A Best Paper at FPGA 2026 and a follow-up at ICML show that Kolmogorov-Arnold Networks map cleanly onto the lookup tables inside FPGAs, delivering nanosecond inference and, for the first time, gradient-based learning that finishes a full forward and backward pass in under a microsecond.
Most machine learning runs on GPUs, and for good reason. They chew through large batches of simple operations with enormous throughput, which is exactly what training and serving big models demands. But there is a class of problems where GPUs simply cannot compete: workloads that need an answer in nanoseconds, with tight power and area budgets. Quantum control loops, nuclear fusion experiments, and high-energy physics triggers fall into this category. The scheduling, dynamic memory access, and instruction overhead baked into any general-purpose processor blow past the latency budget before the math even starts.
That gap is where a recent body of work from Duc Hoang, Aarush Gupta, and Philip Harris lands. Two papers, one a Best Paper winner at FPGA 2026 and the other accepted to ICML 2026, make the case that Kolmogorov-Arnold Networks are an unusually good fit for field-programmable gate arrays, both for ultrafast inference and, more surprisingly, for training the model directly on the chip in real time.
The problem they are solving
An FPGA is a reconfigurable slab of digital logic. Its primary building block is the lookup table, or LUT, a small component that stores the output for every possible combination of binary inputs. Stack enough of these together with flip-flops for state and you can wire up an arbitrary custom circuit. The appeal for machine learning is direct: instead of running a network as a sequence of instructions on a processor, you implement the network as the circuit. There is no instruction fetch, no scheduler, no cache miss. Data flows through silicon that was laid out specifically to compute your model.
The natural idea is to learn the lookup tables themselves as the core primitive of a network, a so-called LUT-NN. The catch is that LUTs represent binary functions, and binary functions are awkward to train with gradient descent. The standard workaround is to learn a continuous, real-valued function in software and then quantize it into a lookup table afterward. Using fixed-point quantization, where real numbers are encoded as base-2 bitstrings with a set number of fractional bits, a continuous function with b-bit inputs and outputs collapses neatly into a binary function that a LUT can store.
That conversion works fine for a single-variable function. It falls apart for multivariate ones. A function of d inputs needs a table whose size grows exponentially with d, since you have to store an entry for every combination of input bits. For anything beyond a couple of inputs, the table becomes impossibly large. So the real engineering question is how to build expressive networks out of small, trainable lookup tables without ever hitting that exponential wall.
Why KANs fit the hardware
Kolmogorov-Arnold Networks answer that question almost by accident. Where a standard multi-layer perceptron multiplies inputs by scalar weights and then applies a fixed activation function, a KAN puts a learnable univariate function on every edge and reduces each node to a plain sum. The output is a sum of one-variable functions, each applied to a single input.
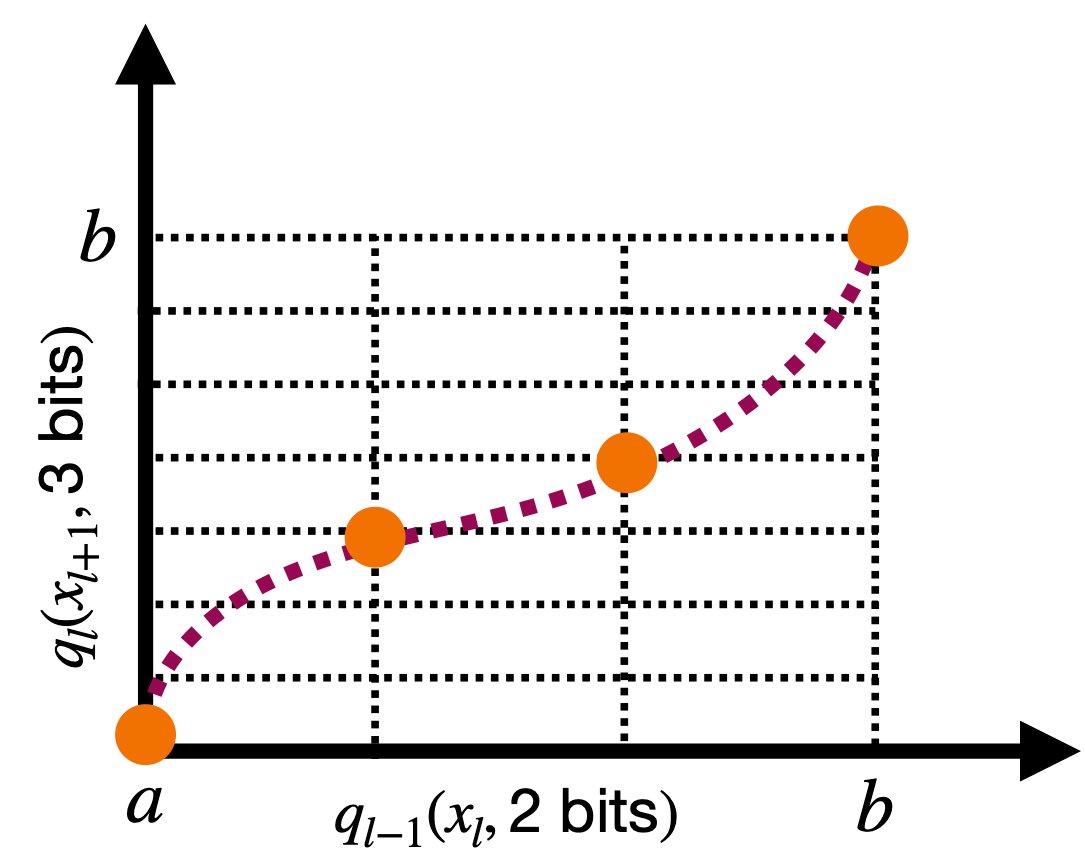
This structure is exactly what LUT-based hardware wants. Every edge activation is a function of one variable, so each one becomes a small, well-behaved lookup table. The node operation is just an adder tree. Nothing scales exponentially, because the network never asks a single table to handle multiple inputs at once. Pruning becomes trivial too: an activation that stays close to zero can be dropped from the sum, saving one LUT and one adder, with no equivalent move available in schemes built on multivariate tables.
The activations are learned by writing them as linear combinations of basis functions, and the original KAN formulation uses B-splines. Those splines are smooth, defined over a small finite domain like [-1, 1], and crucially local, meaning only a handful of them are nonzero for any given input. Because each activation lives on a bounded domain, quantization can cover the entire input range cleanly rather than wasting precision on values that never occur.
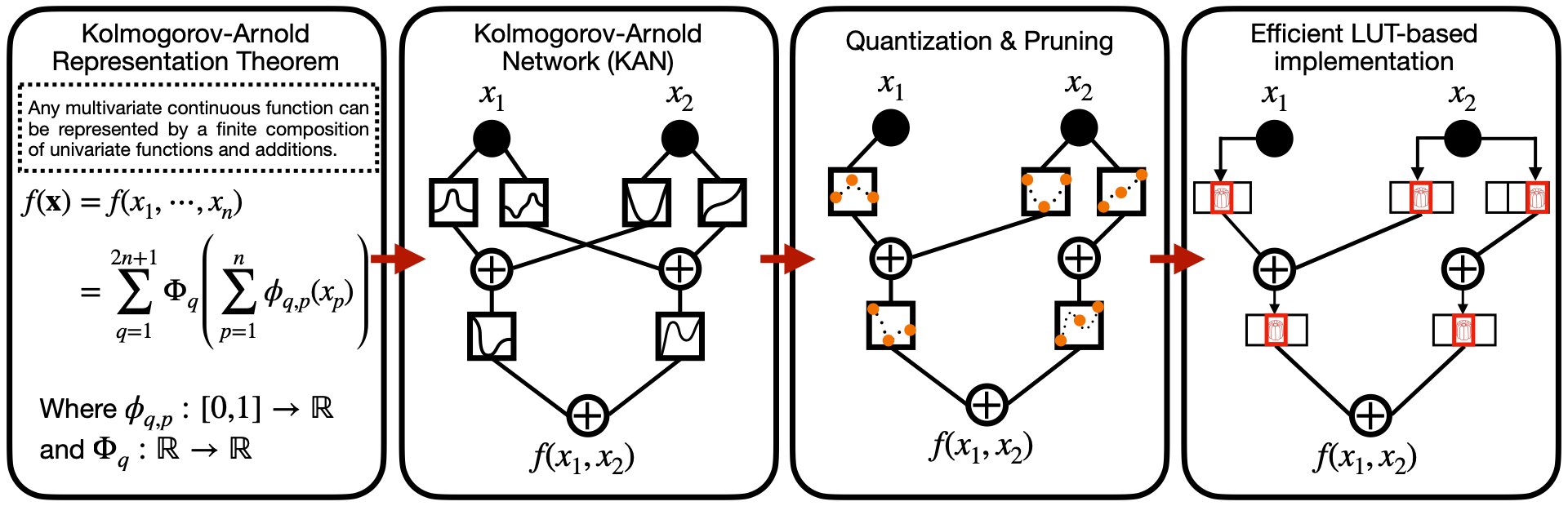
For inference, the recipe is to train the KAN in PyTorch on a GPU, freeze it, and bake each finished activation into its own LUT. The activations run in parallel, an adder tree sums them, and layers chain together by feeding one layer's outputs into the next layer's inputs. The reported result is a framework that matches or beats state-of-the-art neural network FPGA accelerators on latency and resource usage, with a 2700x speedup over prior KAN-on-FPGA implementations. That last number is the headline, but the more interesting contribution comes in the second paper.
Training on the chip itself
Fast inference on a frozen model is useful, but many real-time systems are not static. The thing being modeled, a qubit, a plasma, a control target, can shift its behavior at high frequency. A model that was correct a microsecond ago may already be stale. The conventional fix, shipping data back to a CPU or GPU to compute a gradient update, is a non-starter here, because the round trip alone exceeds a microsecond before any computation happens.
So the second paper moves the entire training loop onto the FPGA: forward pass, backward pass, and gradient update all run as dedicated parallel circuitry that writes new coefficients directly into on-chip memory. On-FPGA gradient descent has long been treated as impractical, and making it work required exploiting two specific properties of B-splines.
The first is locality. The input range is split into G grid cells, and for splines of order S, only S+1 basis functions are active over any single interval, no matter how large G gets.
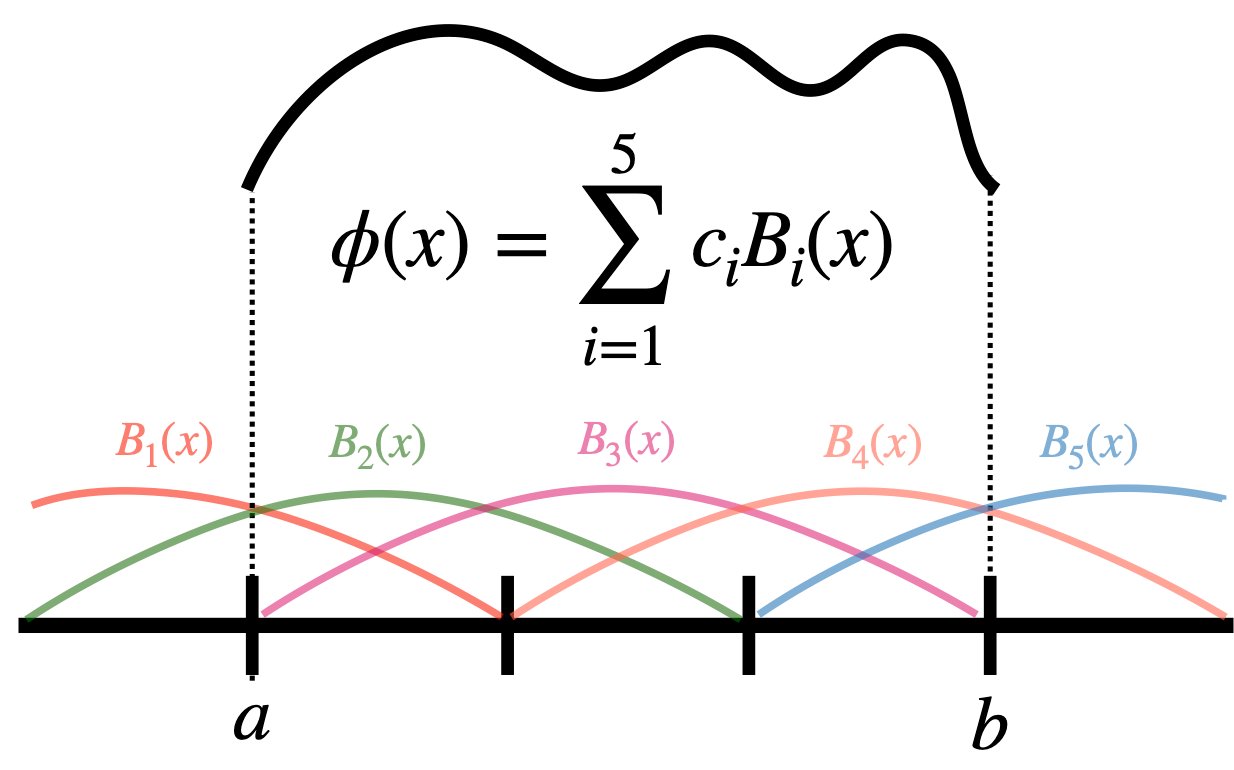
Within an interval the active basis functions all share the same shape, just shifted, so only their coefficients change from cell to cell. The hardware cost of a forward or backward pass scales with S+1, not with G. That means you can widen the grid to make the model more expressive, with near-constant resource usage on the chip. For online learning, the system stores the basis functions in LUTs rather than the finished activations, since the coefficients keep changing as training proceeds and the activations can no longer be precomputed.
The second property is stability under quantization. FPGA training usually struggles because weights and gradients span a wide range of magnitudes, and a fixed number of bits forces a tradeoff between fine precision and broad range. MLPs make this worse, since their matrix multiplications let output magnitudes grow with input magnitudes. B-splines sidestep the problem because they sum to one at every input, which mathematically bounds each activation between its smallest and largest coefficient. The gradients obey similar bounds. Activations and gradients therefore stay within predictable, input-independent ranges, which makes picking a good quantization range straightforward and keeps learning stable.
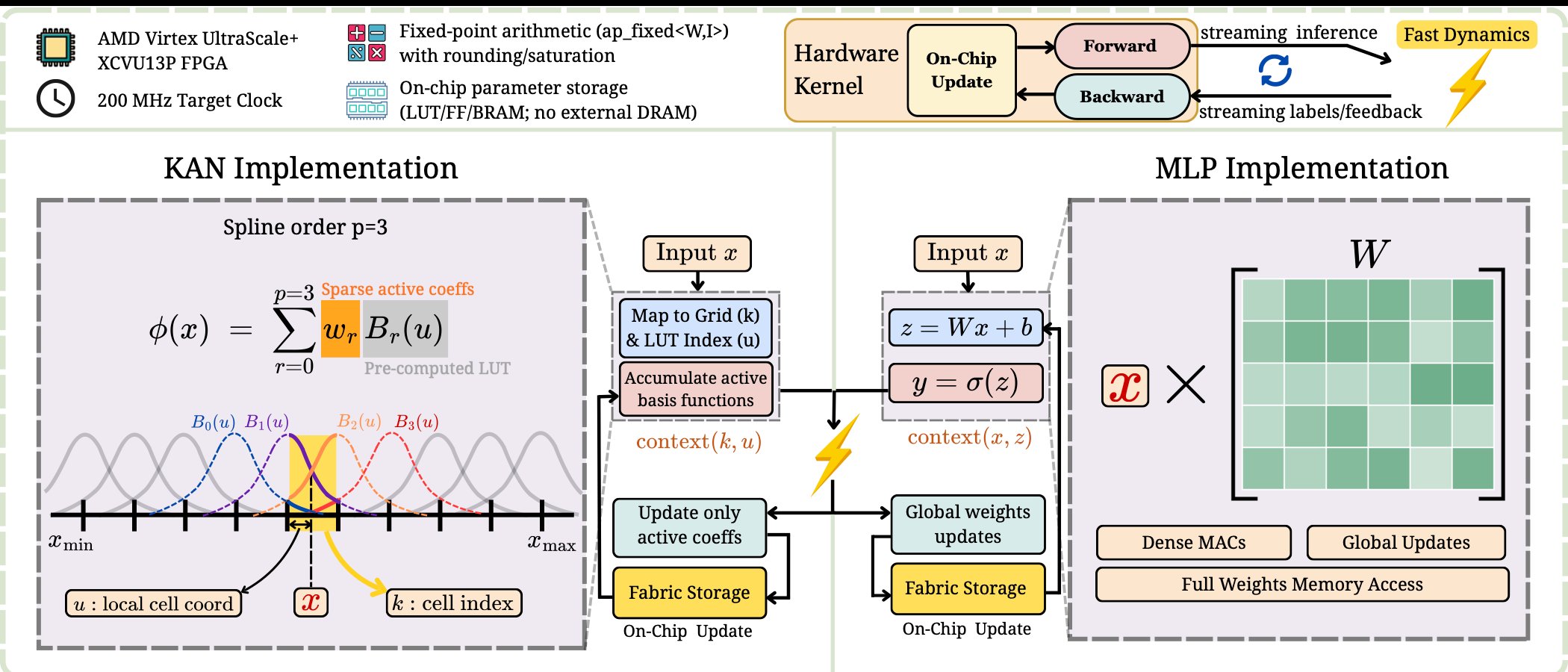
The mechanics of the forward pass come down to finding an input's interval index and its offset within that interval, looking up the S+1 basis values, and combining them with the interval's coefficients. The backward pass precomputes spline derivatives in LUTs, reuses the activations cached during the forward pass, multiplies gradients by a fixed learning rate, and adds them straight into the parameters. The result is online learners scaling past 50,000 parameters while completing forward and backward passes at sub-microsecond latency, a regime the authors say has not been reached before for gradient-based learning, with strong convergence across function approximation, qubit readout, and non-stationary control benchmarks.
Why this matters beyond the benchmarks
The broader takeaway is about where architecture research should look next. KANs have been pitched as a possible alternative to MLPs on the strength of scaling laws, parameter efficiency, and interpretability. Several of the properties that make them interesting, bounded local activations and sparse updates, are difficult to capitalize on with the dense matrix-multiply machinery of a GPU. On custom hardware, those same properties turn into concrete wins in latency and chip area.
The two papers together suggest a pattern worth watching: model architectures and hardware accelerators that are designed for each other, rather than a model invented for GPUs and later squeezed onto an FPGA. For the narrow but demanding set of applications that need decisions in nanoseconds and adaptation in fractions of a microsecond, that co-design approach is starting to look less like an academic curiosity and more like the practical path. The full thesis explainer and both papers go considerably deeper into the benchmarks and circuit details for anyone building in this space.
Comments
Please log in or register to join the discussion