
A Microsoft-sponsored research project built an Azure-native pipeline that grades virtual meetings across five dimensions using GPT-5.4-mini and Azure Video Indexer. After scoring 68 real meetings, the team found a pattern worth the attention of anyone planning a cloud collaboration stack: most meetings nail the technical basics but fall short on engagement, and the tooling to measure that gap is now firmly an Azure play.
Microsoft just published research on a system that does something most collaboration platforms still don't: it scores how good your meetings actually are. The Online Meeting Effectiveness Index (OMEI), built as a Santa Clara University practicum in partnership with Microsoft's Commercial Engineering and AI Business division, takes a raw meeting recording and returns a numerical effectiveness score plus specific recommendations. For organizations weighing where to anchor their collaboration and analytics investments, the more interesting story is what the architecture reveals about Microsoft's direction with Azure AI and Foundry.

What changed
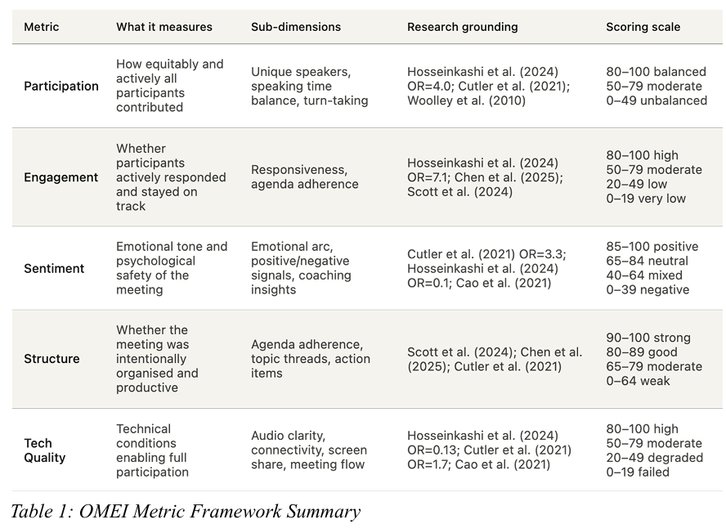
Meeting analytics has historically meant transcription and, at best, sentiment tags. OMEI pushes past that into evaluative scoring. The framework rates meetings on five umbrella metrics, Participation, Engagement, Structure, Sentiment, and Tech Quality, each broken into three sub-metrics for fifteen total indicators. The scoring rubric is grounded in published HCI research rather than vibes, which matters because it gives the output defensible weight in a corporate setting.
The headline numbers from 68 analyzed meetings: an average effectiveness score of 86 out of 100, with Tech Quality strongest at 92.3 and Engagement weakest at 77.3. In other words, the connection works fine but people aren't talking. The research cites a finding that speaking for just 10 percent of a meeting increases perceived inclusiveness fourfold, and that effectiveness drops roughly one percentage point for every two additional participants. These are the kinds of metrics that turn a soft management problem into something you can put on a dashboard.
What genuinely changed here is not the idea of meeting scoring but the demonstration that an LLM pipeline running on commodity cloud services can produce it at acceptable consistency, once you stop trusting the model to do math.
The architecture, and why it reads as a cloud strategy signal
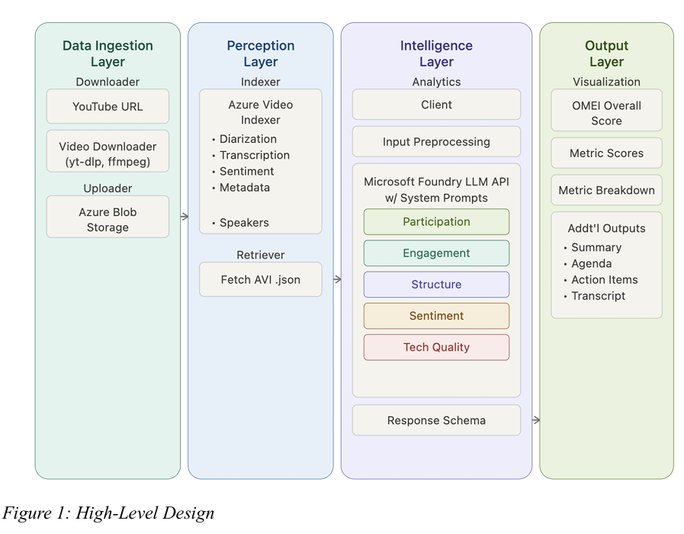
OMEI runs a four-layer pipeline that is almost entirely Microsoft-native. A YouTube URL goes through yt-dlp and FFmpeg for ingestion, lands in Azure Blob Storage, gets processed by Azure Video Indexer for diarization, transcription, and sentiment, and then flows into Microsoft Foundry for the LLM scoring. The output is structured JSON rendered in a lightweight web demo.
The model selection details are where a cloud architect should pay attention. The team tested GPT-5.4-mini, GPT-5.4-nano, DeepSeek-R1, GPT-5.4, and Phi-4, all at the individual metric level. GPT-5.4-mini won, not because it was the most capable, but because it hit the best balance of scoring quality, consistency, and useful recommendations. Larger models over-interpreted the task; smaller ones produced thin rationales. That Foundry made it trivial to swap five different models, including a non-Microsoft option like DeepSeek-R1, behind the same orchestration is the real point. The model is now a configurable component, not an architectural commitment.
There is also a candid engineering admission that should temper any vendor's AI marketing: none of the models could reliably do time-based calculations from diarization data. Speaking-time totals, balance ratios, and silence detection all had to be preprocessed deterministically before the LLM ever saw them. The team built the Gini coefficient and dominant-speaker share calculations outside the model and fed the results in. This is the pattern that keeps showing up across production LLM systems. The model handles qualitative reasoning, conventional code handles anything that needs to be numerically correct.
Provider comparison: where this fits across the major clouds
For teams choosing a stack, OMEI is essentially a reference architecture for Azure-centric meeting intelligence, and it is worth comparing against what the other major providers would require to build the equivalent.
Microsoft Azure. The tightest path. Video Indexer handles perception, Foundry handles model orchestration and structured output, Blob Storage handles state. The obvious endgame is integration into Microsoft Teams, which would put effectiveness scoring next to the meeting data that already lives there. The research itself flags that for production you would likely swap Video Indexer for Azure Speech, since the scoring leans on transcripts and timing rather than visual analysis, which would also cut cost. If your organization already runs Microsoft 365, the data gravity argument is hard to beat.
AWS. A comparable build would lean on Amazon Transcribe with speaker diarization, Amazon Comprehend or Bedrock for sentiment and reasoning, and S3 for storage, with Bedrock providing the multi-model flexibility that Foundry provides here. AWS gives you broad model choice through Bedrock, including Anthropic's Claude and others, but you would be assembling the perception layer from more pieces rather than getting Video Indexer's bundled diarization, transcription, and metadata in one service.
Google Cloud. Vertex AI plus the Speech-to-Text API and Gemini models would cover the same ground, and Google's meeting data story is strong if you live in Google Workspace. The trade-off mirrors the AWS one. You get capable primitives but assemble more of the orchestration yourself.
The practical decision rarely comes down to raw capability, because all three clouds can build this. It comes down to where your meeting data already lives. Collaboration data has enormous gravity. If your calls run through Teams, exporting recordings to another cloud for scoring adds egress cost, latency, and a compliance surface you probably don't want. OMEI being Azure-native is less a technical verdict than an acknowledgment of that gravity.
The validation work nobody usually shows
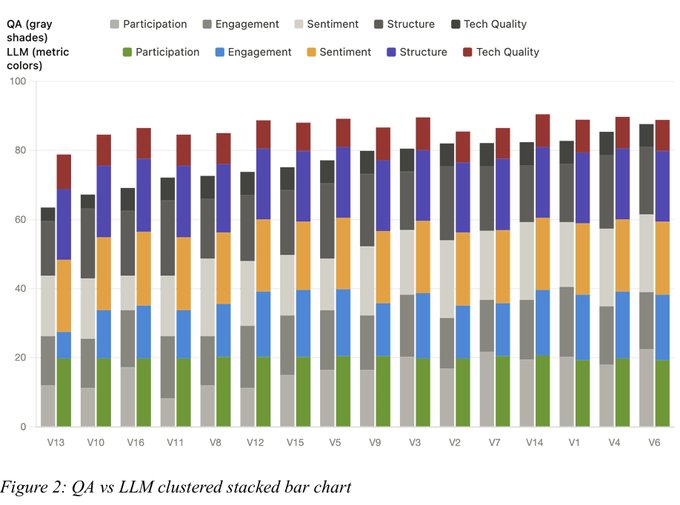
One section deserves credit because it addresses the question every executive asks about AI scoring: can you trust it? The team ran a human ground-truth study. Seven student analysts with no exposure to the model reviewed 14 meetings through a structured rubric, producing a composite human average of 66.84 out of 100.
The uncalibrated LLM averaged 87.1, roughly 20 points higher. The model was systematically generous, handing out good scores regardless of actual quality. This is the failure mode that quietly undermines a lot of AI evaluation tooling. It looks like it works because the numbers seem plausible, but it isn't discriminating between good and bad inputs.
The fix was prompt engineering with teeth. The team replaced default scoring logic with explicit requirements for affirmative evidence and hard scoring caps tied to measurable signals like dominant-speaker percentage, silence ratio, and agenda adherence. That pulled the revised average down to 72.5, within about 6 points of the human reviewers, and crucially increased the variance so the model started separating strong meetings from weak ones. The lesson generalizes well beyond meetings: an LLM evaluator needs to be forced toward strictness with measurable anchors, or it will inflate everything toward the pleasant middle.
Business impact
For cloud and collaboration strategy, three things follow from this work.
First, meeting effectiveness is becoming a measurable, billable cloud workload rather than a management seminar topic. If 17 percent of meetings are perceived as ineffective, and that is the conservative estimate, the labor cost is substantial, and a scoring layer that flags recurring patterns has a clear return. Organizations should expect this capability to arrive as a native Teams feature rather than something they build, which makes the build-versus-wait question real for anyone considering a custom version now.
Second, the migration and lock-in calculus is the familiar one. Building OMEI-style analytics on Azure is straightforward if you are already there and an active integration project if you are not. The egress and compliance cost of moving recordings out of your collaboration platform to score them elsewhere is the kind of thing that quietly locks the analytics layer to wherever the meetings happen. Plan the data residency and processing location before you plan the model.
Third, the preprocessing lesson has direct cost and reliability implications for any LLM project, not just this one. Pushing deterministic calculations out of the model reduces error, improves consistency, and often lets you use a smaller, cheaper model. GPT-5.4-mini beat GPT-5.4 here partly because the hard numerical work was already done before the model was invoked. Teams budgeting for AI features should assume a real engineering layer around the model rather than expecting the model to be the whole solution.
OMEI is explicitly a proof of concept, and the team is upfront about its limits, generic recommendations, a dataset drawn from public YouTube recordings, and validation against student reviewers rather than domain experts. Treat the scores as directional. The signal for cloud strategy is clearer than the product itself: meeting intelligence is consolidating onto the platforms that already hold the meeting data, and Microsoft is building the reference implementation in the open. The full writeup and architecture details are available through the Microsoft Foundry Blog on the Tech Community.
Comments
Please log in or register to join the discussion