
Anthropic released Claude Fable 5, a Mythos-class model that tops most public benchmarks, alongside Mythos 5, a restricted variant with cyber safeguards lifted for vetted defenders. The interesting part is not the benchmark sweep but the safety architecture: roughly 5% of sessions get silently downgraded to Opus 4.8 when classifiers flag cybersecurity, bio, or distillation queries.
Anthropic announced Claude Fable 5 and Claude Mythos 5 on June 9, 2026, two models that share the same weights but differ in what they're allowed to do. Fable 5 is the version available to everyone through the Claude API as claude-fable-5. Mythos 5 is the same network with some safeguards removed, handed only to a small set of cyber defenders and, soon, biology researchers. The naming split is the whole point: per Anthropic's own footnote, the safeguards are the only thing distinguishing the two.

That framing is worth taking seriously, because it tells you what Anthropic actually built. The capability work and the safety work are being shipped as one package, and the company is explicit that it tuned the controls to be too aggressive on purpose.
What's claimed
Fable 5 is positioned as state-of-the-art on nearly every capability benchmark Anthropic tested, with the lead growing on longer and more complex tasks. The headline numbers cover software engineering, knowledge work, vision, and scientific research.
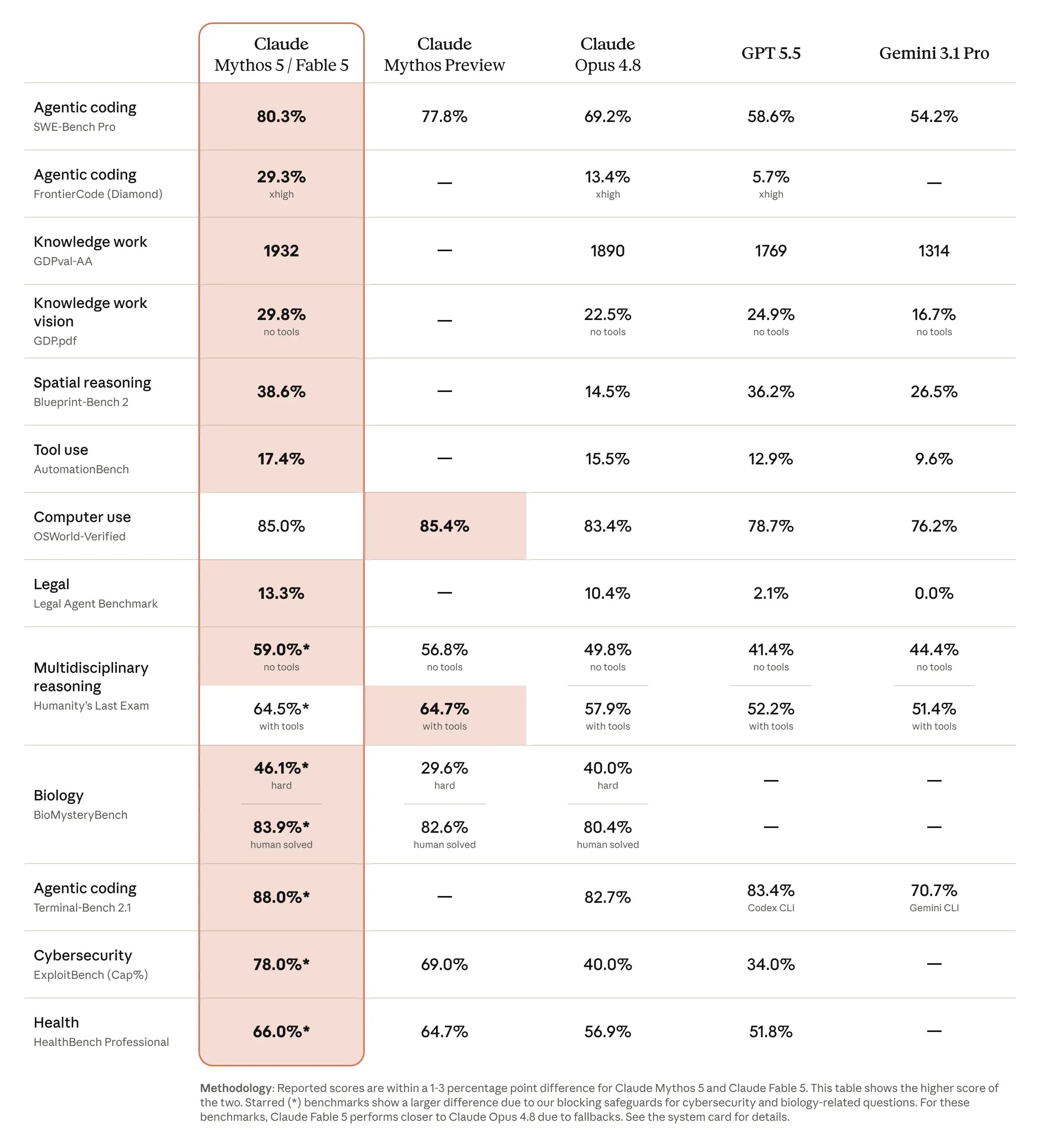
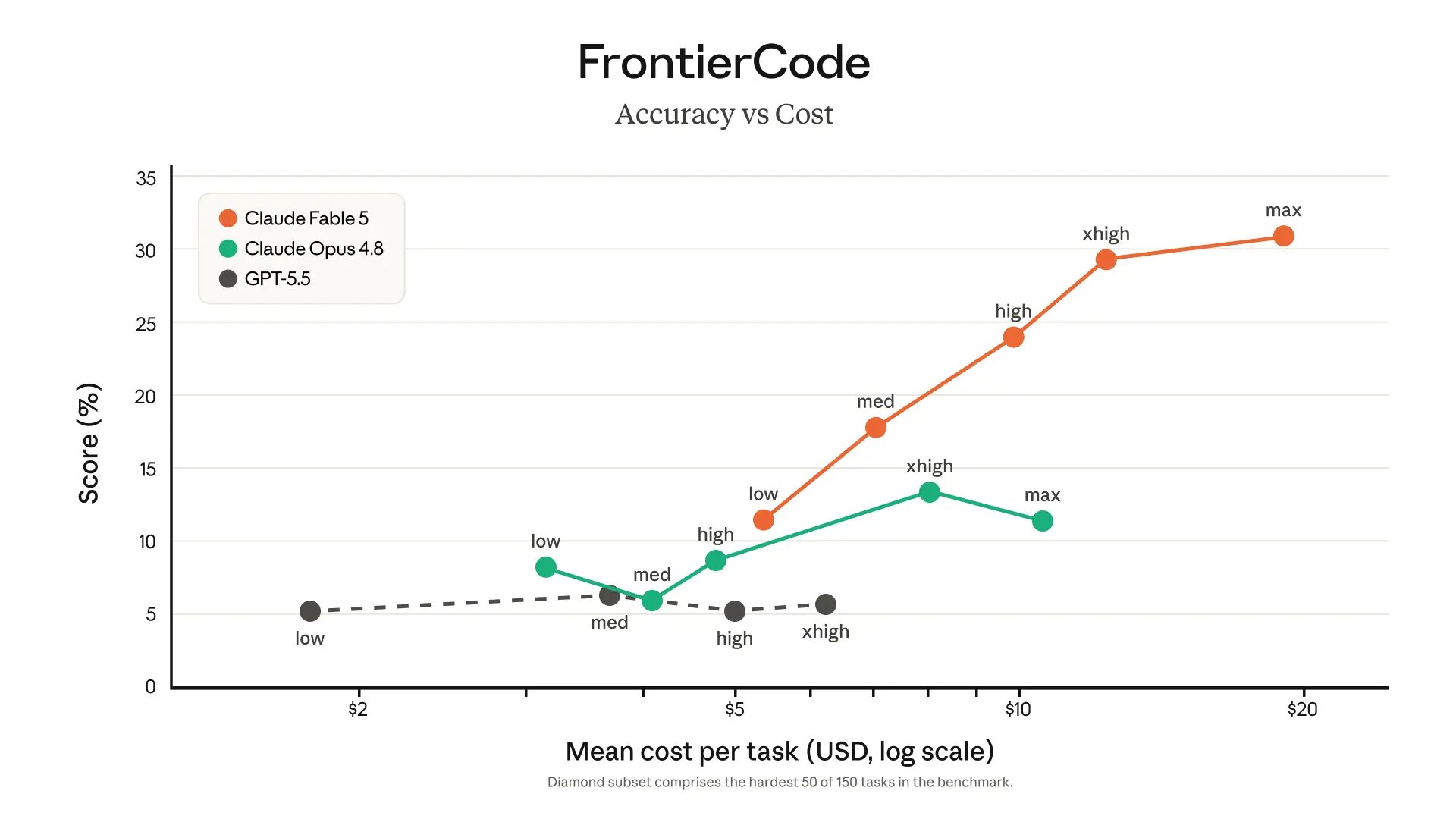
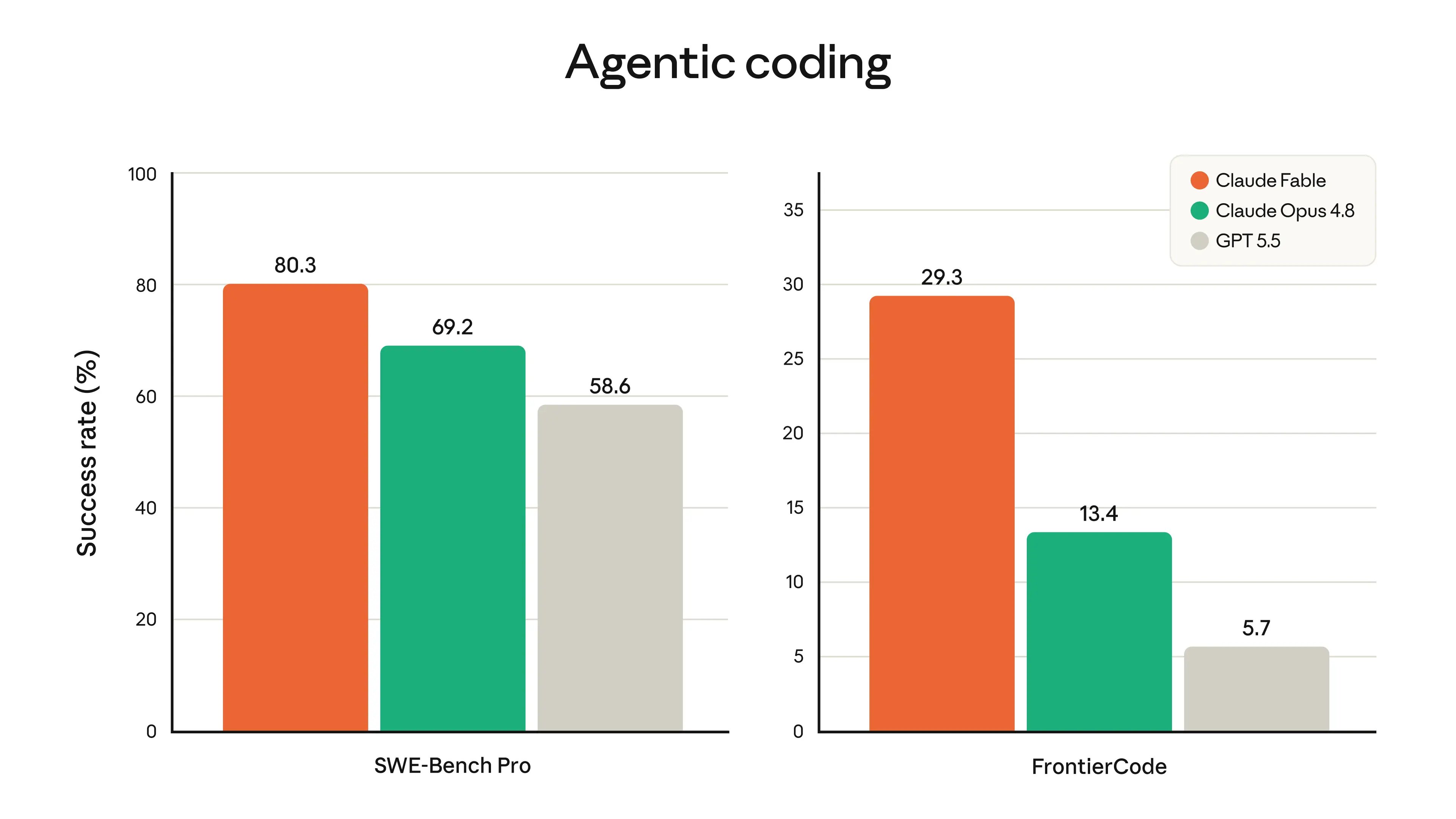
The software engineering claims are the most concrete. Stripe reported that Fable 5 ran a codebase-wide migration across a 50-million-line Ruby codebase in a day, work it estimated would have taken a team over two months by hand. On Cognition's FrontierCode evaluation, which checks whether a model can pass hard coding tasks while meeting production-quality standards, Anthropic says Fable 5 scores highest among frontier models even at medium reasoning effort. The token-efficiency angle matters here: several early testers reported the model finishing in fewer turns and 25 to 30% faster on routine suites, which directly affects cost at $50 per million output tokens.
On knowledge work, Anthropic cites Hebbia's finance benchmark for senior-level reasoning and trading-analysis evaluations from IMC. One customer reported Fable 5 as the first model to break 90% on their core analytics benchmark, a 10-point jump over Opus.
The vision results include a detail that's easy to overlook. Earlier Claude models needed elaborate helper harnesses, maps, navigation aids, game-state feeds, to play Pokémon FireRed. Fable 5 finished the game with a vision-only harness reading raw screenshots. The same screenshot-to-code capability lets it rebuild a web app's source from images alone.
What's actually new
Strip away the benchmark sweep and two things are genuinely different from prior releases.
The first is sustained autonomy with memory. Anthropic's Slay the Spire test is a useful proxy because it isolates the effect of persistent file-based memory. Giving Fable 5 access to its own notes improved performance three times more than the same memory gave Opus 4.8, and Fable reached the game's final act three times as often. The model isn't just bigger; it's better at using state it accumulates over a long run, which is what long-horizon agentic work actually requires.
The second is the science. Anthropic claims Mythos 5 is its first model to consistently generate novel, compelling scientific hypotheses. In blinded comparisons against Opus-class models, its molecular biology hypotheses were preferred about 80% of the time, and one proposed mechanism for an E. coli protein was independently corroborated by a separate lab. On genomics, Mythos 5 reportedly worked largely autonomously for over a week, assembled single-cell data across 138 species, and trained a custom model that outperformed a recently published result in Science while being 100 times smaller.
For drug design, Anthropic says its protein design experts saw roughly a tenfold acceleration, with the model choosing binding sites, running protein design tools, and recovering from failures without human assistance. Nine of 14 protein targets yielded strong candidates. These are vendor-reported internal results, not peer-reviewed, and the genomics paper hasn't been published yet. Read them as promising signals rather than settled facts.
The safeguards are the architecture
Here is where the release diverges from a normal model launch. Fable 5 ships with classifiers, separate AI systems that watch for misuse, covering three areas: cybersecurity, biology and chemistry, and distillation. When a query trips a classifier, Fable 5 doesn't refuse. The request is silently routed to Claude Opus 4.8 instead, and the user is told it happened.
The design choice is clever. A fallback to a still-capable model is a far better experience than a hard refusal, and it lets Anthropic tune the classifiers conservatively without making the product feel broken. Anthropic says fallback triggers in under 5% of sessions, and that for the other 95%-plus, Fable 5 performs effectively the same as the unrestricted Mythos 5.
The cybersecurity rationale is the most defensible. Mythos-class models are good at finding and exploiting software vulnerabilities, and good at agentic hacking: reconnaissance, lateral movement, the full chain rather than just a single exploit. Anthropic's classifiers are designed to block progress on both. The company ran an external bug bounty with over 1,000 hours of testing that produced no universal jailbreaks, though it notes the UK AI Safety Institute made progress toward one in a short window. Anthropic is candid that fully preventing universal jailbreaks is likely impossible; the goal is to make them slow and costly enough to catch before they scale.
The biology and chemistry safeguards are deliberately the broadest, and Anthropic admits they're cruder than it would like. The justification is a specific evaluation: predicting how a genetic modification affects the assembly of an adeno-associated virus shell, using unpublished candidates from Dyno Therapeutics. AAVs are gene-therapy delivery vehicles, but the same predictive capability is dual-use. Mythos-class models reportedly beat dedicated protein language models on this task using general biological reasoning, which is exactly why Anthropic chose to fall back to Opus 4.8 on most biology and chemistry requests for now. That's a real cost to legitimate researchers, and the planned trusted-access program for biology is the escape valve.
The distillation classifier is more about competitive and proliferation concerns than direct harm: it targets attempts to extract Fable 5's capabilities to train competing models without equivalent safeguards.
There's also a data-handling change worth flagging. Anthropic will require 30-day retention for all traffic on Mythos-class models, including business and third-party surfaces. It says the data won't be used for training or any non-safety purpose, with logged human access and deletion after 30 days. Teams with strict data-residency or retention requirements should read the retention policy before routing sensitive workloads through Fable 5.
Limitations and the fine print
The pricing is the part most likely to bite. Fable 5 and Mythos 5 are $10 per million input tokens and $50 per million output, which Anthropic frames as less than half the price of Mythos Preview. But the subscription rollout is unusually conditional. From launch through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost. On June 23, it gets removed from those plans, and continued use requires usage credits. Anthropic says it intends to restore Fable 5 to standard subscriptions once capacity allows, but the honest reading is that demand is uncertain and the company is hedging. If you're building on Fable 5 through a subscription rather than the consumption-based API, plan for that cutover.
The other limitation is structural: the conservative tuning means benign requests will get downgraded. If your workflow touches security research, biology, or anything the classifiers read as adjacent, you may find yourself talking to Opus 4.8 without having asked to. For most users that's invisible. For the people doing exactly the high-value dual-use work these models are good at, it's the central friction, and the resolution depends on the trusted-access programs Anthropic is still standing up.
The capability story here is strong and the benchmark breadth is real, even discounting for the fact that most figures are vendor-reported. The more durable takeaway is the shift in how a frontier model gets shipped: not as a single artifact with a refusal layer bolted on, but as a tiered system where the same weights are exposed at different risk levels to different audiences, with a silent downgrade path in the middle. Whether that model of release holds up depends entirely on whether the classifiers stay ahead of the people trying to break them.
Comments
Please log in or register to join the discussion