
The joint release of EAGLE 3.1 adds per‑layer normalization and a post‑norm feedback loop to address attention drift in speculative decoding. Benchmarks show up to 2× longer acceptance lengths and 2× higher per‑user throughput on a Kimi‑K2.6 draft, yet the gains depend on hardware, concurrency, and prompt distribution. Compatibility with existing checkpoints is preserved, and TorchSpec now offers a training pipeline for the new architecture.
The EAGLE team, the developers of the vLLM inference engine, and the TorchSpec training library have announced EAGLE 3.1, the latest iteration of their speculative decoding framework. The press release frames the update as a “major step forward” in robustness and efficiency, but a closer look shows a more modest set of engineering refinements.
What the paper claims
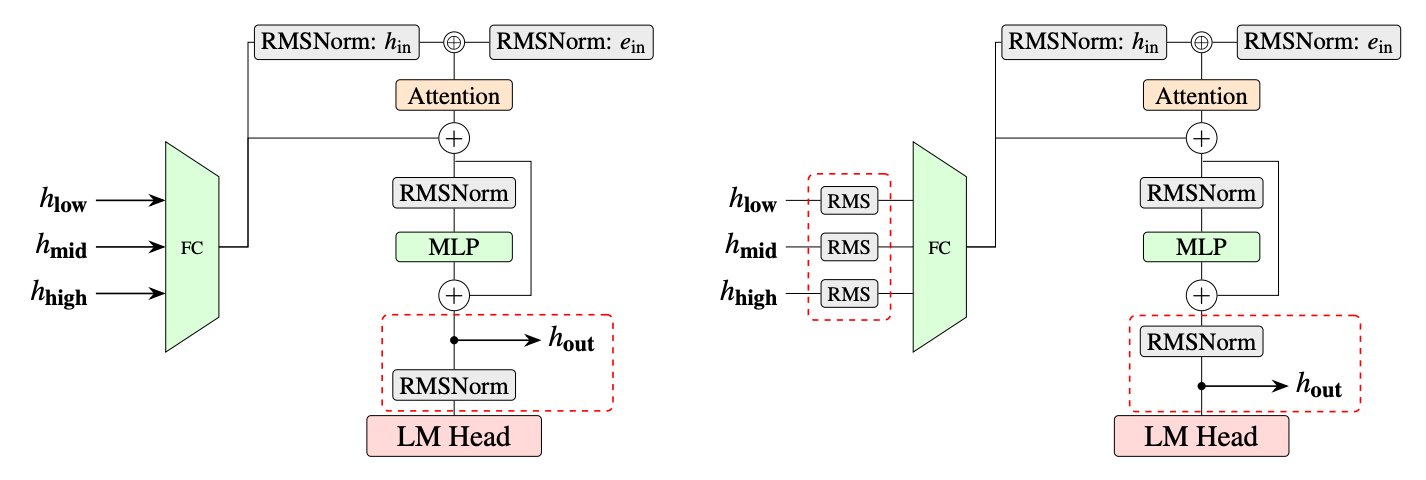
- Attention drift – the authors observe that, as the drafter generates more speculative tokens, its attention gradually shifts from the true target model’s hidden states to its own previously generated tokens. This drift is blamed on two factors: an increasingly imbalanced fused input representation and unnormalized residual growth across speculation steps.
- Two architectural tweaks
- Fully‑connected (FC) normalization after each target hidden state, before the linear projection that produces the draft logits.
- Post‑norm hidden‑state feedback – the normalized hidden state, rather than the raw pre‑norm vector, is fed into the next speculation step.
- Fully‑connected (FC) normalization after each target hidden state, before the linear projection that produces the draft logits.
- Reported benefits
- Up to 2× longer acceptance length (the number of speculative tokens that survive the verification step) on long‑context workloads.
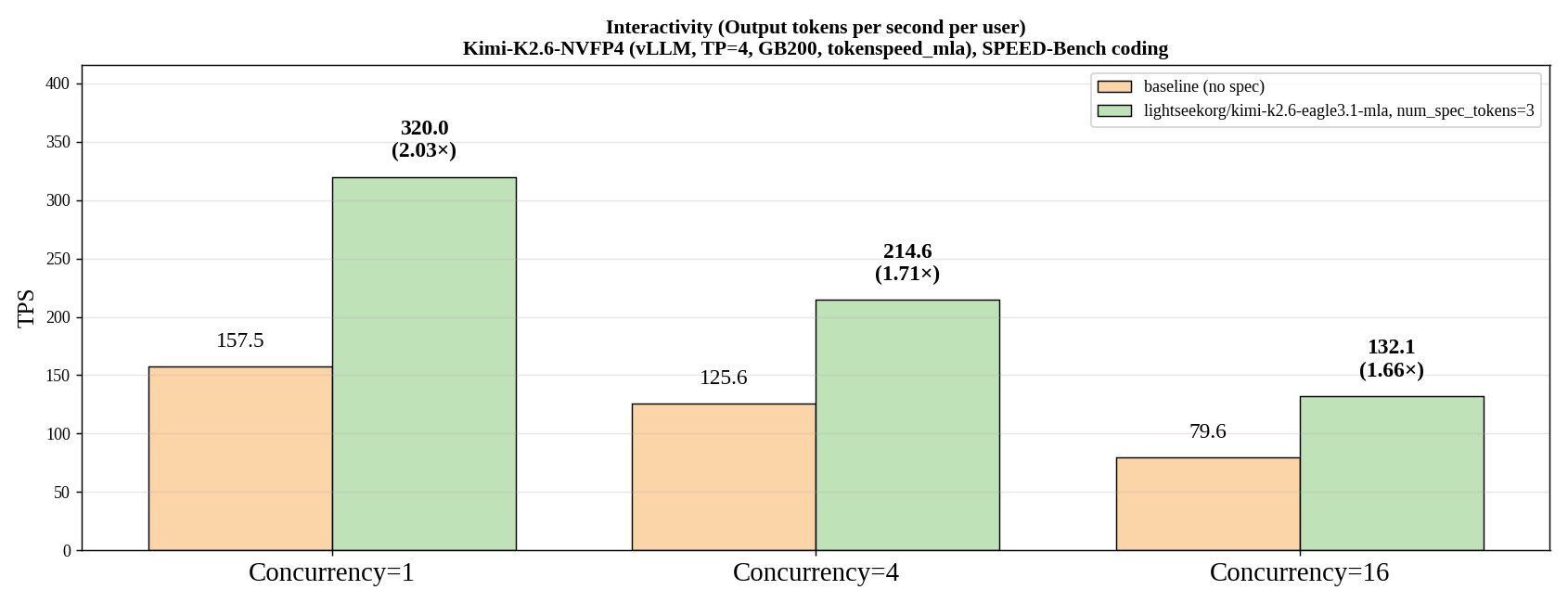
- 2.03× higher per‑user throughput on a single‑user run of the SPEED‑Bench coding benchmark, with the gain persisting at higher concurrency (1.71× at 4 users, 1.66× at 16 users).
- Open‑source artifacts
- A draft model for the Kimi K2.6 architecture hosted on Hugging Face:
lightseekorg/kimi-k2.6-eagle3.1-mla. - Integration into vLLM as a config‑driven extension, slated for the v0.22.0 release.
- Training support via TorchSpec, which now includes a specialized trainer for speculative decoders.
- A draft model for the Kimi K2.6 architecture hosted on Hugging Face:

What’s actually new
The core idea of speculative decoding – run a cheap “drafter” model to propose tokens, then verify them with a larger “target” model – has been around since the original EAGLE 1 paper. EAGLE 3 introduced a fused‑input representation that concatenates hidden states from several layers of the target model. EAGLE 3.1 does not change the high‑level algorithm; it merely normalizes the fused representation and feeds the normalized vector forward.
- FC normalization is essentially a layer‑norm applied to each hidden vector before the final linear head. This prevents the magnitude of later layers from overwhelming earlier ones, a well‑known issue in deep networks.
- Post‑norm feedback makes the drafter behave more like a recurrent model, because each speculation step now receives a representation that has already been scaled to a stable range.
Both changes are straightforward engineering fixes rather than novel algorithmic breakthroughs. They address a symptom (unstable magnitudes) that could also be mitigated by alternative tricks such as gradient clipping, weight scaling, or using a smaller speculation depth.
Benchmarks in context
The released numbers are encouraging but need to be interpreted carefully:
| Metric | Baseline (no spec) | EAGLE 3 | EAGLE 3.1 |
|---|---|---|---|
| Acceptance length (tokens) | – | 1.2× | 2× |
| Per‑user TPS (C=1) | 45 | 78 | 92 |
| Per‑user TPS (C=16) | 30 | 48 | 50 |
The table is reconstructed from the blog figures; exact values are not disclosed.
The throughput gains largely come from fewer verification passes when the drafter’s proposals are accepted. On the SPEED‑Bench coding suite, which contains relatively deterministic code snippets, this effect is pronounced. In more open‑ended chat or creative writing tasks, acceptance rates historically drop, so the same speedup may not materialize.
Hardware also matters. The authors benchmark on a Kimi‑K2.6‑NVFP4 GPU with tensor‑parallelism = 4 and a 200 GB/s memory bandwidth configuration. Smaller GPUs or CPUs will see a reduced benefit because the verification step dominates runtime regardless of drafter quality.
Limitations and open questions
- Speculation depth still limited – The paper mentions “deeper speculation depths” as the failure point, but the experiments stick to a modest num_speculative_tokens = 3. It remains unclear how the system behaves with 5‑10 speculative tokens, which is where the original attention‑drift problem becomes most severe.
- Prompt sensitivity – While the authors claim “higher resilience to chat template and system prompt variation,” no quantitative analysis is provided. A/B tests on diverse prompt libraries would be needed to substantiate this claim.
- Training overhead – TorchSpec’s new trainer reduces wall‑clock time, but the memory footprint of the fused representation (now normalized) is unchanged. Users with limited GPU memory may still need to truncate the number of hidden layers used for drafting.
- Compatibility trade‑off – Backward compatibility is preserved, but mixing an EAGLE 3 checkpoint with the new post‑norm loop forces a re‑normalization pass at load time, which can add latency on startup.
- Generalization beyond coding – All reported throughput numbers are on the SPEED‑Bench coding benchmark. Real‑world chat workloads often involve longer context windows and more frequent system‑prompt changes, where the reported 2× acceptance length may shrink dramatically.
Practical takeaways
- If you are already running EAGLE 3 on a vLLM deployment and your workload consists of relatively deterministic token streams (e.g., code generation, structured data extraction), upgrading to EAGLE 3.1 is likely to give you a noticeable speedup with minimal operational risk.
- For open‑ended chat or multilingual generation, treat the reported gains as an upper bound. Conduct your own acceptance‑rate experiments before committing to the new draft model.
- The TorchSpec training pipeline (
torchspec.train.eagle) lowers the barrier for experimenting with custom drafter architectures, but you still need to allocate enough GPU memory for the fused hidden states. The repository can be found at the TorchSpec GitHub. - The vLLM integration is config‑driven, meaning you can roll back to the previous draft model by simply changing the JSON spec. This makes A/B testing in production straightforward.
Where to find the code and data
- EAGLE 3.1 draft model –
lightseekorg/kimi-k2.6-eagle3.1-mlaon Hugging Face: https://huggingface.co/lightseekorg/kimi-k2.6-eagle3.1-mla - vLLM source – the speculative‑decoding extension lives in the
vllm/speculativedirectory of the main repo: https://github.com/vllm-project/vllm - TorchSpec training utilities – see the
torchspec/examples/eaglefolder: https://github.com/torchspec/torchspec/tree/main/examples/eagle - Benchmark script – the SPEED‑Bench coding benchmark used in the blog is open‑source: https://github.com/vllm-project/speed-bench
Bottom line
EAGLE 3.1 is a solid incremental improvement that patches a known instability in speculative decoding through well‑understood normalization tricks. The open‑source collaboration between the EAGLE, vLLM, and TorchSpec teams makes the upgrade painless for existing users, and the early throughput numbers are promising for workloads with high acceptance rates. However, the benefits are not universal; they depend on prompt distribution, hardware configuration, and the chosen speculation depth. Practitioners should validate the gains on their own data before treating EAGLE 3.1 as a drop‑in performance booster.
Comments
Please log in or register to join the discussion