
Microsoft just put a new managed PostgreSQL service into preview, and the pitch is direct: roughly 3x the transaction throughput of self-managed Postgres on identical hardware, zone-resilient storage by default, and AI retrieval features built into the engine. For teams weighing where to run Postgres across AWS, Google Cloud, and Azure, HorizonDB reframes the comparison around storage architecture and AI proximity rather than raw instance specs.
Microsoft has announced Azure HorizonDB, a new cloud-native PostgreSQL service now in preview. The headline claim is a performance multiplier: on the same hardware, same Azure region, and same Postgres version with high availability enabled, Microsoft demonstrated self-managed Postgres delivering roughly 4,200 transactions per second against HorizonDB's 11,000-plus. That gap, and the architecture behind it, is what teams evaluating their Postgres hosting strategy will want to understand.
This matters because HorizonDB is not Microsoft's only Postgres offering. The company also runs Azure Database for PostgreSQL, and it positions itself as a major upstream contributor to the open-source project. So the strategic question for cloud architects is less "should I use Postgres" and more "which managed Postgres, on which cloud, and what am I trading away by picking one."

What changed
The core architectural shift is the separation of compute and storage. In a traditional self-managed Postgres deployment, the engine and its storage are tightly coupled on the same machine, and high availability across availability zones typically introduces a latency tax because commits have to replicate before they are acknowledged.
HorizonDB decouples these layers. At the compute layer it runs a fully compatible Postgres engine, so existing applications, drivers, and tooling work without modification. At the storage layer Microsoft built a dedicated log service for transactions that sustains commit latency typically under one millisecond, paired with a shared storage platform that natively writes data across availability zones. The result is zone-resilient storage by default rather than as a bolt-on.
The performance gain comes from a new quorum commit protocol. Instead of flushing to local disk before durably committing, HorizonDB durably commits across zones before the disk flush completes. That lets you get cross-zone resilience and throughput at the same time, rather than picking one. Microsoft also attaches multiple read replicas to the same storage, with primary failover to any replica in under five seconds during an outage, and read scaling without the replication lag you would normally accept.
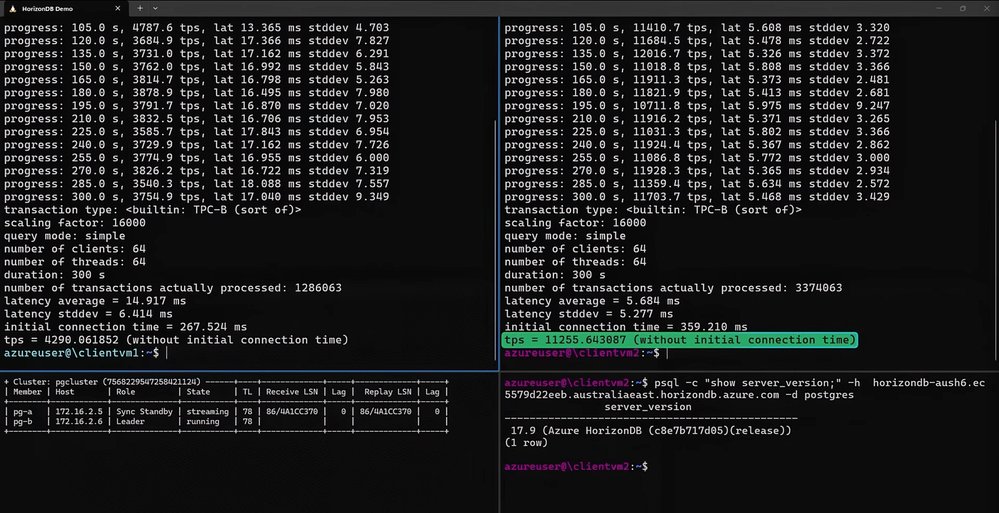
Provider comparison: where this lands against AWS and Google
The decoupled storage-and-compute model is not new as a concept. Amazon Aurora PostgreSQL pioneered this commercially, separating compute from a distributed storage fleet that replicates six ways across three availability zones. Google AlloyDB followed with a similar disaggregated design and an analytical acceleration layer. HorizonDB is Microsoft's entry into that same category, and the competitive framing is deliberate.
For teams already standardized on a cloud, the comparison tends to come down to three axes. First, compatibility and version currency: Microsoft is leaning hard on the claim that it ships new major Postgres versions on the same day they release upstream, with what it calls zero cloud lag. For organizations that have been burned waiting months for a managed provider to certify a new major version, same-day availability is a real procurement argument. Aurora and AlloyDB both run forked or heavily modified engines and historically trail upstream releases.
Second, the AI retrieval story, which is where HorizonDB tries to differentiate rather than match. More on that below.
Third, lock-in and portability. All three services keep wire compatibility with Postgres, so applications move. But the storage layer, the AI functions, and the operational tooling are proprietary to each cloud. A migration from Aurora to HorizonDB is straightforward at the SQL and driver level and meaningfully more involved if you have adopted provider-specific extensions, pipelines, or model integrations. That is the migration consideration to flag early in any multi-cloud plan: the engine is portable, the surrounding platform features are not.
The AI features are the actual differentiator
Vector similarity search in Postgres is already common through the pgvector extension, and chat-with-your-data workloads drove a lot of that adoption. HorizonDB pushes further in three directions that are worth understanding because they change what lives inside the database versus what you orchestrate around it.
Memory and storage rebalanced for vectors. Microsoft reworked how memory and storage cooperate so more IO moves to disk, using its DiskANN (disk accelerated nearest neighbor) technology. DiskANN keeps a quantized vector graph in memory and maps it to a full-precision graph on disk. The practical effect is that you can run high-quality similarity search over much larger vector datasets without paying for the memory you would otherwise need to hold everything resident. For teams whose embedding corpora have outgrown what fits economically in RAM, this is the kind of trade-off that changes cost models.
AI model management and SQL-native AI functions. HorizonDB can register a set of models (GPT, text embedding, and re-ranking) directly with your instance, or you can bring your own from Microsoft Foundry. Once registered, the Azure AI extension exposes SQL functions that call those models inline. A generate function produces a response from a prompt as a SQL result. An extract function pulls structured entities out of unstructured text, for example product features and customer sentiment, that you can then store and query. Writing those results back into the database means fast retrieval later and fewer repeated token charges, which is a genuine operational economics point rather than a demo flourish.
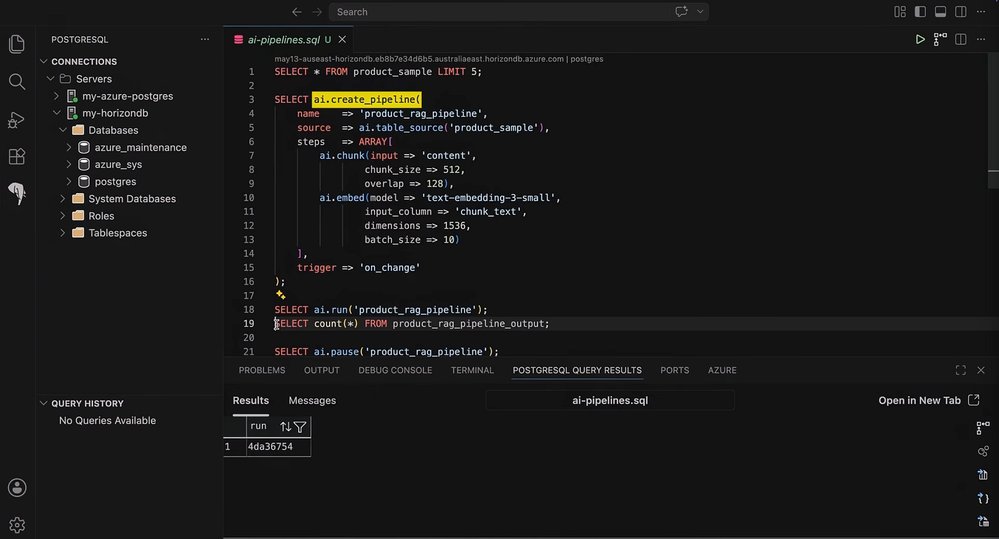
AI pipelines built into the engine. This is the piece that most directly attacks external infrastructure. Most generative AI applications rebuild the same brittle steps: chunk the data, create embeddings, backfill, usually in a separate orchestration service. HorizonDB's create pipeline function moves all of that into Postgres. It chunks data in real time as records are added, generates embeddings using the managed embedding model, and stores them in a table, asynchronously, without blocking the transactional workload. The pipelines are durable: you can pause and resume them, and if the server fails over, the pipeline fails over with it and keeps running. For architects who currently maintain a separate vector ingestion service, the value proposition is fewer moving parts and one less system to keep consistent with the primary database.
Finally, a rank function applies a re-ranking model such as Cohere on top of DiskANN similarity results. The demo searched for headphones with the highest playtime, where a plain index returned reasonable results around 40 hours, and the re-ranked query surfaced results of 60 hours and higher. The pattern is fast approximate retrieval first, then AI re-ranking for relevance, all in SQL.
Developer experience and operations
HorizonDB ships with a VS Code extension for Postgres that works against any Postgres instance and adds deeper integration when connected to Azure. It surfaces server management actions like network configuration, backups, and start/stop directly in the editor, and it includes visual query execution plans so you can identify an inefficient operator and let Copilot generate a fix in place. A built-in data cloning feature copies a server with all its data so you can validate a fix in a non-production environment in seconds.
For security, HorizonDB inherits the enterprise controls already proven in Azure Database for PostgreSQL: Entra ID integration for identity-based, passwordless access, private endpoints so the database is reachable only over your private network with no public exposure, and encryption at rest by default. These are available from day one rather than as configuration projects.
Business impact
For a team running self-managed Postgres on VMs today, the calculus HorizonDB presents is whether a roughly 3x throughput improvement plus default zone resilience plus eliminated pipeline infrastructure justifies moving to a proprietary managed storage layer. The throughput number alone can translate into fewer or smaller instances for the same workload, which offsets some of the managed-service premium.
For a team already on Aurora or AlloyDB, the relevant questions are version currency, the depth of the in-database AI tooling, and how much your existing stack depends on the current provider's proprietary features. If your AI retrieval is currently a separate service glued to the database, HorizonDB's consolidation argument is strongest; if you have invested heavily in another cloud's extensions, the switching cost rises accordingly.
The honest caveat is that HorizonDB is in preview, which means it is appropriate for evaluation and proof-of-concept work rather than production commitments today. Architects should treat the performance figures as vendor-supplied benchmarks and validate them against their own workload shapes before building a migration business case. The VS Code extension is available now in the marketplace, and Microsoft's Azure PostgreSQL blog is the place to track preview progress. The strategic signal is clear regardless of preview status: the managed Postgres competition is moving from raw database performance toward how close, how durable, and how operationally simple the AI layer can be, and HorizonDB is Microsoft's argument that the closest place to put it is inside the engine itself.
Comments
Please log in or register to join the discussion