
Researchers cut per-token KV cache memory about 100x since 2017, giving AI products the room to handle long codebases, documents, images, and agent sessions.
New compression work
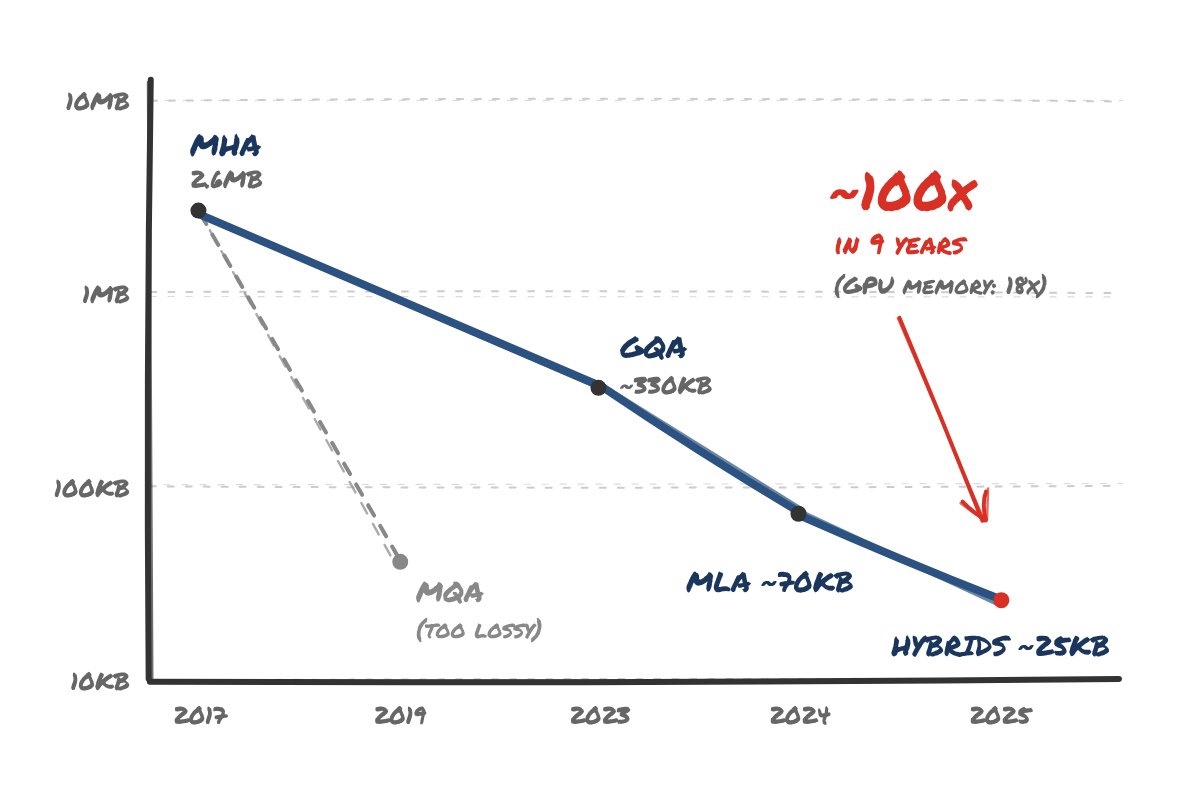
AI researchers have made long context windows viable by cutting the memory cost of the KV cache. Martin Alderson's history of KV cache compression frames the change in useful terms: a 70B-class transformer that needed about 2.6MB of GPU memory for each token in 2017 can now run designs that spend tens of kilobytes per token.

Google researchers introduced the transformer in Attention Is All You Need in 2017. The architecture gave language models a stronger way to connect tokens across a sequence, but it also gave inference servers a memory bill that grew with each token a user added.
You hit that bill through the KV cache. During generation, the model saves key and value vectors from earlier tokens so it can avoid recomputing them on each new token. A longer chat, a larger codebase, or a stack of PDFs all add entries to that cache. The model may have enough parameters to reason over the material, while the serving system runs out of GPU memory before the user finishes the task.
For a 70B-class dense model at 16-bit precision, a 128,000-token context using multi-head attention needs about 340GB of GPU memory for one conversation. A 2017 Tesla V100 shipped with 16GB of HBM2 memory. You would need about 20 top-end GPUs from that era to hold the cache for one long session before accounting for model weights and runtime overhead.
Noam Shazeer attacked that cost in 2019 with multi-query attention. In classic multi-head attention, each query head owns separate key and value heads. Shazeer made all query heads share one key-value head. A model with 64 attention heads could cut the cache by 64x. That design helped inference speed, but model quality and long-context recall suffered enough to limit adoption.
Researchers refined the trade-off in 2023 with grouped-query attention. GQA lets groups of query heads share key and value heads. That middle ground gave model builders a large memory cut with less quality loss than MQA. Meta used GQA in Llama 2 70B, and Mistral paired related memory work with sliding window attention in Mistral 7B.
DeepSeek made the next large move with DeepSeek-V2 in 2024. Its multi-head latent attention compresses keys and values into a latent vector. DeepSeek reported a 93.3% KV cache reduction versus DeepSeek 67B, plus a 5.76x maximum generation throughput gain. The technique shifted attention work away from raw memory movement, which matters because modern inference often waits on bandwidth.
KV cache quantization added another lever. Serving teams store key and value tensors at 8-bit or 4-bit precision instead of 16-bit precision. That choice can double or quadruple effective cache capacity, subject to accuracy loss and kernel support. Framework work such as vLLM PagedAttention handles cache allocation and reuse, while architectural work such as MLA reduces the bytes each token needs.
Linear attention hybrids pushed the idea further in 2025. Qwen3-Next and Kimi Linear keep full attention in selected layers and replace other layers with linear or recurrent state. Kimi's paper reports up to 75% less KV cache usage and up to 6x decoding throughput at a 1 million-token context.
Developer experience
Developers feel KV cache compression through fewer context trade-offs. A coding agent can read more files before it has to summarize its state. A document workflow can keep more source text in the prompt. A multimodal assistant can mix screenshots, PDFs, and logs without forcing the user to split the job into small batches.
The change also reduces a class of product code that existed to work around short windows. Teams built chunkers, retrieval flows, message deletion rules, and compaction prompts because GPT-3.5-era windows could hold a few pages. Those tools still matter, but large windows let developers treat context management as product design rather than emergency plumbing.
Frontend framework versions do not gate this capability. React, Vue, SvelteKit, Next.js, Remix, and native browser apps send the same API requests they sent before. Browser support also stays straightforward: Chrome, Safari, Firefox, and Edge do not need a new local API for longer AI context. Model providers, inference teams, and GPU kernels carry the change on the server.
That server-side boundary affects UX. Users judge the feature through upload limits, latency, task continuity, and failure modes. A product that accepts a whole repository but times out after three minutes will feel worse than a product that asks for selected folders and finishes the job. Longer context gives designers more room, but it also raises user expectations.
The API surface now reflects those expectations. Anthropic's context window docs list 1M-token windows for several Claude models and describe compaction as a strategy for long-running agent work. That pairing matters. Providers can give you more room and still ask you to manage the room.
User impact
Longer context windows change the kinds of tasks users attempt. A software engineer can ask an agent to inspect an architecture across a repository. A lawyer can load contracts and related correspondence. A support team can feed an assistant a long case history without forcing the user to restate the same facts.
Memory compression also changes cost pressure. GPU memory has grown since 2017, but architectural work did more to expand context capacity. Alderson estimates top datacenter GPU memory grew from 16GB to 288GB, an 18x increase, while KV cache memory per token fell about 100x. Researchers and serving teams used math to outrun the hardware curve.
Prices have not fallen in direct proportion to those gains. Providers spent much of the efficiency budget on larger windows: 4,000 tokens became 128,000 tokens, then 1 million tokens. Product teams chose bigger tasks over smaller bills because users value continuity. A coding agent that remembers the whole session can plan, edit, test, and repair with less user intervention.
The trade-off now sits in recall quality. More tokens do not guarantee better answers. Long-context models can miss facts buried in the middle, overvalue recent text, or lose precision as tools and documents crowd the prompt. Developers still need retrieval, ranking, summaries, and state files when accuracy matters.
KV cache compression gives AI products a larger working surface. It lets model providers serve longer sessions, gives app teams cleaner UX choices, and gives users a reason to hand the model bigger jobs. The next gains will come from architectures that keep fixed-size state for more layers while preserving attention quality on tasks that demand exact recall.
Comments
Please log in or register to join the discussion