
How we solved weekly JVM crashes by implementing checkpoint-based resource-aware background processing, transforming our approach to scheduling in shared environments.
In distributed systems, background jobs often represent silent killers. They don't fail loudly; they fail by slowly starving everything else until the system collapses. At SAP, we discovered this the hard way: a multi-tenant service processing thousands of tenants would crash every week due to a scheduled job that didn't know when to stop.
The Failure Pattern
Our morning telemetry and cleanup job seemed harmless. Until it overlapped with real traffic. Then, within minutes:
- Heap jumped from 60% → 94%
- GC went into panic mode
- Latency spiked 5×
- Process received OOMKilled
No memory leak. No bad deploy. Just a background job that consumed resources blindly.
The Misguided Assumptions
If you've ever:
- Used
@Scheduledand assumed it's safe - Configured a thread pool and felt "this should handle it"
- Relied on auto-scaling to absorb spikes
You're sitting on the same failure mode we were. The JVM didn't fail. Our scheduling model did.
The Core Problem
We had everything "right":
- Thread pools
- Bounded queues
- Scheduled jobs
- Horizontal scaling
And yet, the system still collapsed. Because none of these answer one critical question: Should this job continue right now?
They control how much work runs. They don't react to when the system is under pressure.
Why Common Solutions Fail
Let's examine the usual approaches:
| Tool | What You Think It Does | What It Actually Misses |
|---|---|---|
| Rate limiting | Controls load | Ignores CPU/memory pressure |
| Bulkheads | Limits concurrency | Still burns resources under stress |
| Thread pools | Caps parallelism | Even 1 thread can OOM you |
| Auto-scaling | Adds capacity | Too slow, too expensive |
| Spring Batch | Manages jobs | No runtime awareness |
All of these control throughput. None of them understand pressure.
The Paradigm Shift
We stopped asking: How do we run this more efficiently? And started asking: Does this job even have permission to run right now?
That one shift changed everything.
The Solution: Checkpoints That Can Say "Stop"
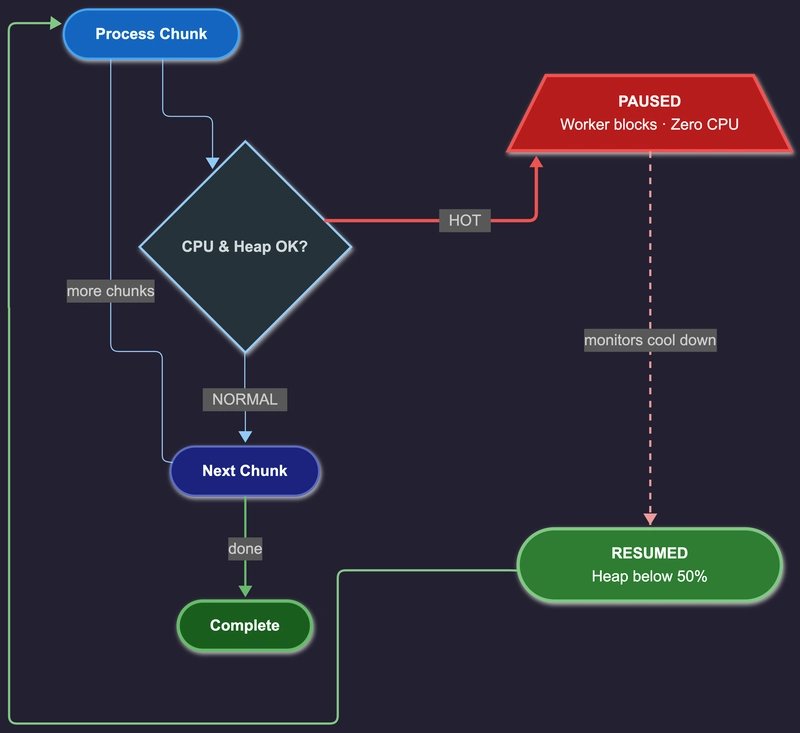
Instead of running a massive job in one go:
- Break it into chunks
- After each chunk, check system health
- If stressed, pause execution
- Resume later from the same point
You don't control execution. You control permission to continue.
Why this works: Java can't pause a thread mid-execution, so you create safe pause points. Like checkpoints in a game: not mid-jump, only at safe boundaries. Workers process one chunk, check pressure, pause if hot, and resume when healthy.
Production Results
Before: background work kept pushing through heap pressure until GC thrash turned into OOM kills. After: work paused at the threshold, traffic stayed healthy, and the job finished later but safely.
Same system. Same workload. 80% fewer OOM incidents.
The Trade-Off Most People Try to Avoid
This is where people hesitate. Your code must become chunkable. No shortcuts. You need:
- Idempotent batches
- Clear boundaries
- Resume-safe execution
If your job is one giant function, this pattern won't save you.
What Most Engineers Get Wrong
They obsess over:
- Chunk size
- Overhead
- Implementation details
Wrong focus. The real question is: Can my background work behave like a good citizen? If not, your system will fail under pressure.
Where This Approach Works
Use this for:
- ETL pipelines
- Batch APIs
- Cleanup jobs
- Migrations
- Scheduled processing
Avoid it for:
- Ultra-low latency paths
- Non-interruptible logic
- Fire-and-forget tasks
The Bigger Insight
The JVM gives you ExecutorService. That abstraction assumes:
- Dedicated machines
- Predictable load
- No contention
That world doesn't exist anymore. Today you have:
- Containers
- Shared CPU
- Hard memory limits
"Just run it" is no longer a valid strategy.
The Hard Truth
Your system didn't crash because Java failed. It crashed because your background jobs were selfish. They consumed resources blindly. They never asked: Is now a good time?
Final Thoughts
Auto-scaling throws hardware at the problem. This approach does something better: It teaches your system restraint. And in distributed systems, restraint is survival.
Implementation
We built this into an open-source library: throttle. Start with the simulator. Watch it pause and resume. Then apply it to one job—not everything.

One last thing: If your background jobs run in the same JVM as your APIs, you don't have a performance problem. You have a priority problem.
Comments
Please log in or register to join the discussion