
Microsoft is turning Postgres into a place where long-running data and AI workflows can run close to the tables they depend on, changing the build-versus-buy calculation for cloud database strategy.

What changed
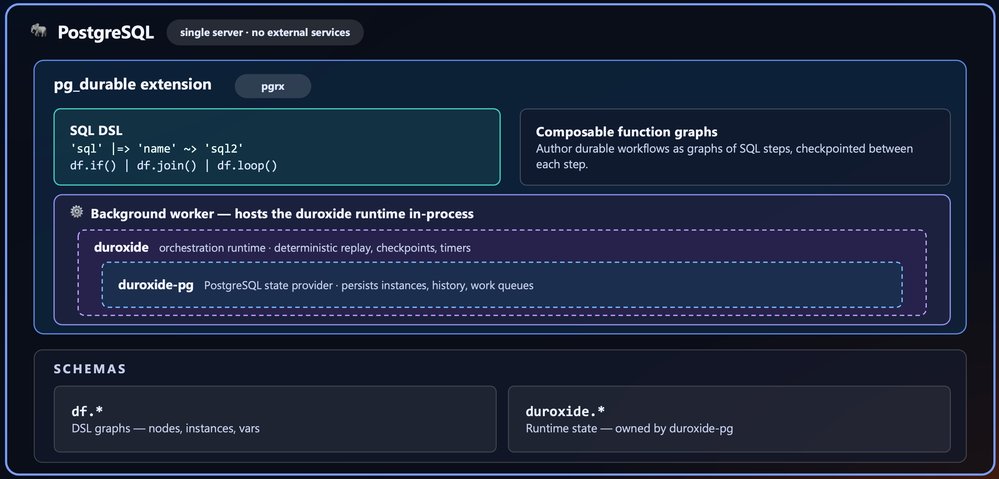
Microsoft introduced pg_durable, an open-source PostgreSQL extension that brings durable execution directly into the database. The extension is available in Azure HorizonDB, Microsoft's new PostgreSQL cloud service in preview, and can also be built for PostgreSQL 17 and 18 from the public repository.
The practical change is architectural. Teams that run multi-step jobs against Postgres often have to choose between keeping logic in PL/pgSQL, where long transactions and fragile sessions become a risk, or moving the workflow into an external system such as Temporal, Airflow, Step Functions, Argo, a queue plus workers, or a custom scheduler. pg_durable creates a third option: keep the workflow definition in SQL, start it asynchronously with df.start(...), and let a Postgres background worker execute the graph with checkpointing, retries, scheduling, parallel branches, and recovery.
That is a meaningful addition because it targets the coordination layer, not just query performance. Modern Postgres estates are no longer only serving application reads and writes. They are running batch transforms, materialized view refreshes, vector embedding jobs, approval flows, data enrichment calls, cleanup tasks, and nightly reporting pipelines. Those jobs are frequently tied to the same tables, roles, backups, and recovery objectives as the operational database. pg_durable moves the state of those jobs into the same durability boundary as the data itself.
Microsoft's Azure HorizonDB durable functions documentation describes pg_durable as the durable execution engine inside HorizonDB. A workflow is expressed as a graph of SQL steps using operators such as ~> for sequence, & for parallel join, | for race, ?> and !> for conditional branches, @> for loops, and |=> for capturing step results into variables. The workflow starts immediately from the client perspective, returns an instance ID, then runs in the background. Status and results remain queryable through SQL.

The extension also underpins HorizonDB's AI pipelines, which provide a higher-level azure_ai API for chunking, embedding, extraction, generation, ranking, sinks, and triggers. That matters for retrieval systems because embedding pipelines are deceptively operational. A service that chunks documents, calls an embedding model, and writes vectors can fail halfway through a batch. Without durable state, teams end up writing duplicate detection, restart logic, partial-run cleanup, and manual backfill tooling. HorizonDB's AI pipeline model compiles those steps into a durable graph, so a failed embedding step can be retried without redoing completed chunking work.
The strategic signal is clear: Microsoft is positioning Postgres not only as a managed relational database, but as an execution substrate for cloud-native data and AI workflows. This fits a broader provider pattern. AWS has invested in Aurora scale, serverless capacity, Global Database, Limitless Database, and integrations around event-driven architectures. Google has pushed AlloyDB for high-performance PostgreSQL-compatible workloads and AlloyDB AI for model-adjacent database work. Microsoft is now pressing on workflow durability inside Postgres itself, especially where the workflow's center of gravity is database state.
Provider comparison
From a cloud strategy perspective, pg_durable should be evaluated against three categories: managed Postgres capability, workflow orchestration model, and cost shape.
Azure HorizonDB with pg_durable is the most integrated route if the requirement is durable SQL-native workflow execution inside the database. HorizonDB's product page describes independent compute and storage scaling, pay-as-you-go billing by vCore, storage billed in GiB per month, and backup storage included up to 100 percent of the initial cluster size before additional backup charges apply. For teams already standardized on Azure, Entra ID, Microsoft Defender, Fabric, VS Code, and Azure OpenAI in Foundry Models, the appeal is not just that pg_durable runs in a managed service. It is that the operational experience lines up with the rest of the Azure estate.
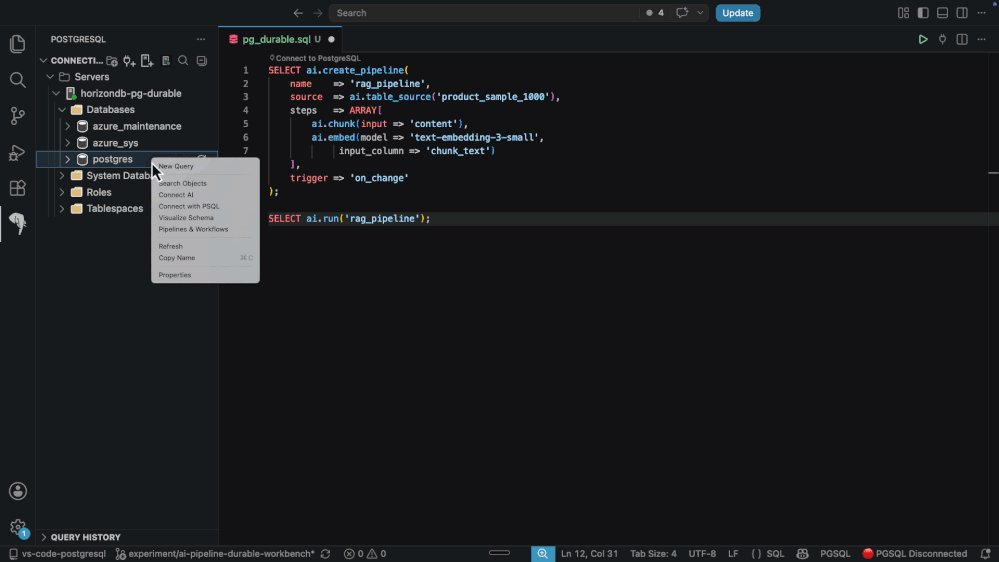
The Azure model is particularly relevant for AI and analytics teams building retrieval-augmented generation systems on operational data. A typical pipeline might read changed rows from a documents table, chunk the text, call an embedding model, write vectors to a sink table, and index with DiskANN or pgvector-style search. In a conventional design, this is often a separate service with its own queue, worker fleet, retry policy, and status database. In HorizonDB, the same pattern can be declared in SQL with ai.create_pipeline(...), run with ai.run(...), and monitored with SQL views. That can reduce the number of moving parts, although it also makes database resource governance more important.
AWS remains strong where the Postgres strategy centers on mature managed operations, global read patterns, and event-driven composition outside the database. Amazon Aurora PostgreSQL provides serverless and provisioned options, read replicas, Multi-AZ architecture, Global Database, and Aurora Limitless Database for horizontal scale. Its pricing page separates instance or ACU capacity, storage, I/O configuration, backup storage, data transfer, and optional features. Aurora Standard bills storage and request I/O, while Aurora I/O-Optimized removes read and write I/O charges in exchange for a different cost profile. Reserved Instances and Database Savings Plans can improve economics for steady workloads.
Where AWS differs is the orchestration boundary. AWS customers would usually combine Aurora PostgreSQL with Step Functions, EventBridge, Lambda, SQS, ECS, Glue, or MWAA for workflow management. That is powerful when the job spans many services, accounts, regions, APIs, and application runtimes. It is less compact when the workflow mostly reads and writes Postgres tables. AWS also controls which extensions are available in managed RDS and Aurora environments. The RDS PostgreSQL extension list shows a broad catalog, including pgvector and pg_cron, but third-party extension availability depends on AWS packaging and support. An open-source extension existing on GitHub does not automatically mean it can be installed on RDS or Aurora.
Google Cloud's main comparison point is AlloyDB for PostgreSQL, which focuses on performance, scale, and AI-adjacent database features rather than in-database durable workflow orchestration. The AlloyDB pricing page breaks charges into CPU and memory, database storage, backup storage, and networking. Google also notes that AlloyDB AI is available at no additional charge, while model calls are billed through the model provider. That structure can be attractive for organizations already using Gemini, Vertex AI, BigQuery, Dataflow, and Pub/Sub.
AlloyDB's strongest fit is analytical and AI-connected PostgreSQL-compatible workloads where Google Cloud services are already the surrounding platform. For durable orchestration, teams typically compose with Workflows, Cloud Run jobs, Cloud Scheduler, Pub/Sub, Dataflow, Composer, or application workers. That keeps orchestration outside the database, which can be better for cross-service workflows but less direct for Postgres-local transformations. Like AWS, Google Cloud's managed services maintain their own supported extension sets, so extension portability must be checked rather than assumed.
Self-managed PostgreSQL or provider-neutral managed Postgres is the fourth option. Because pg_durable is open source under the PostgreSQL License, it can be evaluated outside HorizonDB where teams control extension installation, background workers, shared preload libraries, and upgrade timing. This matters for multi-cloud strategies because it prevents the feature from being purely proprietary. A team could prototype locally, run it on a controlled Postgres 17 or 18 environment, and then decide whether HorizonDB's managed integration is worth adopting.
The trade-off is operations. Installing pg_durable yourself means owning compatibility testing, extension upgrades, backup validation, role grants, monitoring, worker health, and failover behavior. That is reasonable for platform teams with deep Postgres experience. It is less appealing for product teams that want the durable execution capability but do not want to become extension operators.
Pricing and migration considerations
The pricing conversation should not start with the extension. pg_durable itself is open source, but durable workflows consume database resources. A workflow that runs five SQL steps, fans out to three queries, calls external HTTP endpoints, writes status rows, and retries failed work is not free just because it is expressed in SQL. It shifts cost from an app-tier worker and external orchestrator into database compute, storage, logs, backup, and possibly model or API charges.
For Azure HorizonDB, the key line items are provisioned compute by vCore for primary and high availability replicas, data and log storage in GiB per month, backup storage beyond the included threshold, and the cost of any AI model calls used by azure_ai pipelines. The database may become more expensive if it absorbs work that used to run elsewhere. The business question is whether that added database consumption is cheaper than running and operating separate queues, schedulers, workers, status stores, and recovery tooling.
For AWS, compare against Aurora's capacity model. Serverless capacity is billed in ACUs, provisioned deployments are billed by instance usage, storage and I/O vary by configuration, and global or cross-region patterns add data movement and replication costs. If a workload already uses Step Functions and Lambda, the marginal cost of orchestration may be acceptable. If the job is mostly SQL against Aurora, the operational overhead of external orchestration can become the bigger cost than the service bill itself.
For Google Cloud, AlloyDB charges by CPU, memory, storage, backup, and networking. If the surrounding pipeline is already built on Pub/Sub, Cloud Run, Workflows, and Vertex AI, a database-local durable engine may not be a priority. If the team is trying to simplify Postgres-centric embedding backfills or recurring transformations, pg_durable on a self-managed Postgres estate may be worth testing even if the production managed service remains Google Cloud.
Migration should be treated as workflow modernization, not as a syntax conversion. The first candidates should be jobs with clear step boundaries and database-local state: ETL chains, dashboard refreshes, recurring maintenance, vector embedding backfills, scheduled data syncs, and approval flows. Avoid starting with workflows that require rich application runtime behavior, many SDK calls, or complex cross-service compensation logic. Those still belong in a general orchestrator.
A practical migration sequence is to inventory current background jobs, classify them by where their state lives, then move only the database-centered ones. For each candidate, define the step graph, identify nonidempotent actions, set retry expectations, and design observability before production rollout. External API calls need idempotency keys or deduplication guards because durable retry protects the workflow, but it cannot automatically make a third-party side effect safe. Long-running loops need cancellation procedures and runbooks. AI pipelines need cost controls such as incremental columns, explicit backfills, and paused triggers during tuning.
The extension support model also matters. On self-managed Postgres, pg_durable requires PostgreSQL 17 or 18, Rust build tooling for development, shared_preload_libraries, and background worker configuration. On managed databases, customers need provider support for the extension and its background worker model. HorizonDB is the first-class managed path today. For AWS RDS, Aurora, Google Cloud SQL, and AlloyDB, teams should verify supported extension lists and roadmap commitments before assuming portability.
Business impact
The strongest business case for pg_durable is reducing operational surface area around database-centric work. Many organizations have accumulated small orchestration systems around Postgres: one service for nightly aggregation, another for embeddings, another for cleanup, a queue for retries, a status table for progress, a cron entry for scheduling, and a runbook for partial failures. None of that is strategic by itself. It exists because the database lacked a durable background execution primitive.
If pg_durable works well in production, it can simplify that layer. Teams can express the workflow close to the data, inherit database backup and recovery for workflow state, inspect progress with SQL, and reduce the amount of custom coordination code. That is especially valuable for AI systems, where the expensive part is often not the first embedding run but the lifecycle after launch: changed documents, model upgrades, partial backfills, failed batches, approvals, and auditability.
There is a governance angle too. Running workflows in Postgres means database teams must set clearer policies for who can submit durable functions, which roles can call HTTP endpoints, how much parallel work is allowed, how retention is handled for workflow history, and how noisy jobs are isolated from transactional workloads. This is not a reason to avoid the model. It is a reason to treat it as platform capability, with guardrails, quotas, and monitoring.
The provider strategy is nuanced. Azure HorizonDB gains a differentiated feature for organizations that want Postgres, AI pipelines, and Microsoft ecosystem integration in one managed service. AWS remains attractive for large production estates that prefer mature external orchestration and Aurora's established operational model. Google Cloud remains strong where AlloyDB, Vertex AI, and data services are the main platform anchors. Self-managed Postgres gains an open-source path, but only for teams willing to operate extension infrastructure themselves.
For multi-cloud leaders, the right conclusion is not to move every workflow into the database. The right conclusion is to split orchestration by center of gravity. If a workflow is mostly database work, pg_durable is now a serious option. If it is mostly cross-service application logic, use a dedicated orchestrator. If it is an AI pipeline over Postgres tables, HorizonDB's azure_ai surface deserves a proof of concept because it packages durable execution into a model that data teams can operate with SQL.
The release gives cloud architects a new design choice: database-local durable execution for workloads that previously required extra infrastructure. That choice will not replace Airflow, Temporal, Step Functions, or Workflows. It will force a cleaner architecture review, because some jobs were never distributed workflows in the first place. They were Postgres jobs waiting for Postgres to learn how to run them durably.
Comments
Please log in or register to join the discussion