This article explores how to implement a production-ready Retrieval-Augmented Generation (RAG) pipeline using Azure services and Microsoft Agent Framework. We'll examine the architecture, implementation details, and enterprise considerations for creating accurate, grounded AI systems.
In enterprise AI scenarios, one of the most significant challenges is grounding Large Language Models (LLMs) with real, domain-specific knowledge. Retrieval-Augmented Generation (RAG) has emerged as a critical solution by combining search, embeddings, and AI agents to create more accurate, context-aware responses. This comprehensive guide explores how to build an end-to-end Azure RAG pipeline that addresses these challenges while maintaining enterprise-grade security and scalability.
Understanding the RAG Imperative
Traditional LLMs often struggle with hallucinations and lack access to current, organization-specific information. RAG solves this by connecting LLMs to enterprise knowledge bases, ensuring responses are both accurate and relevant to specific business contexts. The Azure-based solution we'll examine represents a sophisticated implementation of this approach, leveraging Microsoft's cloud ecosystem to create a robust, production-ready RAG system.
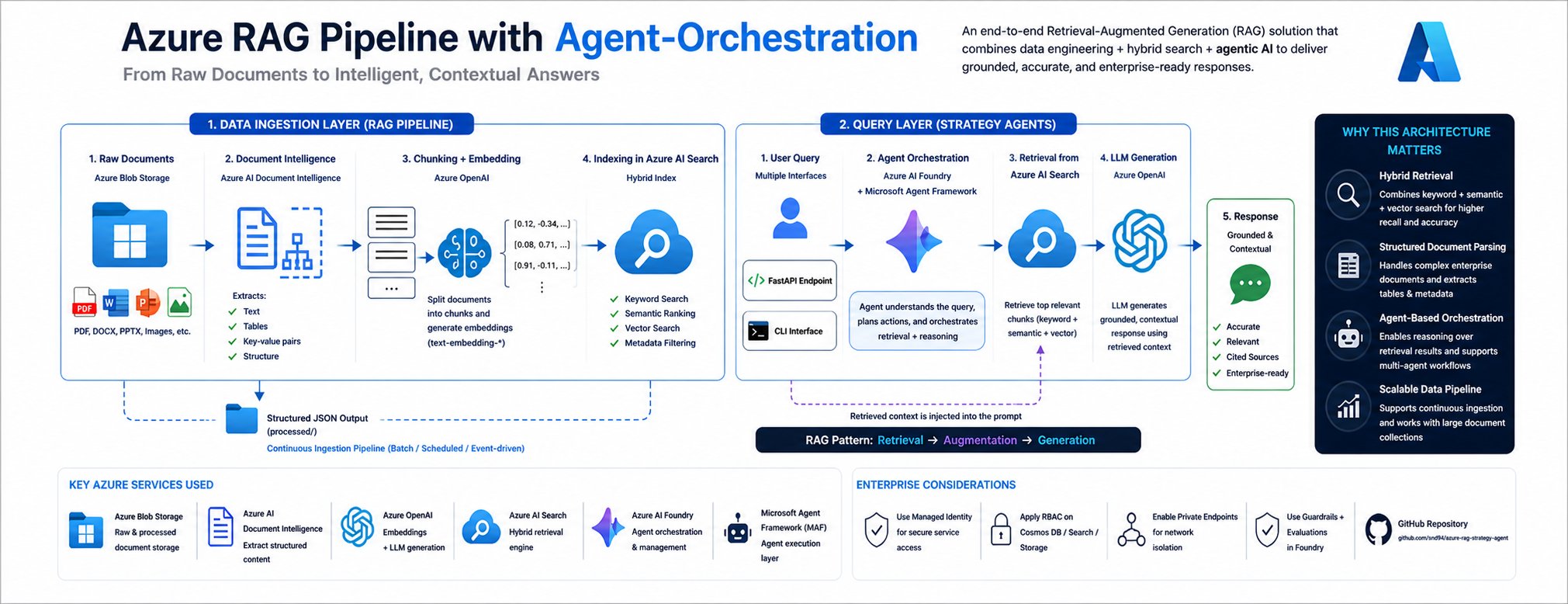
Architecture Overview: The Two-Layer Approach
The solution is structured around two main layers working in concert:
- Data Ingestion Layer (RAG Pipeline): Transforms raw enterprise documents into searchable knowledge
- Query Layer (Strategy Agents): Enables intelligent query answering through agent orchestration
High-Level Architecture
This architecture represents a complete end-to-end RAG pipeline where raw documents are ingested from Azure Blob Storage, processed using Document Intelligence, transformed into embeddings via Azure OpenAI, and indexed in Azure AI Search for hybrid retrieval. A Foundry/MAF-based agent orchestrates query processing by combining user input with relevant search results and generates contextual responses, which are exposed through a FastAPI or CLI interface.
Deep Dive: The Data Ingestion Layer
The data ingestion layer forms the foundation of our RAG system, responsible for transforming unstructured enterprise documents into a searchable knowledge base.
Document Ingestion and Processing
The pipeline begins with raw documents stored in Azure Blob Storage, supporting multiple enterprise formats including PDF, DOCX, PPTX, and images. These documents are then processed through Azure AI Document Intelligence, which extracts:
- Text content
- Structured tables
- Key-value pairs
- Document structure
The extracted information is written as structured JSON back to Blob Storage in a 'processed/' directory, creating an intermediate representation that preserves the document's semantic structure.
Chunking and Embedding Strategy
After extraction, documents undergo intelligent chunking—breaking them into manageable pieces that maintain context while fitting within LLM token limits. Each chunk is then embedded using Azure OpenAI's text-embedding models, converting textual content into numerical representations that capture semantic meaning.
This embedding process is critical for semantic search capabilities, allowing the system to understand conceptual relationships between documents rather than just matching keywords.
Hybrid Indexing in Azure AI Search
The final step in the data ingestion layer involves indexing these processed chunks in Azure AI Search. The solution creates a hybrid index that combines three search approaches:
- Keyword search: Traditional term-based matching for precise queries
- Semantic ranking: Understanding conceptual relationships between terms
- Vector search: Finding content with similar semantic meaning
This hybrid approach significantly improves both recall and precision in information retrieval, addressing the limitations of any single search methodology.
The Query Layer: Agent-Based Orchestration
While the data ingestion layer builds the knowledge foundation, the query layer implements the intelligence that makes the system valuable to end users.
Microsoft Agent Framework (MAF) Integration
The query layer is powered by Microsoft Agent Framework (MAF) agents running on Azure AI Foundry. These agents serve as the intelligent orchestrators that connect user queries with the knowledge base.
When a query arrives—either through a FastAPI endpoint or CLI interface—the MAF agent follows a sophisticated process:
- Query Analysis: Understanding the user's intent and context
- Retrieval: Querying Azure AI Search to find relevant document chunks
- Augmentation: Injecting retrieved information into the LLM prompt
- Generation: Producing a grounded, contextual response
This implementation follows the standard RAG pattern (Retrieval → Augmentation → Generation) but adds agent-based reasoning capabilities that go beyond basic implementations.
Extensible Agent Architecture
The MAF-based approach provides significant advantages over simple RAG implementations:
- Reasoning over retrieval results: Agents can analyze and synthesize information from multiple sources
- Multi-agent workflows: Different agents can handle specialized query types
- Contextual understanding: Agents maintain conversation state and user context
- Error handling: Intelligent fallback when retrieval doesn't provide sufficient information
Key Azure Services in the RAG Ecosystem
This solution leverages several Azure services, each playing a critical role in the RAG pipeline:
| Service | Purpose |
|---|---|
| Azure Blob Storage | Raw and processed document storage |
| Azure AI Document Intelligence | Extract structured content from documents |
| Azure OpenAI | Generate embeddings and power LLM responses |
| Azure AI Search | Hybrid retrieval engine combining keyword, semantic, and vector search |
| Azure AI Foundry | Agent orchestration and deployment platform |
| Microsoft Agent Framework | Agent execution and reasoning layer |
Why This Architecture Matters
This solution goes beyond basic RAG implementations to provide enterprise-grade capabilities:
Hybrid Retrieval Capabilities
By combining keyword, semantic, and vector search, the system achieves superior information retrieval. This hybrid approach addresses the limitations of any single search methodology:
- Keyword search ensures precise matching for technical terms
- Semantic ranking understands conceptual relationships
- Vector search finds content with similar meaning even when terms differ
Together, these methods significantly improve both recall and precision in information retrieval.
Structured Document Processing
Enterprise documents often contain complex structures like tables, forms, and metadata. The Azure AI Document Intelligence component extracts this structured information, preserving relationships between different elements.
This structured approach enables more sophisticated queries that can target specific document features, such as finding all tables containing financial data or extracting key-value pairs from forms.
Agent-Based Orchestration
The Microsoft Agent Framework adds a layer of intelligence beyond simple RAG. Agents can:
- Reason over multiple retrieved documents
- Synthesize information from different sources
- Handle complex, multi-step queries
- Maintain conversation context across interactions
This agent-based approach transforms the system from a simple Q&A tool to an intelligent knowledge assistant capable of handling complex reasoning tasks.
Scalable Data Pipeline
The architecture supports continuous document ingestion and can handle large document collections. This scalability is essential for enterprise environments where knowledge bases grow constantly and require real-time updates.
Enterprise Considerations
Implementing this solution in an enterprise environment requires attention to several critical factors:
Security and Governance
- Managed Identity: Use Azure's managed identity service for secure service-to-service authentication
- Role-Based Access Control (RBAC): Implement granular permissions on Cosmos DB, Search, and Storage
- Private Endpoints: Enable private endpoints for network isolation and enhanced security
- Data Encryption: Ensure data encryption at rest and in transit
Quality and Safety
- Guardrails: Implement Azure AI Content Safety to prevent harmful outputs
- Evaluation Frameworks: Establish metrics for evaluating response quality and relevance
- Monitoring: Deploy comprehensive monitoring for system performance and accuracy
Operational Excellence
- CI/CD Pipeline: Implement automated testing and deployment
- Cost Management: Monitor and optimize resource usage to control costs
- Disaster Recovery: Establish backup and recovery procedures for critical components
Implementation Flow: From Documents to Responses
The complete end-to-end flow follows these steps:
- Document Ingestion: Upload documents to Azure Blob Storage
- Content Extraction: Process documents with Azure AI Document Intelligence
- Structuring: Convert extracted content to JSON format
- Chunking: Split documents into manageable pieces
- Embedding: Generate vector representations using Azure OpenAI
- Indexing: Store processed chunks in Azure AI Search
- Query Processing: Route user queries through MAF agents
- Retrieval: Find relevant document chunks
- Response Generation: Combine retrieved information with user query
- Output: Return contextual response through API or CLI
Practical Implementation Guidance
For organizations looking to implement this solution, consider these recommendations:
Start Small, Scale Gradually
Begin with a focused knowledge domain and document type before expanding to enterprise-wide implementation. This phased approach allows for refinement of the pipeline and tuning of the retrieval mechanisms.
Optimize Chunking Strategy
The chunking approach significantly impacts retrieval effectiveness. Experiment with different chunk sizes and strategies to find the optimal balance between context preservation and computational efficiency.
Fine-Tune Embedding Models
While the default Azure OpenAI embeddings provide good performance, consider fine-tuning for specific domains or terminology to improve semantic understanding.
Implement Evaluation Metrics
Establish clear metrics for evaluating system performance, including:
- Response accuracy
- Retrieval relevance
- User satisfaction
- System latency
These metrics should be monitored continuously and used to guide system improvements.
Conclusion: The Future of Enterprise Knowledge Systems
This Azure-based RAG architecture represents a significant step toward creating enterprise AI systems that are accurate, grounded, and extensible. By combining Azure's powerful services with the Microsoft Agent Framework, organizations can build knowledge systems that truly understand their specific domain and context.
The solution addresses critical enterprise requirements including security, scalability, and extensibility while providing the accuracy and reliability needed for production deployment. As organizations continue to adopt AI technologies, this approach offers a practical path to creating value from enterprise knowledge without falling prey to the hallucinations and inaccuracies that plague ungrounded LLMs.
For organizations looking to implement this solution, the provided GitHub repository offers a starting point for building a production-ready RAG system. The combination of data engineering best practices and AI orchestration creates a foundation that can evolve with organizational needs and technological advancements.
For further information on the components used in this solution, refer to the Microsoft Learn Documentation:
- Azure AI Search documentation
- Document Intelligence documentation
- Microsoft Agent Framework Overview
- What is Microsoft Foundry?
The implementation demonstrates how Azure's integrated services can be combined to solve complex enterprise challenges, providing a blueprint for building sophisticated AI systems that deliver real business value.
Comments
Please log in or register to join the discussion