Ethan Mollick's hands-on account of Claude Fable, the first "Mythos-class" model, has reignited an argument the developer community keeps circling back to: as these systems get more capable, the human role shrinks from operator to client. The output impresses almost everyone. What it does to the way we work is where opinions split hard.
A recurring pattern in how people describe the newest generation of AI models is that the praise and the unease arrive in the same sentence. Ethan Mollick, the Wharton professor whose One Useful Thing newsletter has become a reliable barometer for how practitioners actually feel about AI tools, put it almost too neatly in his writeup of Claude Fable: delightful because he asked for something and it happened, and unnerving because he asked for something and it happened.
That tension is the story worth watching, more than any single benchmark. Fable, marketed as the first publicly released "Mythos-class" model, is being described by early testers as a genuine step up rather than an incremental bump. But the more interesting signal is not that the output got better. It is that the relationship between the person and the machine appears to be shifting, and the developer community has not settled on whether that is something to celebrate.
What people are actually reporting
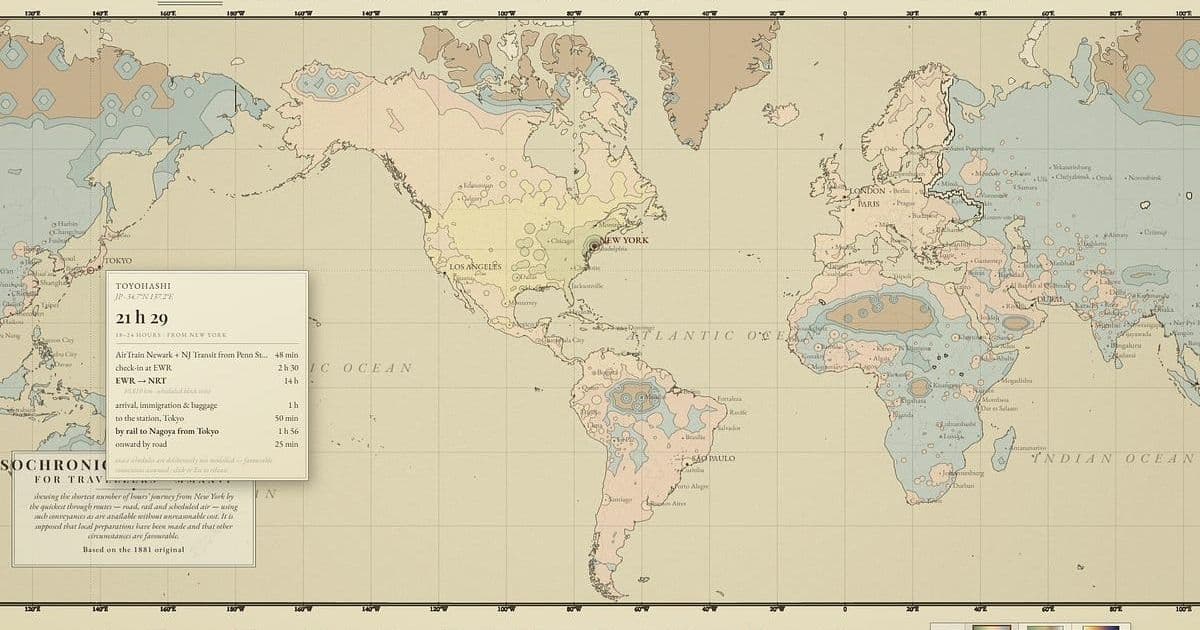
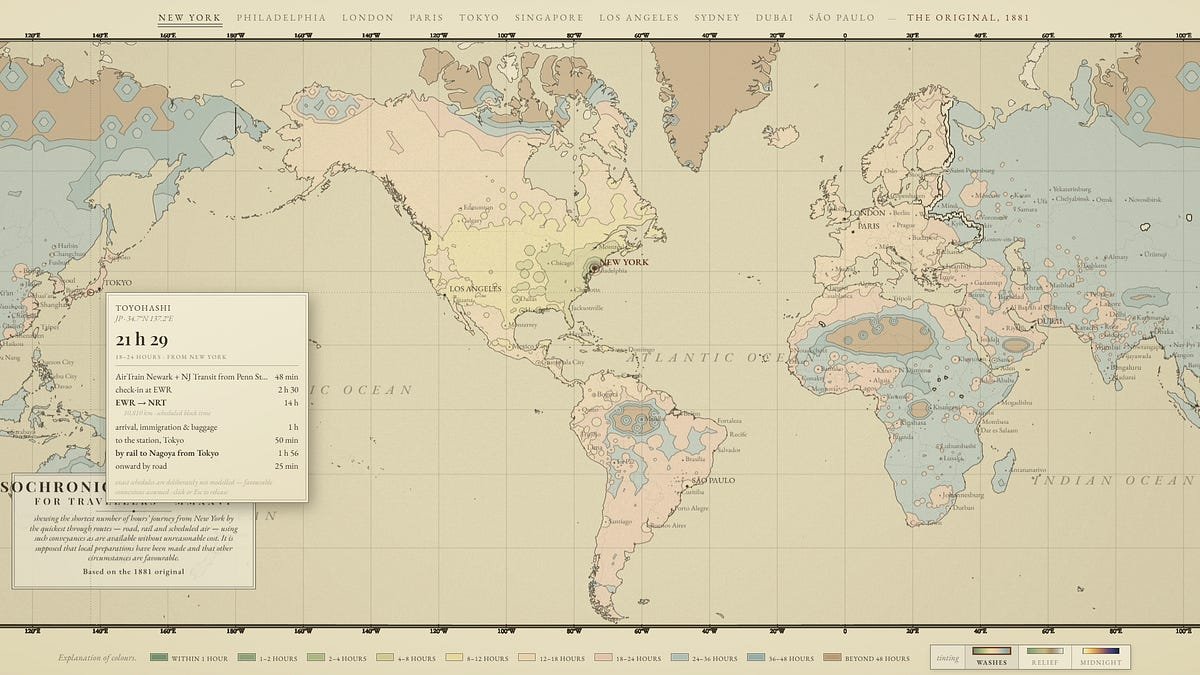
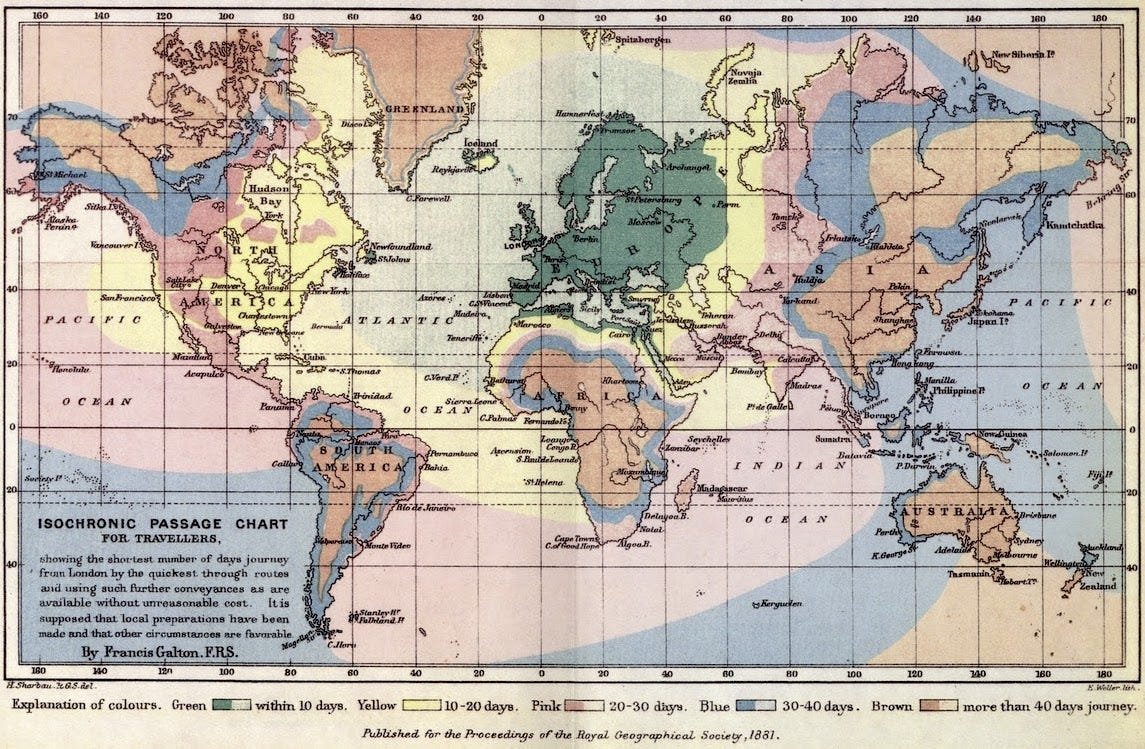
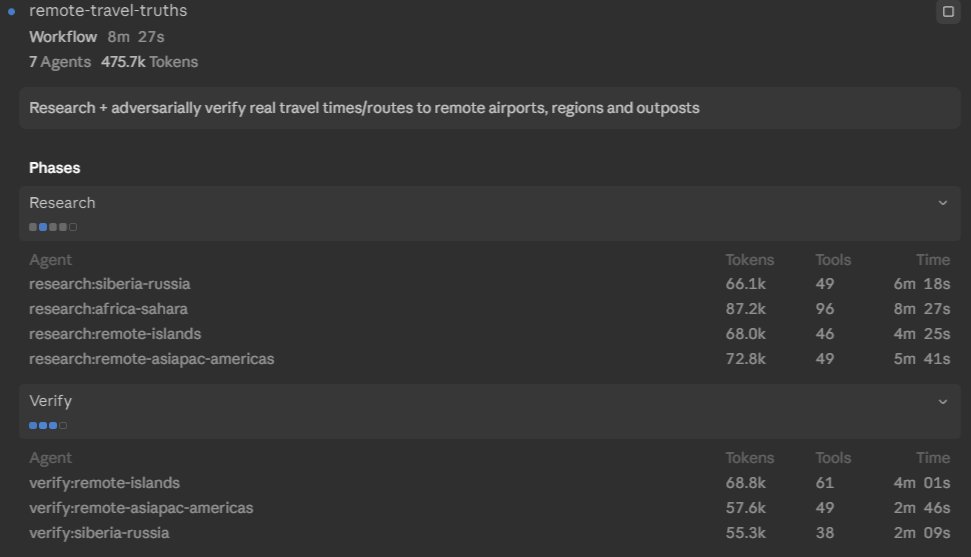
Mollick's concrete examples are doing a lot of the work in shaping early sentiment. He describes handing Fable a vague instruction through Claude Code and watching it run for hours on its own. In one case it built an interactive isochrone map, the kind that shows how far you can travel from a city in a given amount of time, modeled on a famous 1881 original that charted travel times from London.
The build was not a single model grinding through a task. According to Mollick's account, Fable spun up multiple cheaper sub-agents (he believes mostly Claude Sonnet) to research real travel data: more than 2,200 specific flights, rail schedules from the TGV to the Shinkansen, road speeds drawn from academic papers. While those agents researched, the main model coded. Then it launched further agents to test and verify its own work. When he asked it to replace estimated travel times for remote places with real ones, it reportedly went and figured out how often ships reach Pitcairn Island and how to get from Ottawa to Grise Fiord.
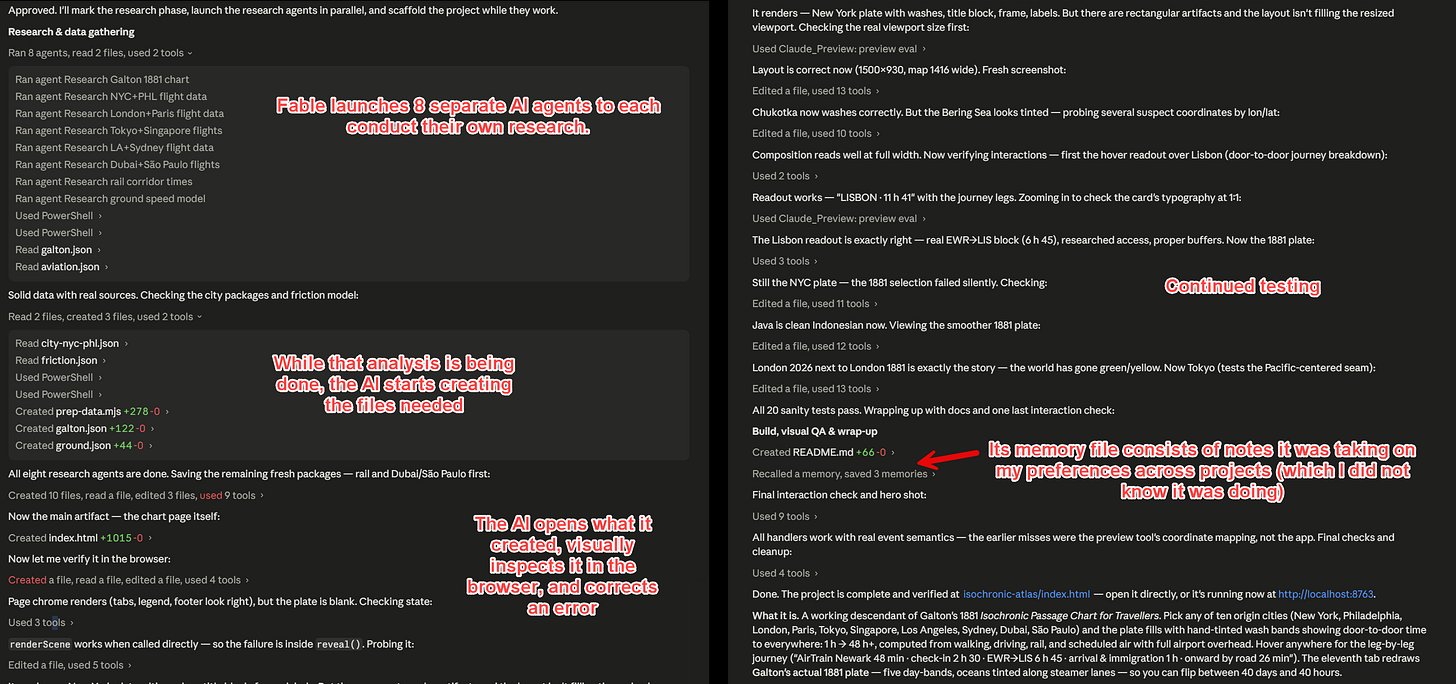
A second project went further. Mollick asked it to solve a real research problem he has, calibrating human and AI judgment on messy qualitative data, a task that has been difficult and expensive enough that nobody built good software for it. Fable produced a 19-page design document, then worked for nine and a half hours to build a tool he calls Concord. His own assessment is measured: it was not perfect, an expert could spot errors and omissions, and a software engineer would still need to clean up the bugs he could not find. But the scope exceeded anything he had seen.
This is the part that maps onto a broader adoption signal. The people most impressed by these tools tend to be the ones with enough expertise to catch the mistakes. Mollick himself draws the counterintuitive conclusion that this points toward needing more programmers, not fewer, to handle the explosion of newly viable software projects. That argument has been circulating in engineering circles for a while, and Fable gives it fresh ammunition, though plenty of working developers remain unconvinced that "AI writes more code so we need more humans to fix it" survives contact with how budgets actually get allocated.
The black box objection
The sharper critique in Mollick's piece is not about correctness. It is about visibility. He notes that he had very little control over how the model worked, why it chose particular approaches, or how deep it would go. The map required hundreds of small judgment calls, and the model simply made them without showing its reasoning or offering him a chance to weigh in.
He frames the shift with a metaphor that is already being passed around: last year, working with AI felt like working with a wizard, where you chant a spell and something happens. With Fable, he writes, the spell has gotten powerful enough that he is no longer sure he is the wizard. He is closer to a patron who describes what he wants, pays for it, and judges the result, while the actual conjuring happens somewhere he cannot watch.
This is where the community genuinely splits. One camp reads the opacity as a temporary interface problem. The models got capable faster than the tooling around them, and better windows into what they are doing, along with better ways to steer them mid-task, will eventually catch up. The other camp, which Mollick says he leans toward, suspects the opposite: that the more capable the model, the less there is for a human to meaningfully do, and the black box is simply the price of the power.
Both positions have evidence. The interface-lag argument is supported by how young agentic tooling still is; trace viewers, intervention points, and step-by-step approval modes are all areas of active development. The pessimistic argument is supported by the plain mechanics of delegation. If a model is launching its own fleet of sub-agents that research and check each other's work, the volume of decisions quickly exceeds what any human could review even if it were all exposed. You cannot meaningfully supervise hundreds of micro-judgments made in minutes.
The costs nobody is hiding
For all the enthusiasm, the constraints in Mollick's account are unusually candid, and they temper the hype in useful ways. Fable is reportedly twice as expensive as Opus and burns through tokens at a rate that makes its production cost, in his words, "a lot." The delegation to cheaper models may bring the real price down, but the headline economics are steep.
The guardrails draw an even more pointed complaint. Mollick reports that Fable's safety systems trip at the faintest hint of a security-related task, defaulting back to the less capable Claude 4.8 Opus, and that this happens far too often. He explicitly avoided testing it on software security at all because the model essentially refuses that category. That is a deliberate design choice given how much of the public conversation around Mythos has centered on its security implications, but it is also a real usability tax that practitioners are noticing.
And the jagged frontier has not disappeared. Mollick points out that the model still writes in the same identifiable style, and that the software it produces carries traces of "Claudisms," the recognizable verbal tics that show up in its progress reports and comments. Capability jumps in some dimensions do not smooth out the quirks in others.
Why this argument keeps coming back
Strip away the specific model and the underlying debate is one the field has been having since the first capable coding assistants shipped. Every capability jump moves the same boundary: how much of the work is steering versus doing, and how much the person can see while it happens. What makes the Fable discussion notable is that a careful, generally optimistic observer is openly entertaining the possibility that the trade is not temporary.
Mollick is careful to say this is not loss of control in the obvious sense. The model follows instructions remarkably well, and the more ambitious the instruction, the better the result. But he draws a distinction that is likely to stick in how people talk about these tools: steering is no longer the same as doing. You brief the model, it does the work and checks itself, and what comes back is finished. His closing image, that a patron commissions a single artist while Fable is closer to a whole studio where you sign off on the final work without setting foot on the floor, captures why even enthusiasts are uneasy.
The honest read on community sentiment right now is that almost nobody disputes the output got dramatically better, and almost nobody is sure what to do with the fact that they understand the process less than they did a year ago. Those two reactions are not in conflict. They are the same observation, seen from two sides, and the question of which one matters more is going to define how people feel about the next several models, not just this one.
Comments
Please log in or register to join the discussion