
Apple researchers have developed LiTo, an AI model that can reconstruct 3D objects with realistic lighting effects from just a single image, outperforming existing methods by capturing view-dependent effects like reflections and highlights.
Apple researchers have developed a breakthrough AI model called LiTo (Surface Light Field Tokenization) that can reconstruct three-dimensional objects with realistic lighting effects from a single image, a capability that could transform everything from augmented reality to 3D content creation.
Understanding the Challenge
Traditional 3D reconstruction methods typically require multiple images taken from different angles to build an accurate model. Even then, capturing realistic lighting effects—like how light reflects off a shiny surface or how highlights shift as you move around an object—has remained a significant challenge. Most existing approaches either focus on geometry alone or predict view-independent diffuse appearance, which means they struggle with realistic view-dependent effects.
The Science Behind LiTo
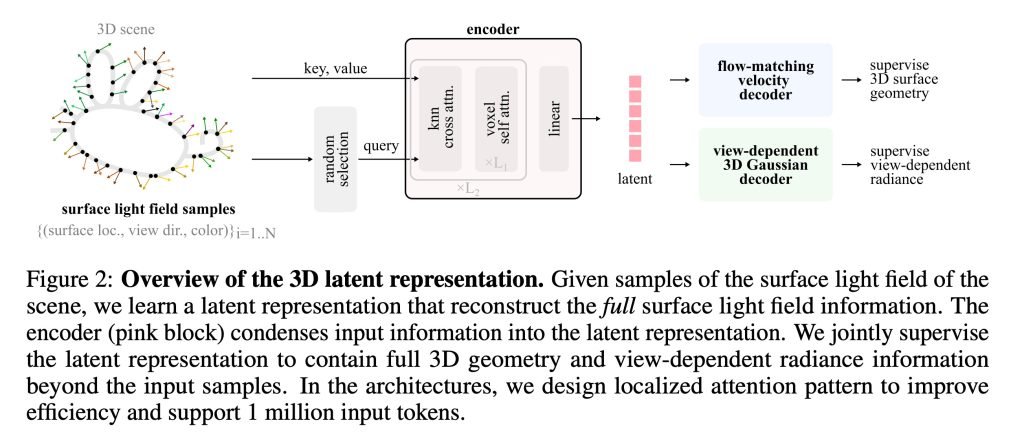
The core innovation in LiTo lies in how it handles latent space representation. While latent space concepts aren't new in machine learning, Apple's approach applies them in a novel way to 3D reconstruction.
As the researchers explain, latent space (or embedding space) involves converting information into numerical representations and organizing these numbers in multi-dimensional space. This allows the system to calculate distances between concepts and estimate probabilities for what should be generated next.
A classic example helps illustrate this: if you take the mathematical representation of "king," subtract "man," and add "woman," you end up in the conceptual region of "queen." This demonstrates how relationships between concepts can be captured mathematically.
How LiTo Works
LiTo's approach is elegantly simple once you understand latent space. The process works in two main stages:
First, an encoder compresses information about the object into a compact latent representation. Rather than storing every visible detail, it learns a condensed mathematical description of the object's shape and how light interacts with its surface.
Then, a decoder reconstructs the full 3D object from that compact representation, generating both the geometry and how lighting effects like reflections and highlights should appear from different viewing angles.
Training the Model
The training process was particularly innovative. The researchers selected thousands of objects rendered from 150 different viewing angles and under 3 different lighting conditions. Instead of feeding all this information directly to the model, they randomly selected small subsets of these samples and compressed them into latent representations.
The decoder was then trained to reconstruct the full object and its appearance under different angles and lighting conditions from just those subsets. Over time, the system learned a latent representation that captured both the object's geometry and how its appearance changes depending on viewing direction.
The Single Image Breakthrough
Once the core model was trained, the researchers developed another model that takes a single image of an object and predicts the latent representation that corresponds to it. The decoder then reconstructs the full 3D object, including how its appearance changes as the viewing angle varies.
This is the key breakthrough—achieving what previously required multiple images from a single photograph.
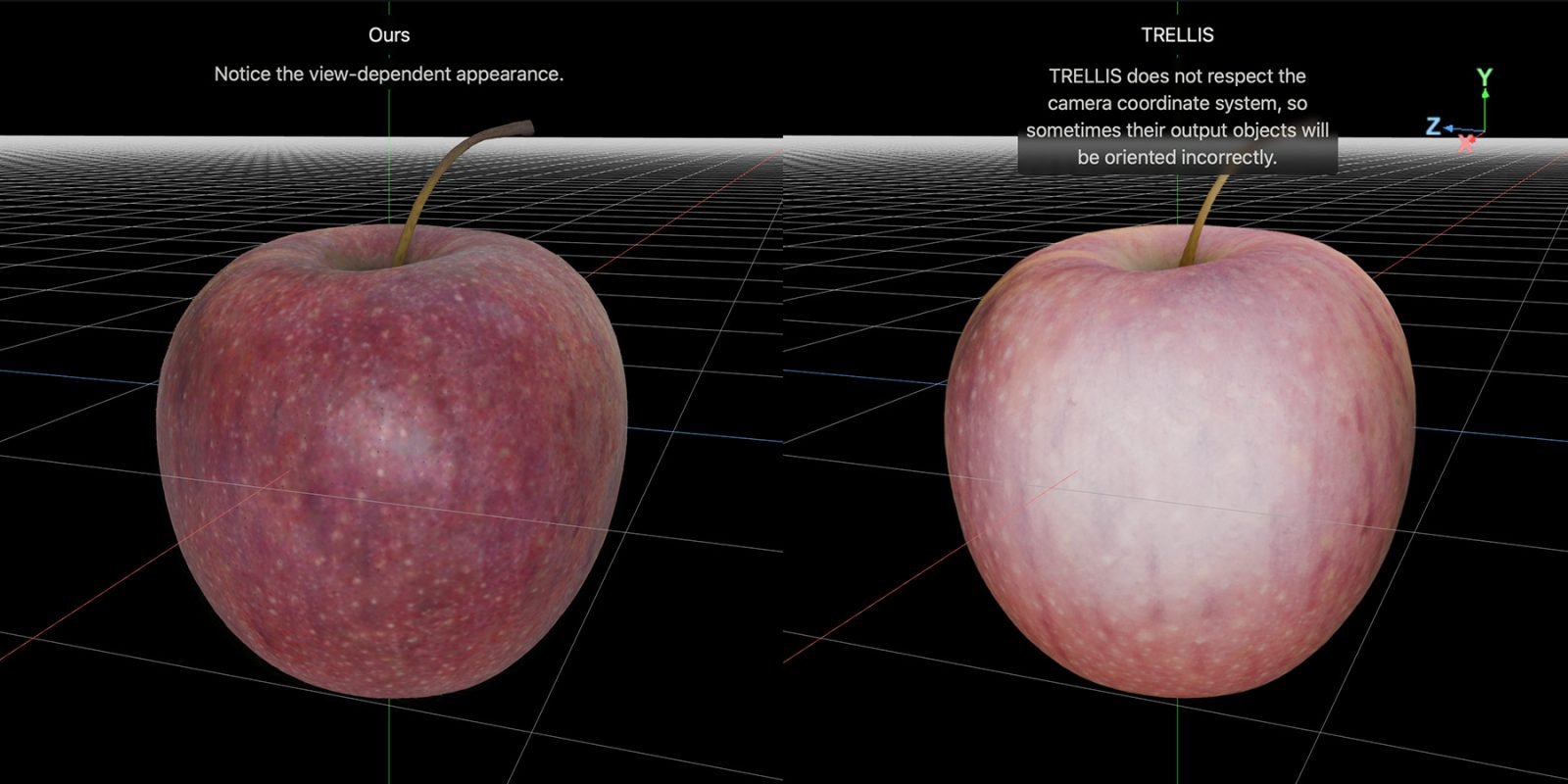
Performance Comparisons
Apple published side-by-side comparisons between LiTo and an existing model called TRELLIS on the project page. The comparisons demonstrate LiTo's superior ability to capture realistic lighting effects, particularly specular highlights and Fresnel reflections under complex lighting conditions.
Potential Applications
While the research paper doesn't detail specific applications, the technology could have significant implications for:
- Augmented and virtual reality content creation
- 3D modeling and design workflows
- E-commerce product visualization
- Gaming asset creation
- Mobile photography enhancements
Technical Details
The full study, titled "LiTo: Surface Light Field Tokenization," provides comprehensive technical details about the methodology. The researchers emphasize that their approach "jointly models object geometry and view-dependent appearance," which sets it apart from previous methods that typically handle these aspects separately.
For those interested in exploring the technology further, Apple has created an interactive project page where you can load side-by-side comparisons between LiTo and TRELLIS reconstructions, providing a hands-on way to appreciate the differences in quality and realism.
This research represents another significant advancement in Apple's AI capabilities, following other recent developments in areas like on-device processing and computer vision. As with much of Apple's research, while immediate commercial applications aren't announced, the technology lays groundwork for future products and features that could enhance the Apple ecosystem.
Comments
Please log in or register to join the discussion