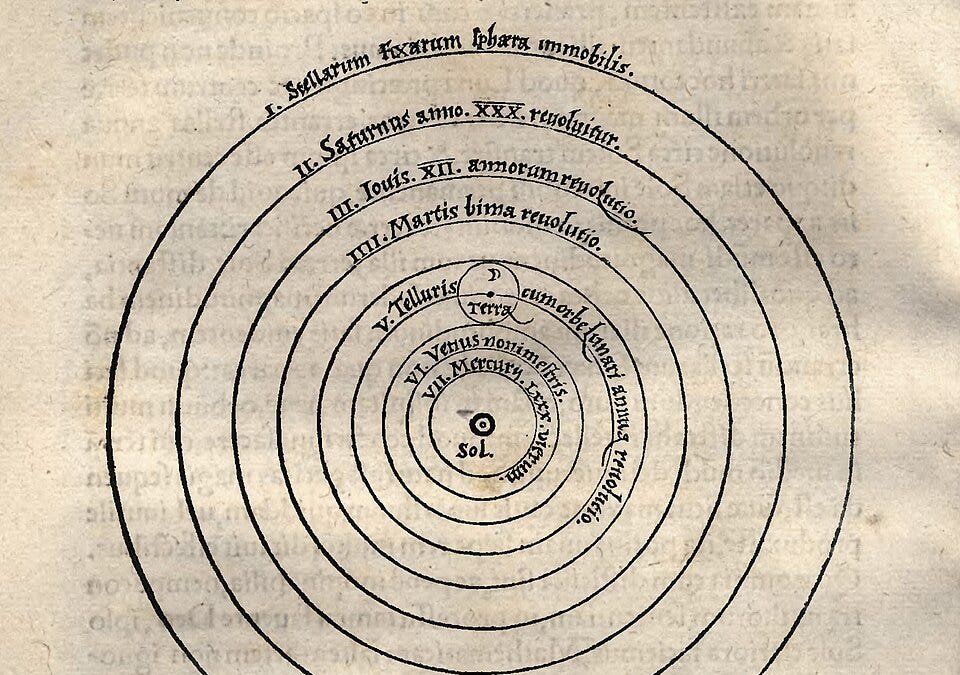
The heliocentric model is a textbook example. Aristarchus proposed a Sun‑centered system in the 2nd century BC, but the lack of observable stellar parallax led the ancient community to dismiss it. It took over two millennia—until Bessel measured parallax in 1838—before the model could be empirically confirmed.
Better predictions do not guarantee a better theory
Copernicus’s 1543 model used circular orbits and required many epicycles to match observations, making it less accurate than Ptolemy’s refined geocentric system that had accumulated centuries of epicyclic corrections. Only after Kepler introduced elliptical orbits (1619) and Newton linked orbital motion to universal gravitation (1687) did the heliocentric view become both simpler and more predictive.
The “Neptune vs. Vulcan” saga
- Neptune (1846): Anomalies in Uranus’s orbit led Le Verrier to predict a new planet. The prediction was spot‑on, a triumph for Newtonian mechanics.
- Vulcan (late 19th c.): Mercury’s perihelion precession suggested another unseen planet. Decades of telescopic searches failed, and the anomaly was finally explained by Einstein’s General Relativity (1915).
Both cases illustrate that intermediate hypotheses—new planets, dust clouds, magnetic fields—can be scientifically productive even if the ultimate theory turns out to be wrong.
Prout’s atomic‑weight hypothesis
In 1815 William Prout suggested that all atomic weights are whole numbers. Measurements soon revealed fractional values (e.g., chlorine ≈ 35.5). The community wrestled with impurity explanations, isotope hypotheses, and measurement error for nearly a century before the concept of isotopes resolved the puzzle.
Darwinism’s slow validation
Charles Darwin’s Origin of Species (1859) presented a conceptually simple mechanism—natural selection—but lacked decisive experiments. Acceptance hinged on geology (Lyell’s deep time), paleontology, biogeography, and artificial selection studies, each accumulating over decades. The theory’s eventual triumph was more a matter of convergent evidence than a single falsifiable test.
Why these patterns matter for AI‑driven science
- Verification is not instantaneous – Many scientific claims only become testable after new instruments, methods, or complementary theories emerge. An RL agent receiving a binary reward signal today would receive no feedback for decades.
- Progress is judged by future productivity – A hypothesis that looks unpromising now may later enable a cascade of discoveries (e.g., the ether hypothesis gave way to relativity). RL rewards based on short‑term metrics would discard such ideas prematurely.
- Heuristics and judgment play a central role – Human scientists use aesthetic criteria (simplicity, explanatory power), community consensus, and even personal bias to allocate effort. Encoding these nuanced heuristics into a reward function is an open research problem.
- Multiple competing research programs must coexist – History shows that parallel, sometimes contradictory, lines of inquiry are essential. An AI system that aggressively prunes “unpromising” avenues could reduce the diversity that historically led to breakthroughs.
Practical implications
| Aspect | Human practice | Expected AI approach | Gap |
|---|---|---|---|
| Feedback frequency | Decades‑long experimental cycles | Fast‑loop RL (seconds‑minutes) | Misaligned timescales |
| Evaluation metric | Long‑term explanatory power, unification | Immediate prediction accuracy | Reward design challenge |
| Resource allocation | Funding agencies support a portfolio of speculative projects | Bandit algorithms favor high‑reward arms | Risk of over‑exploitation |
| Bias handling | Individual scientists champion niche ideas (e.g., Einstein’s rejection of ether) | Model ensembles may average out outliers | Loss of radical hypotheses |
To bridge these gaps, researchers propose meta‑learning frameworks that learn when to trust short‑term signals and when to keep a hypothesis alive despite poor immediate performance. Another line of work suggests human‑in‑the‑loop RL, where expert scientists provide periodic qualitative feedback, effectively extending the reward horizon.
Bottom line
AI’s success in domains with tight verification loops does not guarantee a proportional advantage in scientific discovery, where verification can span generations and where progress often hinges on subtle, long‑term heuristics. Building systems that can maintain speculative research programs, interpret ambiguous evidence, and learn from sparse, delayed rewards remains a formidable challenge.
The takeaway for practitioners is clear: invest in hybrid approaches that combine the speed of RL with the strategic patience of human scientific judgment, and be wary of any narrative that promises AI will rapidly replace the messy, decades‑long process of genuine conceptual breakthroughs.
For the full interview with Michael Nielsen and a deeper dive into these historical case studies, visit the Dwarkesh Podcast.
Comments
Please log in or register to join the discussion