When you run a SELECT query, it's easy to imagine rows being read straight from disk like a spreadsheet. But the actual mechanics of how relational databases store data on disk involve a clever bi-directional page layout that solves real performance problems. Understanding this architecture explains why certain operations are fast, why others grind to a halt, and why your maintenance scripts exist in the first place.

When you run a SELECT * FROM users query, it's easy to picture a database as a massive, perfectly organized Excel spreadsheet living on a hard drive. But if you actually look at how relational databases hold and represent data on disk, that mental model falls apart quickly.
If databases simply stacked rows on top of each other, changing a user's bio from ten characters to ten thousand characters would be an absolute nightmare. The database would have to shift every single subsequent row physically down the disk just to make room. Instead, database engines handle this using a highly optimized internal architecture. Let's break down exactly how it works.
What is a database page?
A database page is the smallest unit of data storage and transfer managed by a relational database engine. Typically about 8 kilobytes in size, a single page acts as a fixed-size container that holds multiple rows of data alongside the metadata needed to manage them.
When you ask the database for a single row, the disk doesn't just read that one specific row. Hard drives and SSDs are optimized for block storage. The database reads the entire 8KB page into memory, processes what you asked for, and returns it. Because a single page contains many rows, the way those rows are arranged inside the page dictates how fast your application can read and write data.
The page size itself represents a trade-off. Larger pages mean more rows per read operation, which improves sequential scan performance. But larger pages also mean more wasted I/O when you only need a single row, and more data to rewrite when any row on the page changes. Most traditional relational databases, like PostgreSQL and SQL Server, use an 8KB page size by default. MySQL's InnoDB engine defaults to 16KB, a choice that reflects its historical optimization for read-heavy workloads on spinning disks.
Why do databases use bi-directional page layouts instead of sequential rows?
Storing rows sequentially from top to bottom causes massive performance bottlenecks during data updates. If a specific row's data size increases, the database would have to physically shift every single subsequent row downward to make room, resulting in a cascade of slow, expensive disk writes.
Consider the implications at scale. In a table with millions of rows spread across thousands of pages, updating a single row's variable-length field could trigger a chain reaction of page splits and data movement. On a busy system handling thousands of transactions per second, this approach would create I/O contention that brings the entire system to its knees.
Databases avoid this problem by completely separating the location of the row from the data of the row.
How does the internal layout of a database page work?
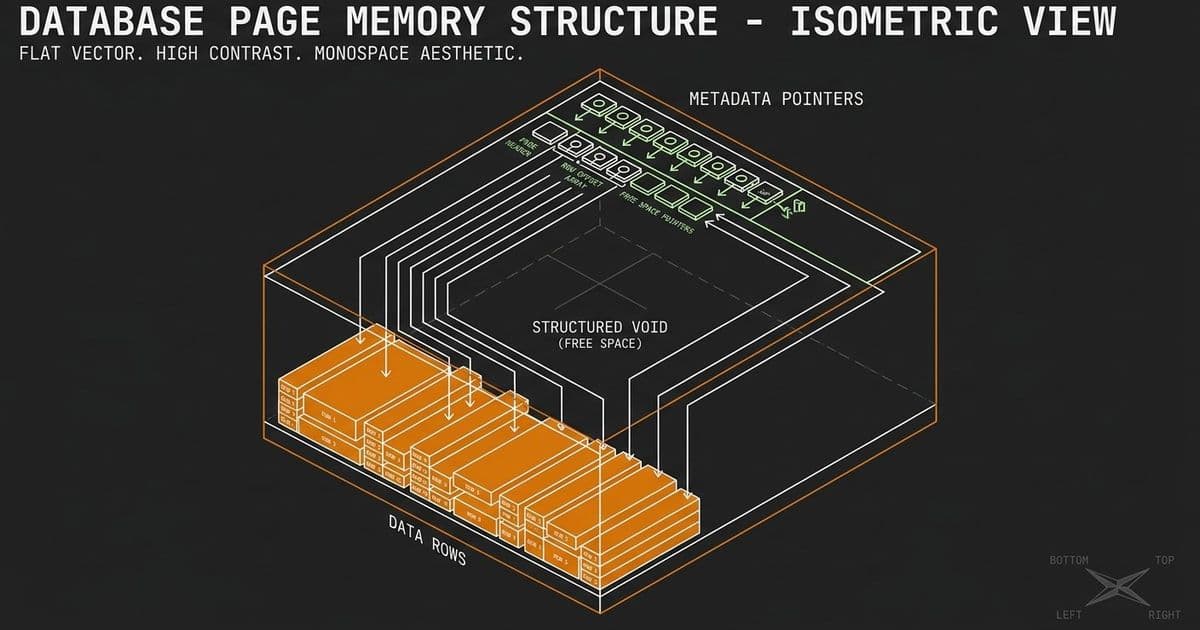
Pages use a bi-directional architecture where a directory of pointers grows downwards from the top, while the variable-length row data grows upwards from the bottom. When data changes, the database simply writes the new data into the empty middle space and updates the tiny pointer at the top.
Here is exactly how a standard database page is structured:
| Page Section | Location | Purpose |
|---|---|---|
| Page Header | Very Top | Stores a few bytes of fixed-length metadata (page ID, amount of free space) |
| Slot Array (Pointers) | Grows Downwards | Holds tiny pointers detailing the exact memory locations where each row's data lives |
| Free Space | Middle | The empty gap between the pointers and the data, waiting to be used |
| Row Data | Grows Upwards | The actual variable-length data of your rows, filling in from the bottom of the page |

Because of this layout, if you query for a specific row, the database reads the top of the page, finds the pointer, and instantly jumps to those specific memory locations. If you update that row to be much larger, the database doesn't shift anyone else around. It simply writes the new, larger data into the free space growing upward from the bottom, and updates the pointer at the top to point to the new location.
This design has profound implications for concurrency. Multiple transactions can read different rows from the same page simultaneously without blocking each other, since reads don't require locks on the page structure itself. The slot array provides a stable indexing layer that doesn't change when row data moves around within the page.
What causes database page fragmentation?
Fragmentation occurs when rows are updated or deleted, leaving behind abandoned "holes" of empty space within the data section of the page. Because the database leaves the old data where it was and writes the new updated data elsewhere in the page, this wasted space eventually requires a process called compaction to squeeze the active data back together.
If you constantly update data in your application, your pages will eventually run out of free space in the middle. The database engine has to periodically step in, sweep away the abandoned ghost records, and reorganize the page layout to reclaim that space.
This is where Multi-Version Concurrency Control (MVCC) adds complexity. In MVCC-based systems like PostgreSQL, updating a row doesn't overwrite the old version. Instead, the database writes a new version of the row into the page's free space and marks the old version as obsolete. The old version remains visible to transactions that started before the update, providing snapshot isolation without locking. But this means every update gradually fills pages with dead tuples that consume space until a vacuum process reclaims it.
The practical consequence: your VACUUM schedule isn't just busywork. It's a fundamental requirement of the storage architecture. Without regular vacuuming, tables bloat, sequential scans read more pages than necessary, and performance degrades in ways that are difficult to diagnose without understanding the underlying page mechanics.
The trade-offs engineers face
The bi-directional page layout solves the variable-length row problem elegantly, but it introduces its own set of trade-offs:
Write amplification: When a page fills up, the database must split it into two pages, moving roughly half the rows to a new page. This means a single row insert can trigger writes to multiple pages, plus updates to index structures that point to those pages. On SSDs, this accelerates wear. On spinning disks, it causes seek storms.
Page splits under load: Hot pages that receive frequent inserts become contention points. In B-tree indexes, this manifests as latch contention where multiple threads compete for access to the same page. Modern databases use techniques like B-link trees and insert buffering to mitigate this, but the fundamental constraint remains.
Compression challenges: Fixed-size pages with variable internal layouts don't compress as efficiently as sequential data. Databases that prioritize compression, like column-oriented systems, often abandon the traditional page model entirely in favor of encoding schemes that exploit data patterns across entire columns.
Cache management: The database buffer pool must track which pages are in memory and which are on disk. The page becomes the unit of cache eviction, meaning a query that touches a cold page forces a disk read even if the specific row needed was recently accessed. This is why index-only scans and covering indexes matter so much for performance.
How different databases handle this

The page-based architecture varies significantly across database engines:
PostgreSQL uses a straightforward 8KB page layout with a fixed-size page header and a line pointer array. Its MVCC implementation writes new tuple versions directly into pages, making vacuuming essential. The PostgreSQL documentation provides detailed specifications of the page format.
MySQL InnoDB uses 16KB pages organized into a more complex structure with multiple record formats. Its clustered index design means the primary key determines the physical ordering of rows within pages, which has significant implications for insert patterns and range queries.
SQL Server employs a sophisticated page architecture with行偏移数组 (row offset arrays) and supports multiple page types for different purposes (data pages, index pages, text/image pages). Its allocation unit system allows different row versions to coexist on the same page.
MongoDB takes a different approach with its WiredTiger storage engine, using B-tree nodes as its fundamental unit rather than fixed-size pages. This allows more flexible space management but introduces its own trade-offs around fragmentation and concurrency.
The common thread across all these systems: the fundamental tension between write performance, read performance, and space efficiency. Every design choice in page layout reflects a bet about which workload pattern matters most for the intended use case.
Understanding these internals isn't academic. When your application hits a performance ceiling, the difference between a query that touches one page and one that touches a thousand pages is the difference between sub-millisecond response times and seconds of latency. The page is where the rubber meets the road in database performance, and knowing how it works gives you the vocabulary to diagnose problems and the intuition to design schemas that work with the storage engine instead of against it.
Comments
Please log in or register to join the discussion