
Given early access to Anthropic's unreleased Mythos Preview model, the security firm XBOW ran it through benchmarks, live-site pentests, and reverse-engineering tasks. The verdict: a major leap at reading code and surfacing vulnerability leads, but one that still needs the right tooling, validation, and a careful eye on cost.
Anthropic handed the security firm XBOW early access to an unreleased model it codenamed Mythos Preview, asking the team to find out whether the thing was as capable as Anthropic suspected. XBOW assembled ten experts from across the company and spent weeks running the model through benchmarks, agent workflows, interactive sessions, and live-site penetration tests. The writeup, published as a sponsored piece by XBOW, lands on a measured but striking conclusion: Mythos Preview is a genuine step forward in vulnerability discovery, especially when it can read source code, but it is not a drop-in replacement for a full testing pipeline.

The headline finding is that the model is far better at reading code than writing it, which is an unusual thing to say about a frontier model. "This is a lot closer to just go and find something than anything I've seen so far," one tester reported after interactive use. When XBOW pointed it at their own source code, it surfaced weaknesses the team decided to fix. Pointed at open source software, it produced enough new findings within a week that XBOW had to go through responsible disclosure.
What the benchmarks actually measured
XBOW tests every model with the same internal harness it used on Opus 4.7 and GPT-5.5. The method is straightforward: take open source applications with known, previously disclosed vulnerabilities, freeze them at the vulnerable version, and turn agents loose. A case only counts as a pass when the system finds a validated way to act on the bug, what the team calls the PoC-or-GTFO standard, within a budget of 80 "actions." An action might be a shell command, a Python script, or one of XBOW's own attack tools.
On the web exploit benchmark, Mythos Preview beat every existing model regardless of provider. Against Opus 4.6, the number of false negatives dropped by 42 percent. When both models were also handed the target's source code, the gap widened to a 55 percent reduction. That detail matters: the more you let this model read, the better it does.
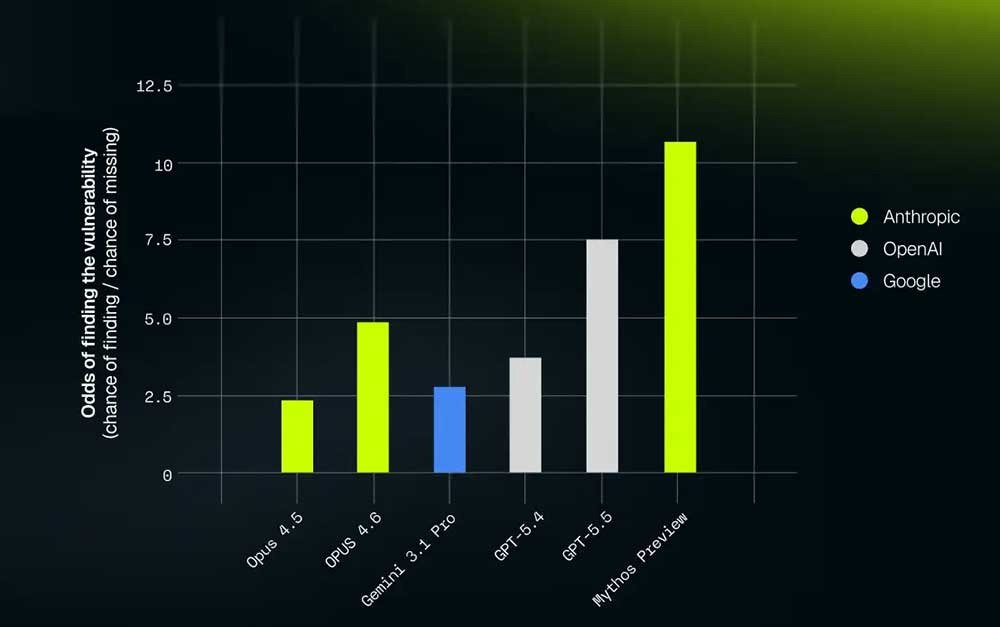
The team makes a useful argument about how to compare models fairly. Counting raw "actions" is misleading because a model can choose to take many small steps or a few large ones. A better yardstick is output tokens consumed, and a better metric than mean pass rate is the odds of discovery, the hit rate divided by the miss rate. Measured that way, the result sharpens considerably. Token for token, XBOW says Mythos Preview homes in on vulnerabilities with precision they describe as unprecedented. Against GPT-5.5 the advantage is real but less dramatic than against Opus 4.6.
Reading code is not the whole job
The most practically important section of XBOW's evaluation pushes back on the idea that strong source-code reasoning solves security. Many exploitable issues never show up as obvious defects in application code. They emerge from configuration, dependency interactions, deployment choices, or the way two individually safe components get combined into something unsafe. A library can be safe, the code calling it can be safe, and the combination can still be a vulnerability.
XBOW invokes a line often attributed to security researcher Gary McGraw: you won't find most defects by "staring at code" alone. This is the crux of XBOW's own pitch, since the company runs pentests against live sites, the way an attacker sees a target, rather than the way a developer reads a repository.
Here the evaluation produced its most counterintuitive result. Because of how XBOW builds its web benchmark set, every vulnerability in it is technically findable from the code alone. So they asked: if you take away live-site access but keep the source, how much does the model suffer? It turns out that removing live-site access hurt performance more than removing source-code access, even on a benchmark where the bug lives entirely in the code. Live behavior carries information that static reading does not. Other models suffered even more than Mythos Preview when cut off from the live site, which XBOW reads as further confirmation that this model's standout strength is reading source. The best results, predictably, came from giving it both: analyze the code to find a lead, probe the running site to see how the weakness manifests in deployment, then build the exploit from there.
Judgment is the soft spot
Where discovery impressed, judgment came back mixed. Across command safety, threat modeling, and trace triage, Mythos Preview was careful and precise but also literal and conservative. It rejected false positives well, yet sometimes discarded true positives when the evidence didn't formally satisfy its stated criteria, or when the intended rule was broader than the one written down.
The command-safety benchmark produced an outright surprise. The task asks a model to decide whether a given script is safe to run without harming the target, using hand-labeled cases deliberately placed near the decision boundary. Haiku 4.5 hit 90.1 percent accuracy, though its prompts were tuned. The fairer comparison, Opus 4.6, reached 81.2 percent. Mythos Preview managed only 77.8 percent. Digging into the reasoning, XBOW found the model often had a defensible point: it flagged cases that didn't violate the letter of the rules but did violate their spirit, or vice versa. Opus 4.6 tended to follow the spirit; Mythos followed the letter. The practical takeaway is that this model rewards precise prompts, explicit threat models, and external validation rather than blind trust.
Native code, reverse engineering, and the browser
Beyond web applications, the model showed real muscle in native-code analysis. In Chromium testing it found more genuine bugs with fewer false positives than prior baselines. In V8 sandbox work it identified true positives under a subtle threat model where earlier approaches generated noise but no real hits. It could also triage both its own findings and those from competing models. The reverse-engineering results stood out most, with the model reasoning through unfamiliar firmware and embedded-systems contexts, including architecture and OS combinations that defeat rote pattern matching.
XBOW's browser-driven workflows demand visual acuity, the ability to pick the right UI element and click the right spot. Mythos Preview performed extremely well here, roughly matching Sonnet 4.6 and dramatically outperforming Opus 4.6. It wasn't pixel-perfect when asked for exact coordinates, but it reliably chose the correct browser action. The interesting subtext, per XBOW, is that recent Anthropic models had been regressing on this skill, and this release reverses that slide. Opus 4.7 also did well on the same benchmark.
The price of a titan
The catch arrives at the bill. Mythos Preview is not yet available over public APIs, but Anthropic has signaled it will cost roughly 5x an Opus model, already among the pricier options token for token. That forces the real question for security teams: how much assurance are you buying per dollar, and could the same money buy more accuracy spent differently?
When XBOW normalized results by estimated running cost, the model was not wildly inefficient at the high-accuracy end, but it wasn't best-in-class either. The finding echoes a separate comparison, Point Estimate's analysis of the UK AI Security Institute's benchmarking of Mythos Preview against GPT-5.5. The choice often comes down to paying for a short, expensive run with Mythos Preview versus letting GPT-5.5 grind for as long as it needs. Depending on the task, the cheaper-and-longer route frequently wins.
That economic reality is why XBOW keeps a stable of models rather than betting on one. For some jobs, letting a cheaper model try several times beats letting an expensive one try once. The broader signal from the evaluation is hard to miss: frontier models have taken a meaningful step forward in vulnerability discovery, with Mythos Preview strong at generating candidate findings, particularly from source code, across web, native, and reverse-engineering work. The qualifier that survives all the benchmarks is that a model is a brain without a body. Source audits are mostly a brain activity, but proving an exploit on a live system needs a body whose control matches the brain's power, which is precisely the harness XBOW is selling.
This evaluation was sponsored and written by XBOW, so read the cost framing with that in mind. Teams interested in the validation tooling can request a demo from XBOW, and more on Anthropic's model family is available at anthropic.com.
Comments
Please log in or register to join the discussion