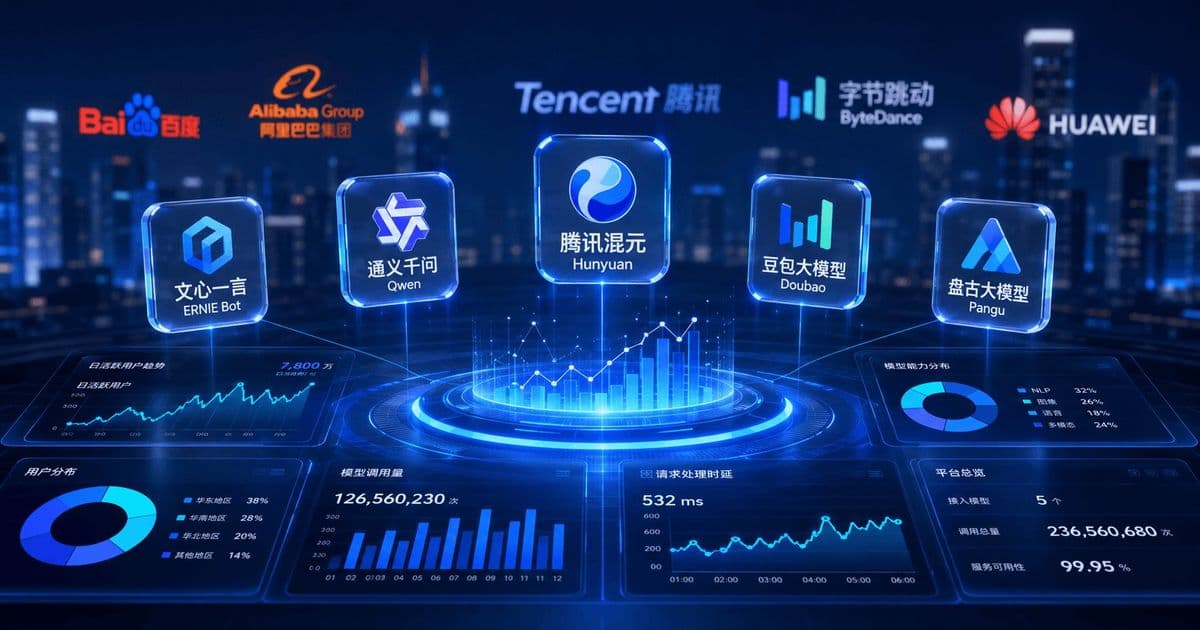
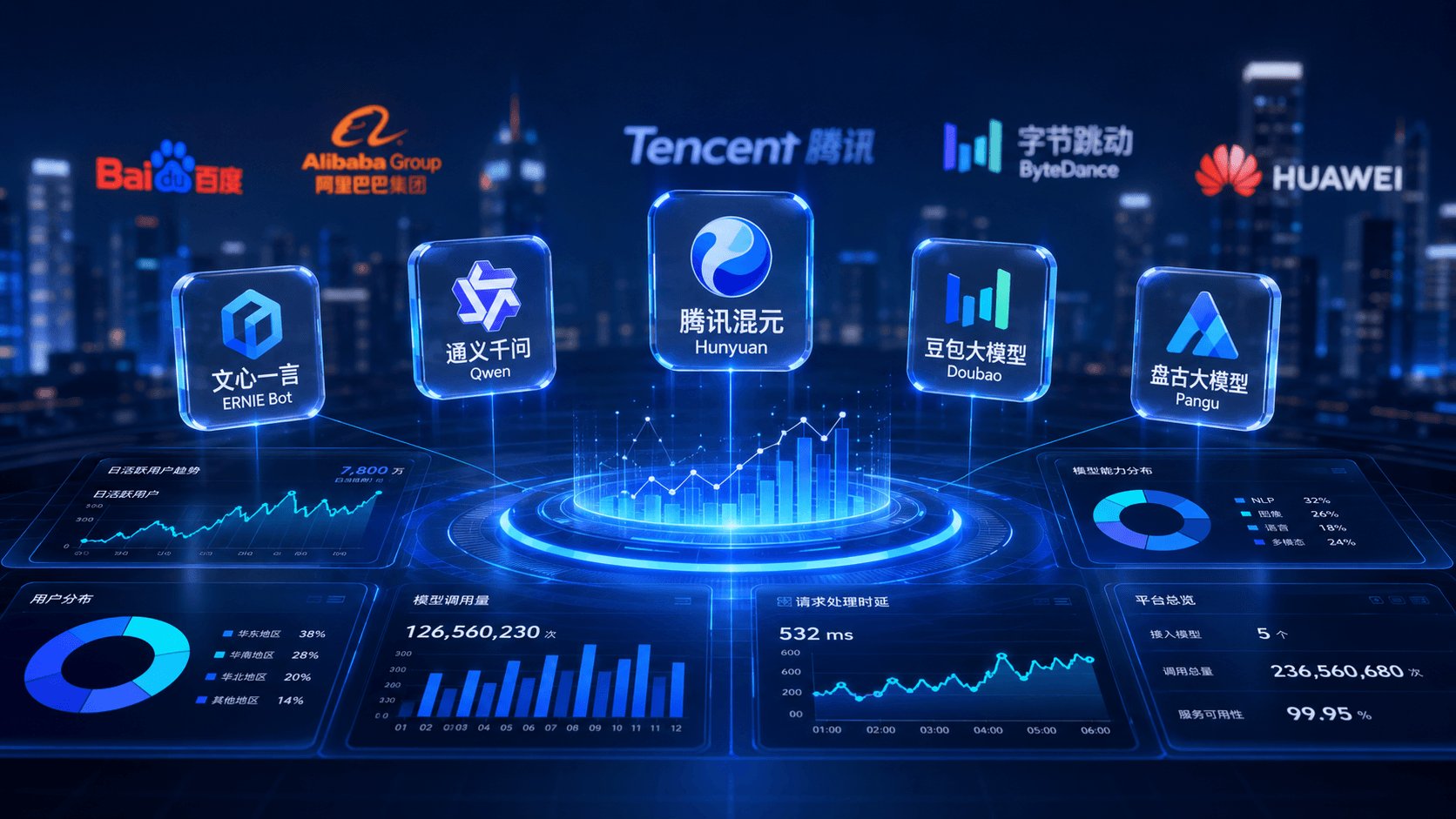
DeepSeek V4 and Kimi K2.6 top open-source leaderboards at a fraction of U.S. API prices, but analysts argue benchmark wins mean little. The commercially decisive markets are coding and office productivity, and Anthropic already shows why.
Chinese large language model developers have closed the capability gap that defined the field two years ago. Models like DeepSeek V4 and Kimi K2.6 sit at or near the top of open-source leaderboards, and their API pricing undercuts U.S. competitors by wide margins. On the metrics the industry has trained itself to watch, China has caught up.
A recent analysis circulating among Chinese AI firms argues that this is precisely the wrong thing to celebrate. Benchmark parity, the argument goes, is a distraction from the only question that determines whether any of these companies survive: can they turn model quality into products people pay for every day? The two markets large enough to support that ambition are coding and office productivity, and both are being contested right now.
What's actually being claimed
The claim is not that Chinese models are bad. It is that leaderboard position and revenue have decoupled. The often-cited example is Anthropic, which serves roughly one-seventh of OpenAI's user base yet reportedly captures close to a third of global LLM revenue. The gap is explained by where Anthropic's usage concentrates: Claude has become a default tool for software development, and developers pay for tools that measurably speed up their work.
That distinction matters because benchmark scores measure capability in isolation, while revenue measures whether a capability is wired into a workflow someone refuses to give up. A model that scores two points higher on a reasoning benchmark wins headlines. A model that shaves an hour off a programmer's day wins a subscription that renews.
Why coding and office work, specifically
The reasoning is grounded in where economic value already sits. Six decades of computing have produced two enormous categories of knowledge work: writing and manipulating code, and producing documents, spreadsheets, contracts, and analyses. Programmers, lawyers, editors, accountants, analysts, and investors all live inside these tools. An AI that makes that work substantially faster attaches itself to budgets that already exist, rather than trying to invent a new spending category.
The productivity numbers, when they hold up, are not incremental. A developer with a competent coding assistant ships features faster, mostly by compressing the boilerplate, search, and debugging cycles that fill a working day. A legal assistant reviewing contracts can triage a far larger volume when the model handles a first pass. The pattern repeats across document-heavy professions. These are workflow changes, not feature additions, and that stickiness is the whole point. Once a team reorganizes around an assistant, switching away carries a real cost.
China enters this contest with genuine structural advantages. It has the world's largest population of software developers, estimated at more than seven million, plus tens of millions of knowledge workers across industries. Domestic models are now good enough to serve them. The raw demand and the supply of capable models both exist inside the same market.
The limitations of the optimistic case
The analysis is more warning than victory lap, and the cautions deserve equal weight. Habit and distribution, not model quality, decide these markets, and habits are forming now. Anthropic and its U.S. peers are already accumulating users, brand trust, and the feedback loop where heavy usage produces better products that attract more usage. A model that is technically equal but arrives after that loop has spun up faces an uphill fight regardless of its scores.
The historical analogies the analysis reaches for are worth taking seriously, even if they are familiar. Wang Laboratories built a dominant word processing business and then declined to make its machines IBM-compatible as the PC standard formed around it. Xerox PARC produced the graphical user interface, the mouse, and networked workstations, and watched others commercialize all of it. In both cases the technology was not the bottleneck. The business model and the willingness to meet the market where it was going were.
There is also a gap the analysis glosses over. Building a coding product that developers trust is not the same as topping a coding benchmark. It requires reliable tool integration, low latency, editor and IDE support, sensible handling of large codebases, and predictable behavior under real conditions. Office productivity carries its own demands around data privacy, document fidelity, and integration with entrenched suites. None of that shows up in a leaderboard number, and all of it takes sustained product engineering rather than another training run.
What changes
The practical takeaway for Chinese LLM firms is a reallocation of attention. Continuing to optimize for benchmark rankings produces diminishing commercial returns once a model is already competitive. The harder and more valuable work is turning that model into coding tools and office assistants that fit how people actually work, then getting them adopted before usage habits calcify around foreign incumbents.
The framing the analyst uses is blunt: the engine is just the engine, and the car is the product. Users buy cars, not engines. China has built strong engines. Whether it builds the cars, and ships them before the habit-forming window closes, is the open question. For developers and buyers watching from outside, the useful signal over the next year will not be the next leaderboard update. It will be which of these models shows up inside tools people use without thinking about which model is underneath.
Comments
Please log in or register to join the discussion