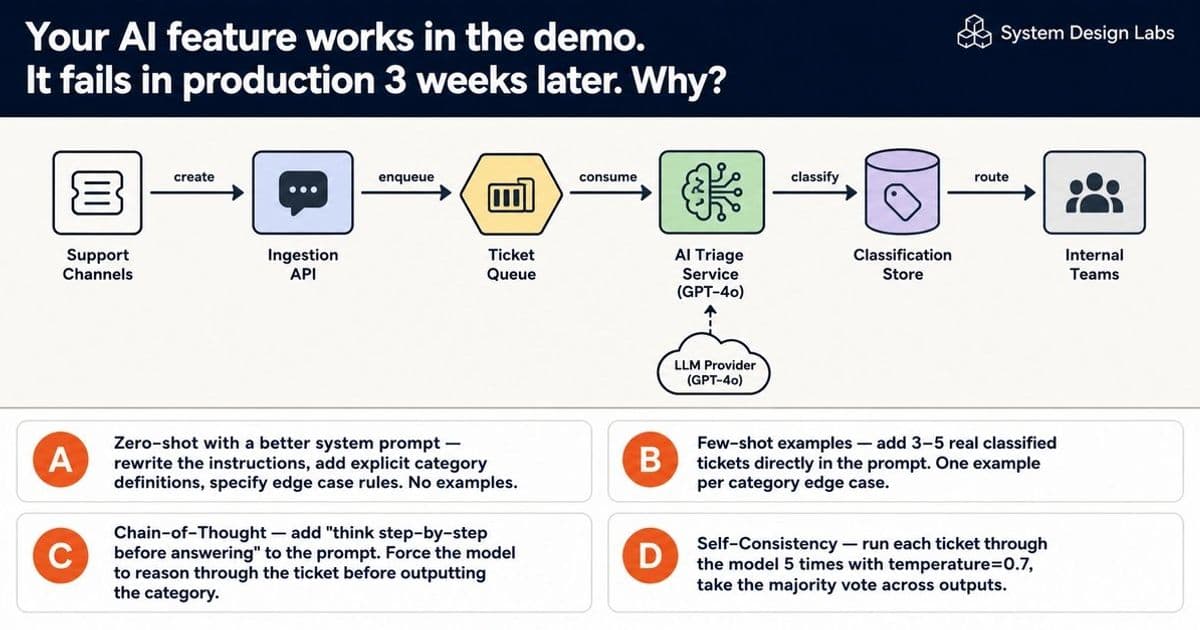
An AI ticket triage system hits 71% accuracy in dev and needs 90% in production with a locked model and a real budget. The four prompting strategies that could close that gap each carry a different cost and accuracy profile, and the right pick depends less on the math than on what being wrong actually costs you.
Your AI feature works in the demo. Three weeks into production it starts missing. Nobody touched the model. Nobody changed the code. The only thing that shifted is the input distribution: the tickets got messier, and the clean examples you tested against stopped representing what users actually send. This is one of the most common failure modes in production machine learning, and it has nothing to do with the model weights.
The problem
The setup is concrete enough to reason about. A SaaS company processes 50,000 support tickets a week. The team builds an AI triage system where GPT-4o classifies each ticket into six categories: billing, bug, feature request, account access, security, and other. Get the classification right and the ticket lands on the correct team's queue instantly, which is the whole point. Get it wrong and a human has to reroute it.
In development the system hits 71% accuracy. To eliminate manual review the team needs 90% or better. The model is fixed, GPT-4o, no fine-tuning on the table. The inference budget is finite. The task is to close a 19-point accuracy gap by changing how the model is prompted, not what the model is.
This is a useful problem precisely because the constraints are realistic. You cannot retrain. You cannot spend without limit. You have to reason about the trade-offs between accuracy, cost, and latency the way you would for any production system, and the answer that looks best on an accuracy chart is not the answer you ship.
The four options
Four prompting strategies are on the table, each a well-known technique with a distinct cost profile.
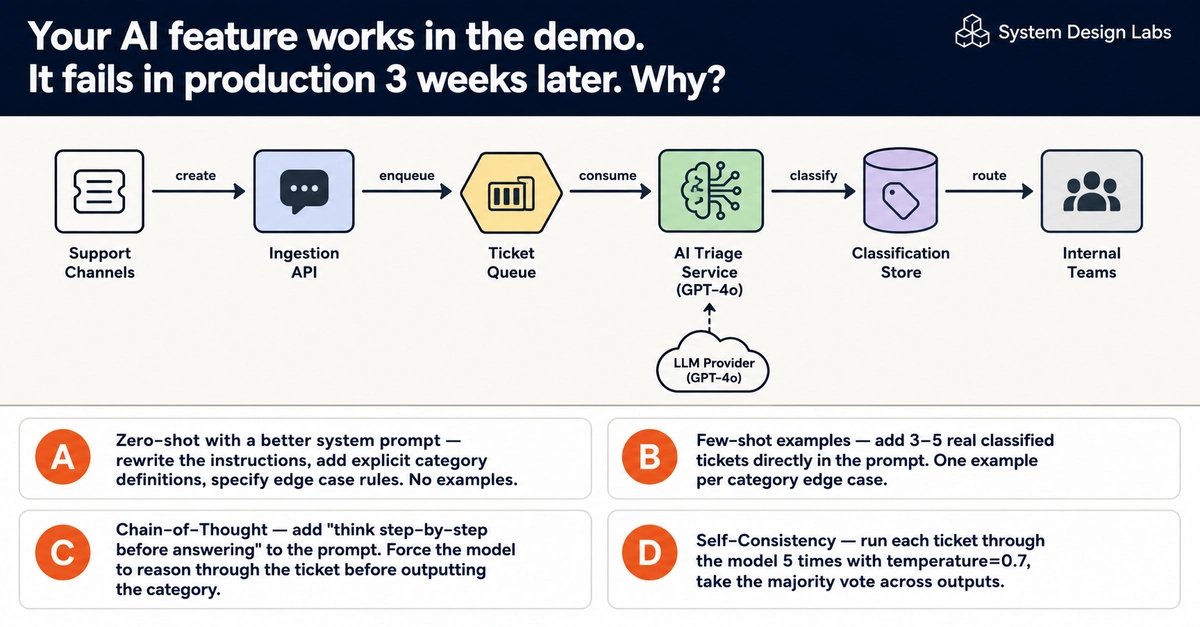
Zero-shot with a better system prompt. Rewrite the instructions. Add explicit category definitions. Enumerate edge case rules. No examples, just better description.
Few-shot. Embed three to five real classified tickets directly in the prompt, ideally one per tricky category boundary.
Chain-of-Thought. Add an instruction to reason step by step before committing to a label, forcing the model to work through the ticket before it outputs a category.
Self-Consistency. Run each ticket through the model five times at temperature 0.7 and take the majority vote across the five outputs.
Same model, same tickets, four very different behaviors. Walking through each one in order of how teams usually reach for them is the fastest way to see why the obvious choice is wrong.
Zero-shot hits a ceiling, and it is a real ceiling
Every team starts here because it feels like progress. You iterate the system prompt, sharpen the category definitions, list out edge cases, and accuracy climbs for a while. The realistic ceiling for this task is roughly 78 to 82%. That is short of 90, and the reason it falls short is structural, not a matter of trying harder.
Instructions describe categories. They cannot show the model where ambiguous cases actually land. Define billing as "anything about charges or invoices," then feed the model this ticket: "I can't log in and I was charged twice last month." Billing or account access? Both signals are present. No amount of prose tells the model which bucket wins, because the answer is not derivable from the definition. It is a judgment call that your team makes implicitly and the model has never seen made. On edge cases like this, zero-shot guesses wrong 20 to 25% of the time, and a real support dataset is mostly edge cases.
Chain-of-Thought is the most misapplied technique in production AI
CoT has become a reflex. Teams append "think step by step" to every prompt and assume it can only help. For classification it roughly breaks even, a delta of plus or minus 2%, and it adds 200 to 400 milliseconds of latency per call for the privilege.
The failure is subtle and worth understanding. The model generates a reasoning chain and then commits to a label that follows from the chain. On an ambiguous ticket the chain becomes a liability: "Mentions a charge, but also a login issue, the charge is mentioned first, so probably billing." It picks billing. The right answer was account access. The reasoning manufactured a justification for the wrong bucket.
Chain-of-Thought helps when the answer genuinely emerges from a sequence of steps, math, debugging, multi-step planning. Classification is different. The answer emerges from calibration, from having an internalized sense of where fuzzy cases belong. Reasoning does not substitute for calibration, and sometimes it actively talks the model out of the right call. CoT is a layer you add on top of a calibrated approach when you are still missing specific edge cases, not the first thing you reach for.

Self-Consistency has the best numbers and the worst economics
On pure accuracy, Self-Consistency wins: 93 to 96%. The mechanism is sound. Each run at temperature 0.7 samples a slightly different reasoning path, and majority voting cancels the noise. If you only looked at the accuracy column you would ship it.
Then you do the cost arithmetic. 50,000 tickets a week times roughly $0.002 a call times 5 runs is about $500 a week. Few-shot does the same job for about $100 a week. You are paying $400 a week extra, plus 5x latency, to buy a 3 to 5 point gain that lands mostly on the hardest cases.
Whether that is worth it depends entirely on the cost of being wrong, and this is the part that separates a systems decision from a benchmark decision. In fraud detection, a missed flag costs hundreds of dollars, so 5x inference to claw back a few points is trivially justified. In medical triage, a misclassification can cause real harm, and you spend whatever it takes. For support routing, a misclassified ticket costs about ten cents of human rerouting time. Spending $400 a week to save a few dollars of rerouting is a bad trade. The math being good is not the same as the decision being good.
Few-shot is the answer, and example selection is the whole game
Few-shot lands at 88 to 93% accuracy with near-zero cost increase, a handful of extra tokens in the prompt. It shifts the model from interpreting rules to pattern-matching against concrete examples, which is a fundamentally stronger signal for this kind of task. That range crosses the 90% threshold, which is the actual requirement.
The part most teams get wrong is which examples they include. The instinct is to pick clean, representative tickets: a textbook billing inquiry, a model bug report. Those teach the model nothing it did not already classify correctly. The examples that move accuracy are the ambiguous ones, the ticket that reads like billing but is actually account access, the feature request phrased like a bug. Those are exactly where the model fails today, and showing it the resolved version of its own failure mode is what closes the gap. Get example selection right and you recover most of the 19 points without touching the model, the budget, or the latency.
There is a deeper principle here that generalizes well past this one problem. When a system fails on the messy tail of its input distribution, the fix is rarely more compute thrown at the same approach. Self-Consistency is more compute. The fix is better signal about where the boundaries actually are, and a few well-chosen examples carry more of that signal than either more elaborate instructions or five votes on the same uncertainty.
The decision framework underneath
Strip away the specifics and the ranking is a cost-of-error calculation. Start with the cheapest technique that could plausibly clear the bar, which is few-shot, and verify it against your hardest cases rather than your cleanest ones. Reserve expensive approaches like Self-Consistency for domains where a single wrong answer is genuinely costly. Treat Chain-of-Thought as a targeted patch for residual edge cases, not a default. And recognize that an accuracy benchmark measured in a clean dev environment is a lower bound on the problem, because production inputs drift toward the ambiguous tail over time. The gap that opened three weeks after launch was never a model problem. It was the input distribution doing what input distributions do.
For anyone building these systems, the data layer matters as much as the prompt. Storing labeled tickets, tracking which examples improve accuracy, and versioning your few-shot sets are all data infrastructure problems, and platforms like MongoDB Atlas handle the multi-region storage and retrieval that production AI pipelines lean on.

Pick few-shot, choose the ambiguous examples, and keep the expensive techniques in reserve for the problems that actually warrant them.
Comments
Please log in or register to join the discussion